 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn End-to-End Approach for Chord-Conditioned Song Generation
Sep 10, 2024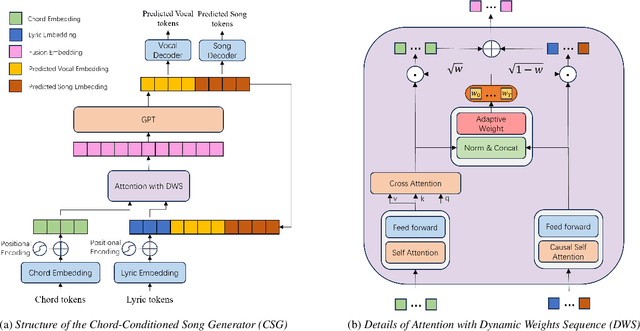
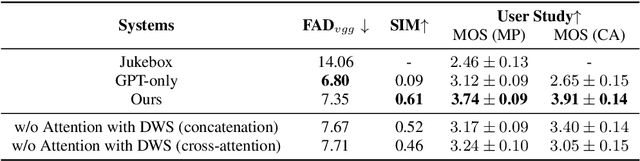
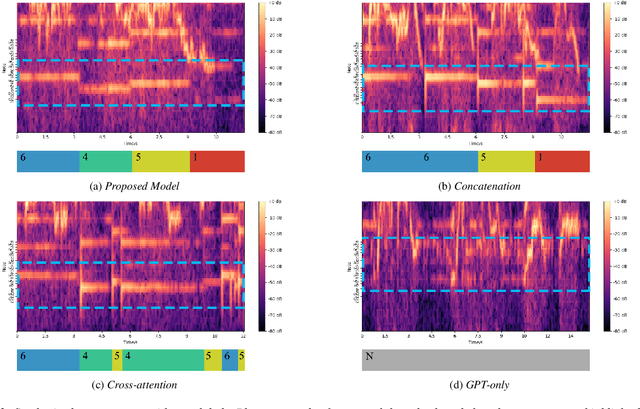
The Song Generation task aims to synthesize music composed of vocals and accompaniment from given lyrics. While the existing method, Jukebox, has explored this task, its constrained control over the generations often leads to deficiency in music performance. To mitigate the issue, we introduce an important concept from music composition, namely chords, to song generation networks. Chords form the foundation of accompaniment and provide vocal melody with associated harmony. Given the inaccuracy of automatic chord extractors, we devise a robust cross-attention mechanism augmented with dynamic weight sequence to integrate extracted chord information into song generations and reduce frame-level flaws, and propose a novel model termed Chord-Conditioned Song Generator (CSG) based on it. Experimental evidence demonstrates our proposed method outperforms other approaches in terms of musical performance and control precision of generated songs.
pFedGPA: Diffusion-based Generative Parameter Aggregation for Personalized Federated Learning
Sep 09, 2024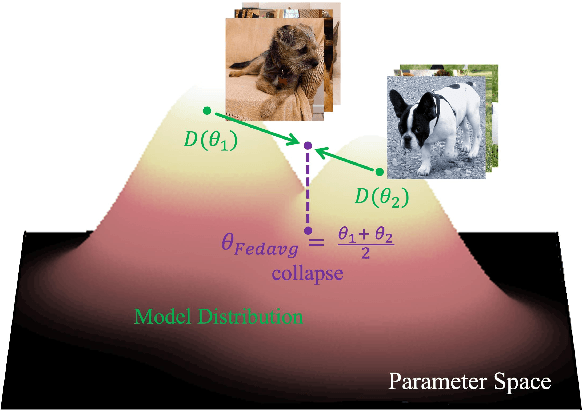
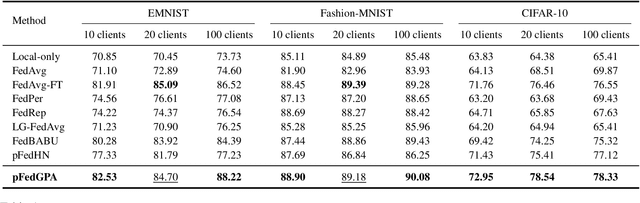
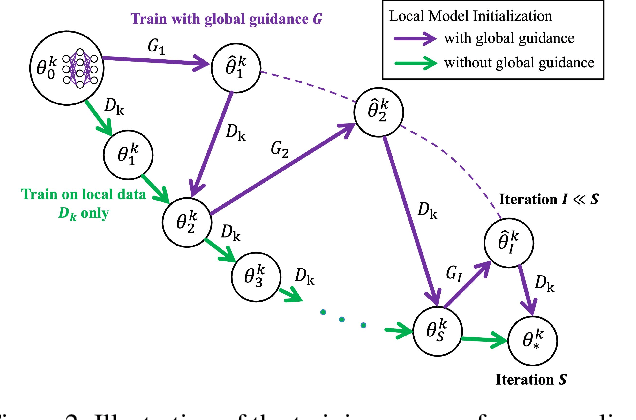
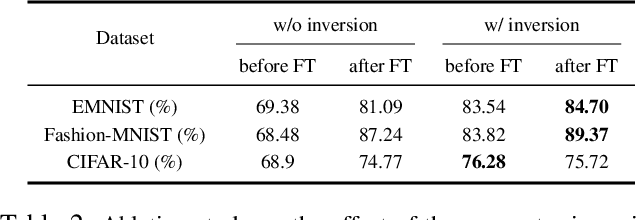
Federated Learning (FL) offers a decentralized approach to model training, where data remains local and only model parameters are shared between the clients and the central server. Traditional methods, such as Federated Averaging (FedAvg), linearly aggregate these parameters which are usually trained on heterogeneous data distributions, potentially overlooking the complex, high-dimensional nature of the parameter space. This can result in degraded performance of the aggregated model. While personalized FL approaches can mitigate the heterogeneous data issue to some extent, the limitation of linear aggregation remains unresolved. To alleviate this issue, we investigate the generative approach of diffusion model and propose a novel generative parameter aggregation framework for personalized FL, \texttt{pFedGPA}. In this framework, we deploy a diffusion model on the server to integrate