 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn End-to-End Approach for Chord-Conditioned Song Generation
Sep 10, 2024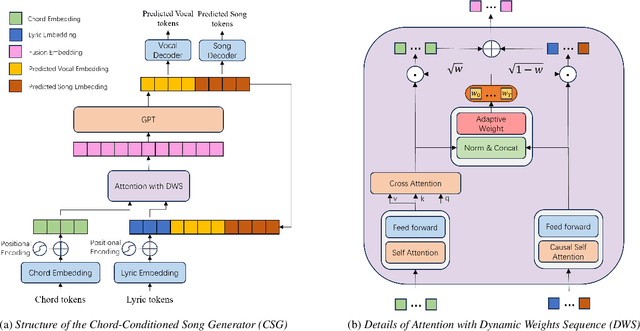
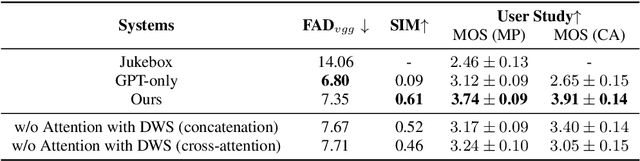
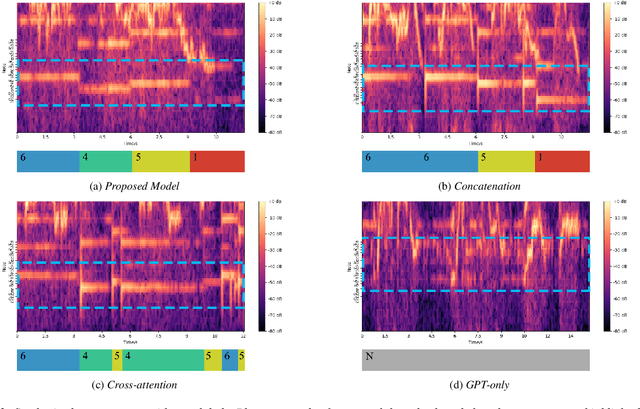
The Song Generation task aims to synthesize music composed of vocals and accompaniment from given lyrics. While the existing method, Jukebox, has explored this task, its constrained control over the generations often leads to deficiency in music performance. To mitigate the issue, we introduce an important concept from music composition, namely chords, to song generation networks. Chords form the foundation of accompaniment and provide vocal melody with associated harmony. Given the inaccuracy of automatic chord extractors, we devise a robust cross-attention mechanism augmented with dynamic weight sequence to integrate extracted chord information into song generations and reduce frame-level flaws, and propose a novel model termed Chord-Conditioned Song Generator (CSG) based on it. Experimental evidence demonstrates our proposed method outperforms other approaches in terms of musical performance and control precision of generated songs.
Enhancing Expressiveness in Dance Generation via Integrating Frequency and Music Style Information
Mar 09, 2024



Dance generation, as a branch of human motion generation, has attracted increasing attention. Recently, a few works attempt to enhance dance expressiveness, which includes genre matching, beat alignment, and dance dynamics, from certain aspects. However, the enhancement is quite limited as they lack comprehensive consideration of the aforementioned three factors. In this paper, we propose ExpressiveBailando, a novel dance generation method designed to generate expressive dances, concurrently taking all three factors into account. Specifically, we mitigate the issue of speed homogenization by incorporating frequency information into VQ-VAE, thus improving dance dynamics. Additionally, we integrate music style information by extracting genre- and beat-related features with a pre-trained music model, hence achieving improvements in the other two factors. Extensive experimental results demonstrate that our proposed method can generate dances with high expressiveness and outperforms existing methods both qualitatively and quantitatively.