 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossMuSim: A Cross-Modal Framework for Music Similarity Retrieval with LLM-Powered Text Description Sourcing and Mining
Mar 29, 2025Music similarity retrieval is fundamental for managing and exploring relevant content from large collections in streaming platforms. This paper presents a novel cross-modal contrastive learning framework that leverages the open-ended nature of text descriptions to guide music similarity modeling, addressing the limitations of traditional uni-modal approaches in capturing complex musical relationships. To overcome the scarcity of high-quality text-music paired data, this paper introduces a dual-source data acquisition approach combining online scraping and LLM-based prompting, where carefully designed prompts leverage LLMs' comprehensive music knowledge to generate contextually rich descriptions. Exten1sive experiments demonstrate that the proposed framework achieves significant performance improvements over existing benchmarks through objective metrics, subjective evaluations, and real-world A/B testing on the Huawei Music streaming platform.
Efficient Adapter Tuning for Joint Singing Voice Beat and Downbeat Tracking with Self-supervised Learning Features
Mar 13, 2025Singing voice beat tracking is a challenging task, due to the lack of musical accompaniment that often contains robust rhythmic and harmonic patterns, something most existing beat tracking systems utilize and can be essential for estimating beats. In this paper, a novel temporal convolutional network-based beat-tracking approach featuring self-supervised learning (SSL) representations and adapter tuning is proposed to track the beat and downbeat of singing voices jointly. The SSL DistilHuBERT representations are utilized to capture the semantic information of singing voices and are further fused with the generic spectral features to facilitate beat estimation. Sources of variabilities that are particularly prominent with the non-homogeneous singing voice data are reduced by the efficient adapter tuning. Extensive experiments show that feature fusion and adapter tuning improve the performance individually, and the combination of both leads to significantly better performances than the un-adapted baseline system, with up to 31.6% and 42.4% absolute F1-score improvements on beat and downbeat tracking, respectively.
Multi-view MidiVAE: Fusing Track- and Bar-view Representations for Long Multi-track Symbolic Music Generation
Jan 15, 2024



Variational Autoencoders (VAEs) constitute a crucial component of neural symbolic music generation, among which some works have yielded outstanding results and attracted considerable attention. Nevertheless, previous VAEs still encounter issues with overly long feature sequences and generated results lack contextual coherence, thus the challenge of modeling long multi-track symbolic music still remains unaddressed. To this end, we propose Multi-view MidiVAE, as one of the pioneers in VAE methods that effectively model and generate long multi-track symbolic music. The Multi-view MidiVAE utilizes the two-dimensional (2-D) representation, OctupleMIDI, to capture relationships among notes while reducing the feature sequences length. Moreover, we focus on instrumental characteristics and harmony as well as global and local information about the musical composition by employing a hybrid variational encoding-decoding strategy to integrate both Track- and Bar-view MidiVAE features. Objective and subjective experimental results on the CocoChorales dataset demonstrate that, compared to the baseline, Multi-view MidiVAE exhibits significant improvements in terms of modeling long multi-track symbolic music.
AnimeTAB: A new guitar tablature dataset of anime and game music
Oct 06, 2022

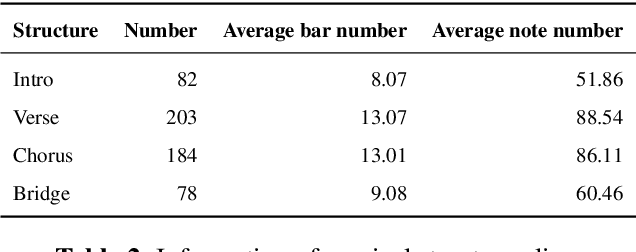

While guitar tablature has become a popular topic in MIR research, there exists no such a guitar tablature dataset that focuses on the soundtracks of anime and video games, which have a surprisingly broad and growing audience among the youths. In this paper, we present AnimeTAB, a fingerstyle guitar tablature dataset in MusicXML format, which provides more high-quality guitar tablature for both researchers and guitar players. AnimeTAB contains 412 full tracks and 547 clips, the latter are annotated with musical structures (intro, verse, chorus, and bridge). An accompanying analysis toolkit, TABprocessor, is included to further facilitate its use. This includes functions for melody and bassline extraction, key detection, and chord labeling, which are implemented using rule-based algorithms. We evaluated each of these functions against a manually annotated ground truth. Finally, as an example, we performed a music and technique analysis of AnimeTAB using TABprocessor. Our data and code have been made publicly available for composers, performers, and music information retrieval (MIR) researchers alike.