the diverse parameter distributions and propose a parameter inversion method to efficiently generate a set of personalized parameters for each client. This inversion method transforms the uploaded parameters into a latent code, which is then aggregated through denoising sampling to produce the final personalized parameters. By encoding the dependence of a client's model parameters on the specific data distribution using the high-capacity diffusion model, \texttt{pFedGPA} can effectively decouple the complexity of the overall distribution of all clients' model parameters from the complexity of each individual client's parameter distribution. Our experimental results consistently demonstrate the superior performance of the proposed method across multiple datasets, surpassing baseline approaches.
SongCreator: Lyrics-based Universal Song Generation
Sep 09, 2024
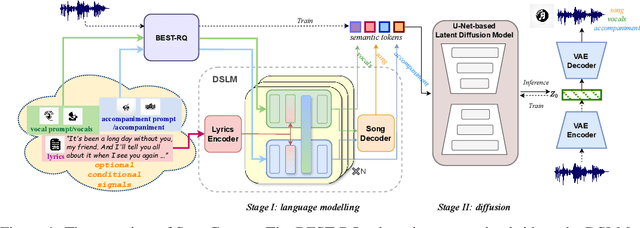
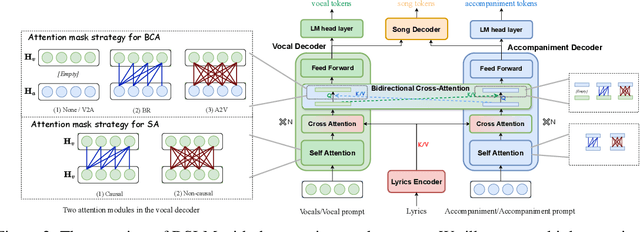

Music is an integral part of human culture, embodying human intelligence and creativity, of which songs compose an essential part. While various aspects of song generation have been explored by previous works, such as singing voice, vocal composition and instrumental arrangement, etc., generating songs with both vocals and accompaniment given lyrics remains a significant challenge, hindering the application of music generation models in the real world. In this light, we propose SongCreator, a song-generation system designed to tackle this challenge. The model features two novel designs: a meticulously designed dual-sequence language model (DSLM) to capture the information of vocals and accompaniment for song generation, and an additional attention mask strategy for DSLM, which allows our model to understand, generate and edit songs, making it suitable for various song-related generation tasks. Extensive experiments demonstrate the effectiveness of SongCreator by achieving state-of-the-art or competitive performances on all eight tasks. Notably, it surpasses previous works by a large margin in lyrics-to-song and lyrics-to-vocals. Additionally, it is able to independently control the acoustic conditions of the vocals and accompaniment in the generated song through different prompts, exhibiting its potential applicability. Our samples are available at https://songcreator.github.io/.
