 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossMuSim: A Cross-Modal Framework for Music Similarity Retrieval with LLM-Powered Text Description Sourcing and Mining
Mar 29, 2025Music similarity retrieval is fundamental for managing and exploring relevant content from large collections in streaming platforms. This paper presents a novel cross-modal contrastive learning framework that leverages the open-ended nature of text descriptions to guide music similarity modeling, addressing the limitations of traditional uni-modal approaches in capturing complex musical relationships. To overcome the scarcity of high-quality text-music paired data, this paper introduces a dual-source data acquisition approach combining online scraping and LLM-based prompting, where carefully designed prompts leverage LLMs' comprehensive music knowledge to generate contextually rich descriptions. Exten1sive experiments demonstrate that the proposed framework achieves significant performance improvements over existing benchmarks through objective metrics, subjective evaluations, and real-world A/B testing on the Huawei Music streaming platform.
YourMT3+: Multi-instrument Music Transcription with Enhanced Transformer Architectures and Cross-dataset Stem Augmentation
Jul 05, 2024


Multi-instrument music transcription aims to convert polyphonic music recordings into musical scores assigned to each instrument. This task is challenging for modeling as it requires simultaneously identifying multiple instruments and transcribing their pitch and precise timing, and the lack of fully annotated data adds to the training difficulties. This paper introduces YourMT3+, a suite of models for enhanced multi-instrument music transcription based on the recent language token decoding approach of MT3. We strengthen its encoder by adopting a hierarchical attention transformer in the time-frequency domain and integrating a mixture of experts (MoE). To address data limitations, we introduce a new multi-channel decoding method for training with incomplete annotations and propose intra- and cross-stem augmentation for dataset mixing. Our experiments demonstrate direct vocal transcription capabilities, eliminating the need for voice separation pre-processors. Benchmarks across ten public datasets show our models' competitiveness with, or superiority to, existing transcription models. Further testing on pop music recordings highlights the limitations of current models. Fully reproducible code and datasets are available at \url{https://github.com/mimbres/YourMT3}
WikiMuTe: A web-sourced dataset of semantic descriptions for music audio
Dec 14, 2023Multi-modal deep learning techniques for matching free-form text with music have shown promising results in the field of Music Information Retrieval (MIR). Prior work is often based on large proprietary data while publicly available datasets are few and small in size. In this study, we present WikiMuTe, a new and open dataset containing rich semantic descriptions of music. The data is sourced from Wikipedia's rich catalogue of articles covering musical works. Using a dedicated text-mining pipeline, we extract both long and short-form descriptions covering a wide range of topics related to music content such as genre, style, mood, instrumentation, and tempo. To show the use of this data, we train a model that jointly learns text and audio representations and performs cross-modal retrieval. The model is evaluated on two tasks: tag-based music retrieval and music auto-tagging. The results show that while our approach has state-of-the-art performance on multiple tasks, but still observe a difference in performance depending on the data used for training.
Matching Text and Audio Embeddings: Exploring Transfer-learning Strategies for Language-based Audio Retrieval
Oct 06, 2022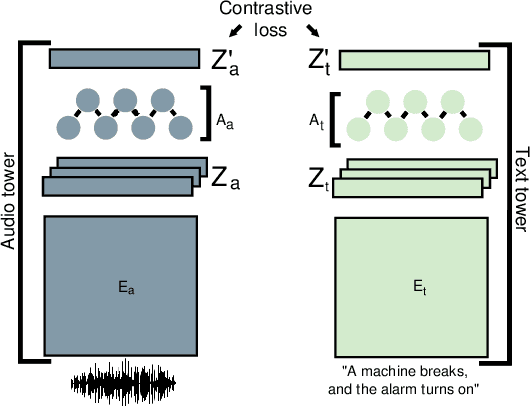

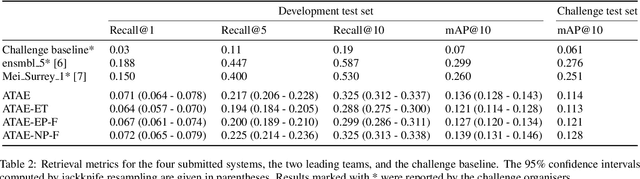
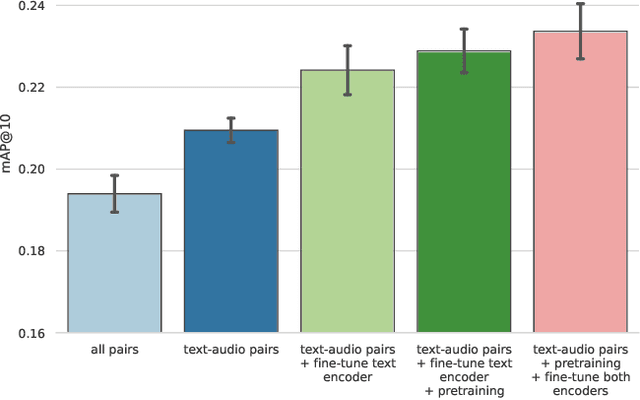
We present an analysis of large-scale pretrained deep learning models used for cross-modal (text-to-audio) retrieval. We use embeddings extracted by these models in a metric learning framework to connect matching pairs of audio and text. Shallow neural networks map the embeddings to a common dimensionality. Our system, which is an extension of our submission to the Language-based Audio Retrieval Task of the DCASE Challenge 2022, employs the RoBERTa foundation model as the text embedding extractor. A pretrained PANNs model extracts the audio embeddings. To improve the generalisation of our model, we investigate how pretraining with audio and associated noisy text collected from the online platform Freesound improves the performance of our method. Furthermore, our ablation study reveals that the proper choice of the loss function and fine-tuning the pretrained models are essential in training a competitive retrieval system.