 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferable FB-GNN-MBE Framework for Potential Energy Surfaces: Data-Adaptive Transfer Learning in Deep Learned Many-Body Expansion Theory
Apr 10, 2026Mechanistic understanding and rational design of complex chemical systems depend on fast and accurate predictions of electronic structures beyond individual building blocks. However, if the system exceeds hundreds of atoms, first-principles quantum mechanical (QM) modeling becomes impractical. In this study, we developed FB-GNN-MBE by integrating a fragment-based graph neural network (FB-GNN) into the many-body expansion (MBE) theory and demonstrated its capacity to reproduce first-principles potential energy surfaces (PES) for hierarchically structured systems with manageable accuracy, complexity, and interpretability. Specifically, we divided the entire system into basic building blocks (fragments), evaluated their one-fragment energies using a QM model, and addressed many-fragment interactions using the structure-property relationships trained by FB-GNNs. Our investigation shows that FB-GNN-MBE achieves chemical accuracy in predicting two-body (2B) and three-body (3B) energies across water, phenol, and mixture benchmarks, as well as the one-dimensional dissociation curves of water and phenol dimers. To transfer the success of FB-GNN-MBE across various systems with minimal computational costs and data demands, we developed and validated a teacher-student learning protocol. A heavy-weight FB-GNN trained on a mixed-density water cluster ensemble (teacher) distills its learned knowledge and passes it to a light-weight GNN (student), which is later fine-tuned on a uniform-density (H2O)21 cluster ensemble. This transfer learning strategy resulted in efficient and accurate prediction of 2B and 3B energies for variously sized water clusters without retraining. Our transferable FB-GNN-MBE framework outperformed conventional non-FB-GNN-based models and showed high practicality for large-scale molecular simulations.
NeuroLoRA: Context-Aware Neuromodulation for Parameter-Efficient Multi-Task Adaptation
Mar 12, 2026Parameter-Efficient Fine-Tuning (PEFT) techniques, particularly Low-Rank Adaptation (LoRA), have become essential for adapting Large Language Models (LLMs) to downstream tasks. While the recent FlyLoRA framework successfully leverages bio-inspired sparse random projections to mitigate parameter interference, it relies on a static, magnitude-based routing mechanism that is agnostic to input context. In this paper, we propose NeuroLoRA, a novel Mixture-of-Experts (MoE) based LoRA framework inspired by biological neuromodulation -- the dynamic regulation of neuronal excitability based on context. NeuroLoRA retains the computational efficiency of frozen random projections while introducing a lightweight, learnable neuromodulation gate that contextually rescales the projection space prior to expert selection. We further propose a Contrastive Orthogonality Loss to explicitly enforce separation between expert subspaces, enhancing both task decoupling and continual learning capacity. Extensive experiments on MMLU, GSM8K, and ScienceQA demonstrate that NeuroLoRA consistently outperforms FlyLoRA and other strong baselines across single-task adaptation, multi-task model merging, and sequential continual learning scenarios, while maintaining comparable parameter efficiency.
RPIQ: Residual-Projected Multi-Collaboration Closed-Loop and Single Instance Quantization for Visually Impaired Assistance
Jan 06, 2026Visually impaired users face significant challenges in daily information access and real-time environmental perception, and there is an urgent need for intelligent assistive systems with accurate recognition capabilities. Although large-scale models provide effective solutions for perception and reasoning, their practical deployment on assistive devices is severely constrained by excessive memory consumption and high inference costs. Moreover, existing quantization strategies often ignore inter-block error accumulation, leading to degraded model stability. To address these challenges, this study proposes a novel quantization framework -- Residual-Projected Multi-Collaboration Closed-Loop and Single Instance Quantization(RPIQ), whose quantization process adopts a multi-collaborative closed-loop compensation scheme based on Single Instance Calibration and Gauss-Seidel Iterative Quantization. Experiments on various types of large-scale models, including language models such as OPT, Qwen, and LLaMA, as well as vision-language models such as CogVLM2, demonstrate that RPIQ can compress models to 4-bit representation while significantly reducing peak memory consumption (approximately 60%-75% reduction compared to original full-precision models). The method maintains performance highly close to full-precision models across multiple language and visual tasks, and exhibits excellent recognition and reasoning capabilities in key applications such as text understanding and visual question answering in complex scenarios. While verifying the effectiveness of RPIQ for deployment in real assistive systems, this study also advances the computational efficiency and reliability of large models, enabling them to provide visually impaired users with the required information accurately and rapidly.