Enhancing Expressiveness in Dance Generation via Integrating Frequency and Music Style Information
Mar 09, 2024



Dance generation, as a branch of human motion generation, has attracted increasing attention. Recently, a few works attempt to enhance dance expressiveness, which includes genre matching, beat alignment, and dance dynamics, from certain aspects. However, the enhancement is quite limited as they lack comprehensive consideration of the aforementioned three factors. In this paper, we propose ExpressiveBailando, a novel dance generation method designed to generate expressive dances, concurrently taking all three factors into account. Specifically, we mitigate the issue of speed homogenization by incorporating frequency information into VQ-VAE, thus improving dance dynamics. Additionally, we integrate music style information by extracting genre- and beat-related features with a pre-trained music model, hence achieving improvements in the other two factors. Extensive experimental results demonstrate that our proposed method can generate dances with high expressiveness and outperforms existing methods both qualitatively and quantitatively.
Multi-view MidiVAE: Fusing Track- and Bar-view Representations for Long Multi-track Symbolic Music Generation
Jan 15, 2024



Variational Autoencoders (VAEs) constitute a crucial component of neural symbolic music generation, among which some works have yielded outstanding results and attracted considerable attention. Nevertheless, previous VAEs still encounter issues with overly long feature sequences and generated results lack contextual coherence, thus the challenge of modeling long multi-track symbolic music still remains unaddressed. To this end, we propose Multi-view MidiVAE, as one of the pioneers in VAE methods that effectively model and generate long multi-track symbolic music. The Multi-view MidiVAE utilizes the two-dimensional (2-D) representation, OctupleMIDI, to capture relationships among notes while reducing the feature sequences length. Moreover, we focus on instrumental characteristics and harmony as well as global and local information about the musical composition by employing a hybrid variational encoding-decoding strategy to integrate both Track- and Bar-view MidiVAE features. Objective and subjective experimental results on the CocoChorales dataset demonstrate that, compared to the baseline, Multi-view MidiVAE exhibits significant improvements in terms of modeling long multi-track symbolic music.
SimCalib: Graph Neural Network Calibration based on Similarity between Nodes
Dec 19, 2023Graph neural networks (GNNs) have exhibited impressive performance in modeling graph data as exemplified in various applications. Recently, the GNN calibration problem has attracted increasing attention, especially in cost-sensitive scenarios. Previous work has gained empirical insights on the issue, and devised effective approaches for it, but theoretical supports still fall short. In this work, we shed light on the relationship between GNN calibration and nodewise similarity via theoretical analysis. A novel calibration framework, named SimCalib, is accordingly proposed to consider similarity between nodes at global and local levels. At the global level, the Mahalanobis distance between the current node and class prototypes is integrated to implicitly consider similarity between the current node and all nodes in the same class. At the local level, the similarity of node representation movement dynamics, quantified by nodewise homophily and relative degree, is considered. Informed about the application of nodewise movement patterns in analyzing nodewise behavior on the over-smoothing problem, we empirically present a possible relationship between over-smoothing and GNN calibration problem. Experimentally, we discover a correlation between nodewise similarity and model calibration improvement, in alignment with our theoretical results. Additionally, we conduct extensive experiments investigating different design factors and demonstrate the effectiveness of our proposed SimCalib framework for GNN calibration by achieving state-of-the-art performance on 14 out of 16 benchmarks.
Explore 3D Dance Generation via Reward Model from Automatically-Ranked Demonstrations
Dec 18, 2023This paper presents an Exploratory 3D Dance generation framework, E3D2, designed to address the exploration capability deficiency in existing music-conditioned 3D dance generation models. Current models often generate monotonous and simplistic dance sequences that misalign with human preferences because they lack exploration capabilities. The E3D2 framework involves a reward model trained from automatically-ranked dance demonstrations, which then guides the reinforcement learning process. This approach encourages the agent to explore and generate high quality and diverse dance movement sequences. The soundness of the reward model is both theoretically and experimentally validated. Empirical experiments demonstrate the effectiveness of E3D2 on the AIST++ dataset. Project Page: https://sites.google.com/view/e3d2.
Stable Score Distillation for High-Quality 3D Generation
Dec 14, 2023



Score Distillation Sampling (SDS) has exhibited remarkable performance in conditional 3D content generation. However, a comprehensive understanding of the SDS formulation is still lacking, hindering the development of 3D generation. In this work, we present an interpretation of SDS as a combination of three functional components: mode-disengaging, mode-seeking and variance-reducing terms, and analyze the properties of each. We show that problems such as over-smoothness and color-saturation result from the intrinsic deficiency of the supervision terms and reveal that the variance-reducing term introduced by SDS is sub-optimal. Additionally, we shed light on the adoption of large Classifier-Free Guidance (CFG) scale for 3D generation. Based on the analysis, we propose a simple yet effective approach named Stable Score Distillation (SSD) which strategically orchestrates each term for high-quality 3D generation. Extensive experiments validate the efficacy of our approach, demonstrating its ability to generate high-fidelity 3D content without succumbing to issues such as over-smoothness and over-saturation, even under low CFG conditions with the most challenging NeRF representation.
