 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttendAffectNet: Self-Attention based Networks for Predicting Affective Responses from Movies
Oct 21, 2020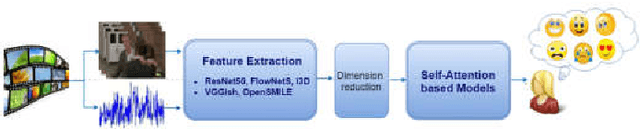

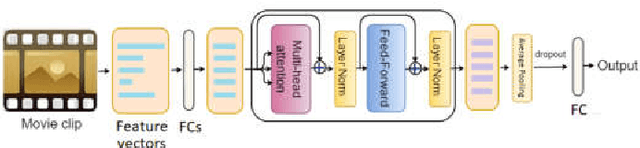
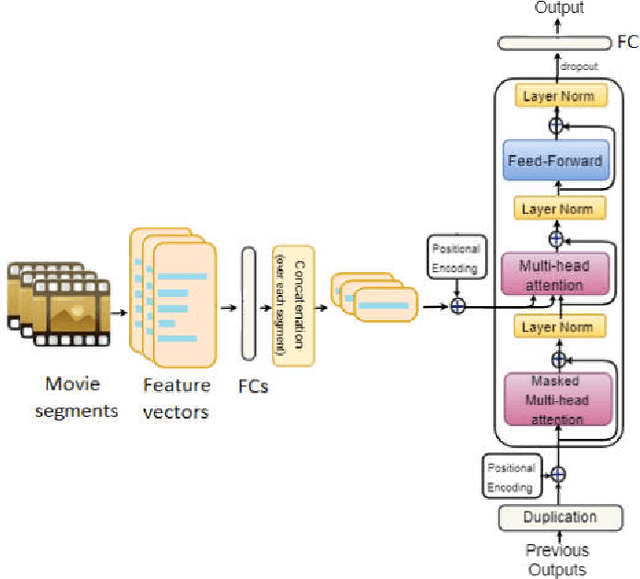
In this work, we propose different variants of the self-attention based network for emotion prediction from movies, which we call AttendAffectNet. We take both audio and video into account and incorporate the relation among multiple modalities by applying self-attention mechanism in a novel manner into the extracted features for emotion prediction. We compare it to the typically temporal integration of the self-attention based model, which in our case, allows to capture the relation of temporal representations of the movie while considering the sequential dependencies of emotion responses. We demonstrate the effectiveness of our proposed architectures on the extended COGNIMUSE dataset [1], [2] and the MediaEval 2016 Emotional Impact of Movies Task [3], which consist of movies with emotion annotations. Our results show that applying the self-attention mechanism on the different audio-visual features, rather than in the time domain, is more effective for emotion prediction. Our approach is also proven to outperform many state-ofthe-art models for emotion prediction. The code to reproduce our results with the models' implementation is available at: https://github.com/ivyha010/AttendAffectNet.
Multimodal Deep Models for Predicting Affective Responses Evoked by Movies
Sep 17, 2019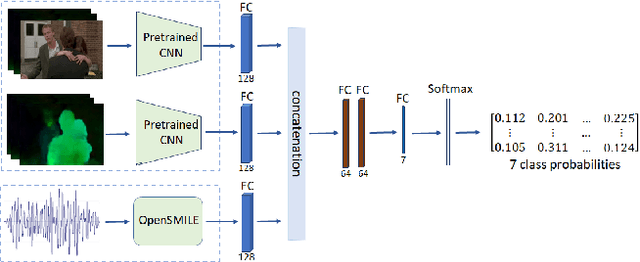
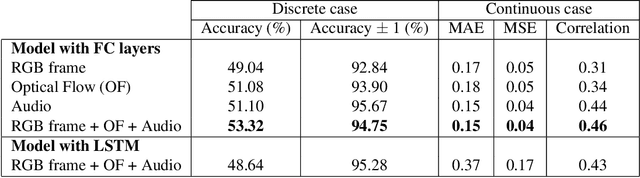
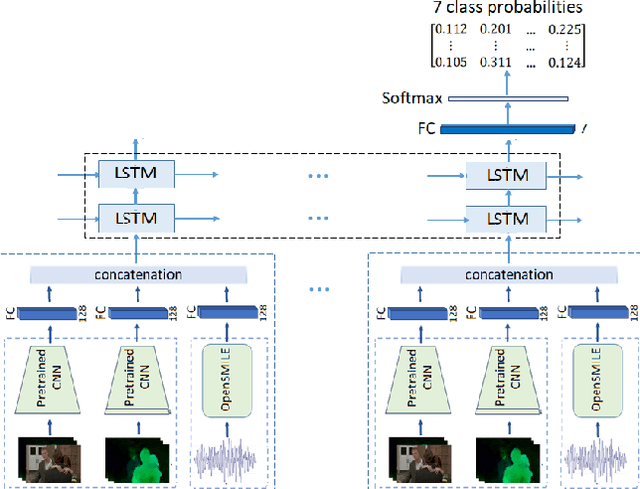
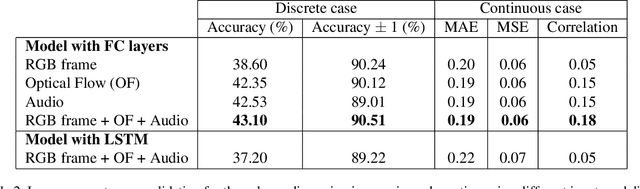
The goal of this study is to develop and analyze multimodal models for predicting experienced affective responses of viewers watching movie clips. We develop hybrid multimodal prediction models based on both the video and audio of the clips. For the video content, we hypothesize that both image content and motion are crucial features for evoked emotion prediction. To capture such information, we extract features from RGB frames and optical flow using pre-trained neural networks. For the audio model, we compute an enhanced set of low-level descriptors including intensity, loudness, cepstrum, linear predictor coefficients, pitch and voice quality. Both visual and audio features are then concatenated to create audio-visual features, which are used to predict the evoked emotion. To classify the movie clips into the corresponding affective response categories, we propose two approaches based on deep neural network models. The first one is based on fully connected layers without memory on the time component, the second incorporates the sequential dependency with a long short-term memory recurrent neural network (LSTM). We perform a thorough analysis of the importance of each feature set. Our experiments reveal that in our set-up, predicting emotions at each time step independently gives slightly better accuracy performance than with the LSTM. Interestingly, we also observe that the optical flow is more informative than the RGB in videos, and overall, models using audio features are more accurate than those based on video features when making the final prediction of evoked emotions.
* 10 pages, 7 figures, Preprint accepted for publication in the Proceedings of the 2nd International Workshop on Computer Vision for Physiological Measurement as part of ICCV. Seoul, South Korea. 2019