Balancing Rewards in Text Summarization: Multi-Objective Reinforcement Learning via HyperVolume Optimization
Oct 22, 2025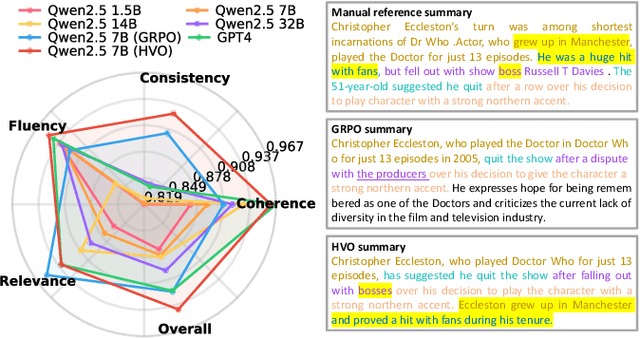
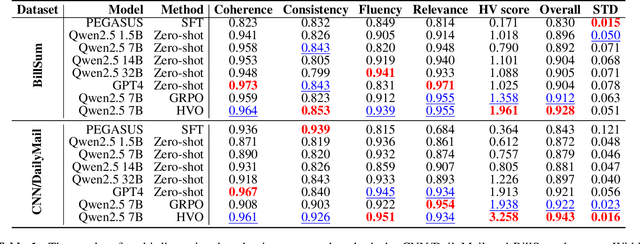
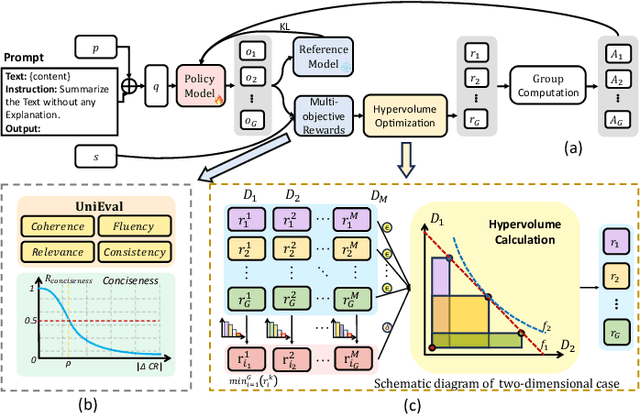

Text summarization is a crucial task that requires the simultaneous optimization of multiple objectives, including consistency, coherence, relevance, and fluency, which presents considerable challenges. Although large language models (LLMs) have demonstrated remarkable performance, enhanced by reinforcement learning (RL), few studies have focused on optimizing the multi-objective problem of summarization through RL based on LLMs. In this paper, we introduce hypervolume optimization (HVO), a novel optimization strategy that dynamically adjusts the scores between groups during the reward process in RL by using the hypervolume method. This method guides the model's optimization to progressively approximate the pareto front, thereby generating balanced summaries across multiple objectives. Experimental results on several representative summarization datasets demonstrate that our method outperforms group relative policy optimization (GRPO) in overall scores and shows more balanced performance across different dimensions. Moreover, a 7B foundation model enhanced by HVO performs comparably to GPT-4 in the summarization task, while maintaining a shorter generation length. Our code is publicly available at https://github.com/ai4business-LiAuto/HVO.git
Empowering Clinical Trial Design through AI: A Randomized Evaluation of PowerGPT
Sep 15, 2025



Sample size calculations for power analysis are critical for clinical research and trial design, yet their complexity and reliance on statistical expertise create barriers for many researchers. We introduce PowerGPT, an AI-powered system integrating large language models (LLMs) with statistical engines to automate test selection and sample size estimation in trial design. In a randomized trial to evaluate its effectiveness, PowerGPT significantly improved task completion rates (99.3% vs. 88.9% for test selection, 99.3% vs. 77.8% for sample size calculation) and accuracy (94.1% vs. 55.4% in sample size estimation, p < 0.001), while reducing average completion time (4.0 vs. 9.3 minutes, p < 0.001). These gains were consistent across various statistical tests and benefited both statisticians and non-statisticians as well as bridging expertise gaps. Already under deployment across multiple institutions, PowerGPT represents a scalable AI-driven approach that enhances accessibility, efficiency, and accuracy in statistical power analysis for clinical research.