TOSS:High-quality Text-guided Novel View Synthesis from a Single Image
Oct 16, 2023


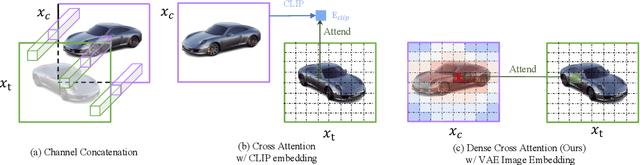
In this paper, we present TOSS, which introduces text to the task of novel view synthesis (NVS) from just a single RGB image. While Zero-1-to-3 has demonstrated impressive zero-shot open-set NVS capability, it treats NVS as a pure image-to-image translation problem. This approach suffers from the challengingly under-constrained nature of single-view NVS: the process lacks means of explicit user control and often results in implausible NVS generations. To address this limitation, TOSS uses text as high-level semantic information to constrain the NVS solution space. TOSS fine-tunes text-to-image Stable Diffusion pre-trained on large-scale text-image pairs and introduces modules specifically tailored to image and camera pose conditioning, as well as dedicated training for pose correctness and preservation of fine details. Comprehensive experiments are conducted with results showing that our proposed TOSS outperforms Zero-1-to-3 with more plausible, controllable and multiview-consistent NVS results. We further support these results with comprehensive ablations that underscore the effectiveness and potential of the introduced semantic guidance and architecture design.
AdaMesh: Personalized Facial Expressions and Head Poses for Speech-Driven 3D Facial Animation
Oct 11, 2023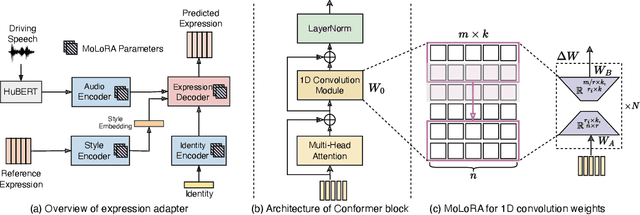
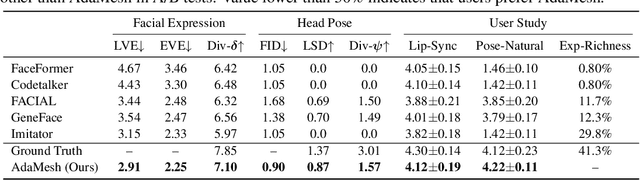
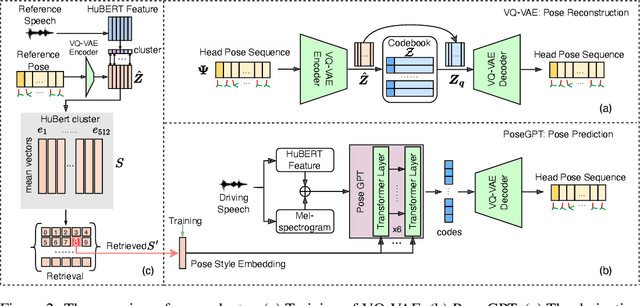

Speech-driven 3D facial animation aims at generating facial movements that are synchronized with the driving speech, which has been widely explored recently. Existing works mostly neglect the person-specific talking style in generation, including facial expression and head pose styles. Several works intend to capture the personalities by fine-tuning modules. However, limited training data leads to the lack of vividness. In this work, we propose AdaMesh, a novel adaptive speech-driven facial animation approach, which learns the personalized talking style from a reference video of about 10 seconds and generates vivid facial expressions and head poses. Specifically, we propose mixture-of-low-rank adaptation (MoLoRA) to fine-tune the expression adapter, which efficiently captures the facial expression style. For the personalized pose style, we propose a pose adapter by building a discrete pose prior and retrieving the appropriate style embedding with a semantic-aware pose style matrix without fine-tuning. Extensive experimental results show that our approach outperforms state-of-the-art methods, preserves the talking style in the reference video, and generates vivid facial animation. The supplementary video and code will be available at https://adamesh.github.io.