MoFE-Time: Mixture of Frequency Domain Experts for Time-Series Forecasting Models
Jul 09, 2025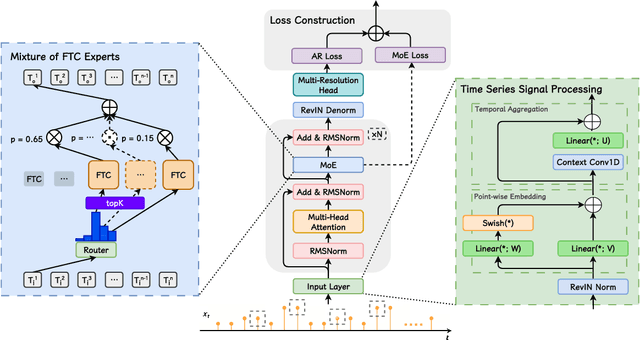



As a prominent data modality task, time series forecasting plays a pivotal role in diverse applications. With the remarkable advancements in Large Language Models (LLMs), the adoption of LLMs as the foundational architecture for time series modeling has gained significant attention. Although existing models achieve some success, they rarely both model time and frequency characteristics in a pretraining-finetuning paradigm leading to suboptimal performance in predictions of complex time series, which requires both modeling periodicity and prior pattern knowledge of signals. We propose MoFE-Time, an innovative time series forecasting model that integrates time and frequency domain features within a Mixture of Experts (MoE) network. Moreover, we use the pretraining-finetuning paradigm as our training framework to effectively transfer prior pattern knowledge across pretraining and finetuning datasets with different periodicity distributions. Our method introduces both frequency and time cells as experts after attention modules and leverages the MoE routing mechanism to construct multidimensional sparse representations of input signals. In experiments on six public benchmarks, MoFE-Time has achieved new state-of-the-art performance, reducing MSE and MAE by 6.95% and 6.02% compared to the representative methods Time-MoE. Beyond the existing evaluation benchmarks, we have developed a proprietary dataset, NEV-sales, derived from real-world business scenarios. Our method achieves outstanding results on this dataset, underscoring the effectiveness of the MoFE-Time model in practical commercial applications.
SWDL: Stratum-Wise Difference Learning with Deep Laplacian Pyramid for Semi-Supervised 3D Intracranial Hemorrhage Segmentation
Jun 12, 2025Recent advances in medical imaging have established deep learning-based segmentation as the predominant approach, though it typically requires large amounts of manually annotated data. However, obtaining annotations for intracranial hemorrhage (ICH) remains particularly challenging due to the tedious and costly labeling process. Semi-supervised learning (SSL) has emerged as a promising solution to address the scarcity of labeled data, especially in volumetric medical image segmentation. Unlike conventional SSL methods that primarily focus on high-confidence pseudo-labels or consistency regularization, we propose SWDL-Net, a novel SSL framework that exploits the complementary advantages of Laplacian pyramid and deep convolutional upsampling. The Laplacian pyramid excels at edge sharpening, while deep convolutions enhance detail precision through flexible feature mapping. Our framework achieves superior segmentation of lesion details and boundaries through a difference learning mechanism that effectively integrates these complementary approaches. Extensive experiments on a 271-case ICH dataset and public benchmarks demonstrate that SWDL-Net outperforms current state-of-the-art methods in scenarios with only 2% labeled data. Additional evaluations on the publicly available Brain Hemorrhage Segmentation Dataset (BHSD) with 5% labeled data further confirm the superiority of our approach. Code and data have been released at https://github.com/SIAT-CT-LAB/SWDL.
YH-MINER: Multimodal Intelligent System for Natural Ecological Reef Metric Extraction
May 29, 2025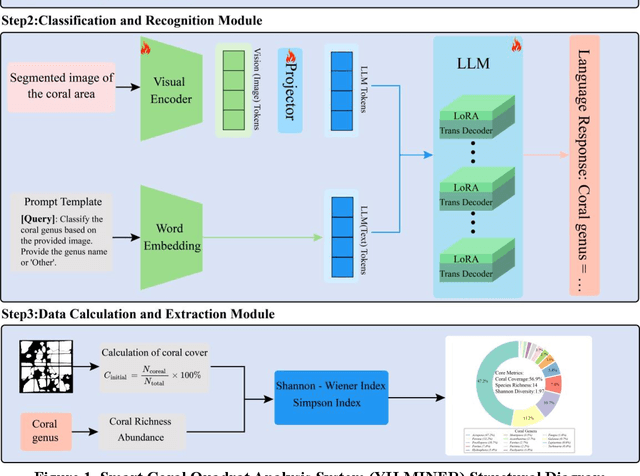
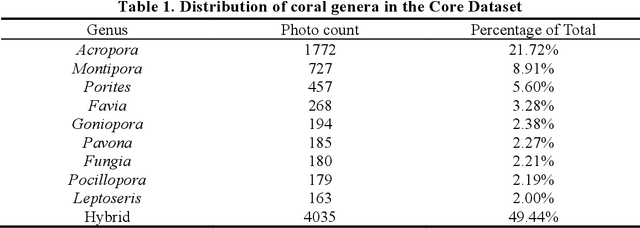
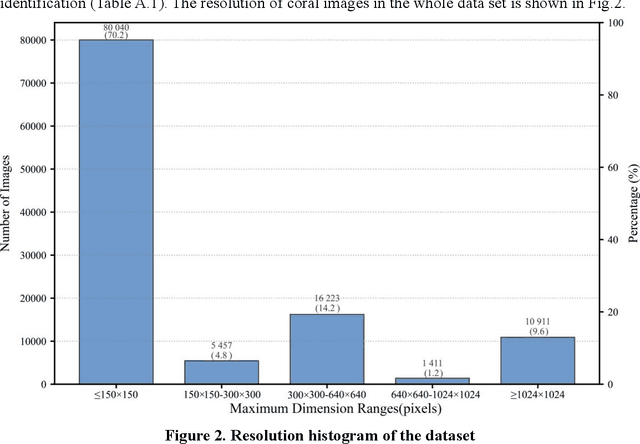

Coral reefs, crucial for sustaining marine biodiversity and ecological processes (e.g., nutrient cycling, habitat provision), face escalating threats, underscoring the need for efficient monitoring. Coral reef ecological monitoring faces dual challenges of low efficiency in manual analysis and insufficient segmentation accuracy in complex underwater scenarios. This study develops the YH-MINER system, establishing an intelligent framework centered on the Multimodal Large Model (MLLM) for "object detection-semantic segmentation-prior input". The system uses the object detection module (mAP@0.5=0.78) to generate spatial prior boxes for coral instances, driving the segment module to complete pixel-level segmentation in low-light and densely occluded scenarios. The segmentation masks and finetuned classification instructions are fed into the Qwen2-VL-based multimodal model as prior inputs, achieving a genus-level classification accuracy of 88% and simultaneously extracting core ecological metrics. Meanwhile, the system retains the scalability of the multimodal model through standardized interfaces, laying a foundation for future integration into multimodal agent-based underwater robots and supporting the full-process automation of "image acquisition-prior generation-real-time analysis".
ViewSpatial-Bench: Evaluating Multi-perspective Spatial Localization in Vision-Language Models
May 27, 2025



Vision-language models (VLMs) have demonstrated remarkable capabilities in understanding and reasoning about visual content, but significant challenges persist in tasks requiring cross-viewpoint understanding and spatial reasoning. We identify a critical limitation: current VLMs excel primarily at egocentric spatial reasoning (from the camera's perspective) but fail to generalize to allocentric viewpoints when required to adopt another entity's spatial frame of reference. We introduce ViewSpatial-Bench, the first comprehensive benchmark designed specifically for multi-viewpoint spatial localization recognition evaluation across five distinct task types, supported by an automated 3D annotation pipeline that generates precise directional labels. Comprehensive evaluation of diverse VLMs on ViewSpatial-Bench reveals a significant performance disparity: models demonstrate reasonable performance on camera-perspective tasks but exhibit reduced accuracy when reasoning from a human viewpoint. By fine-tuning VLMs on our multi-perspective spatial dataset, we achieve an overall performance improvement of 46.24% across tasks, highlighting the efficacy of our approach. Our work establishes a crucial benchmark for spatial intelligence in embodied AI systems and provides empirical evidence that modeling 3D spatial relationships enhances VLMs' corresponding spatial comprehension capabilities.
Generalized Visual Relation Detection with Diffusion Models
Apr 16, 2025
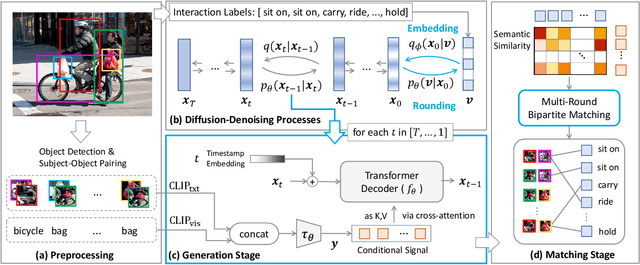


Visual relation detection (VRD) aims to identify relationships (or interactions) between object pairs in an image. Although recent VRD models have achieved impressive performance, they are all restricted to pre-defined relation categories, while failing to consider the semantic ambiguity characteristic of visual relations. Unlike objects, the appearance of visual relations is always subtle and can be described by multiple predicate words from different perspectives, e.g., ``ride'' can be depicted as ``race'' and ``sit on'', from the sports and spatial position views, respectively. To this end, we propose to model visual relations as continuous embeddings, and design diffusion models to achieve generalized VRD in a conditional generative manner, termed Diff-VRD. We model the diffusion process in a latent space and generate all possible relations in the image as an embedding sequence. During the generation, the visual and text embeddings of subject-object pairs serve as conditional signals and are injected via cross-attention. After the generation, we design a subsequent matching stage to assign the relation words to subject-object pairs by considering their semantic similarities. Benefiting from the diffusion-based generative process, our Diff-VRD is able to generate visual relations beyond the pre-defined category labels of datasets. To properly evaluate this generalized VRD task, we introduce two evaluation metrics, i.e., text-to-image retrieval and SPICE PR Curve inspired by image captioning. Extensive experiments in both human-object interaction (HOI) detection and scene graph generation (SGG) benchmarks attest to the superiority and effectiveness of Diff-VRD.