 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Reinforcement Learning for GUI Grounding via Region Consistency
Aug 07, 2025Graphical User Interface (GUI) grounding, the task of mapping natural language instructions to precise screen coordinates, is fundamental to autonomous GUI agents. While existing methods achieve strong performance through extensive supervised training or reinforcement learning with labeled rewards, they remain constrained by the cost and availability of pixel-level annotations. We observe that when models generate multiple predictions for the same GUI element, the spatial overlap patterns reveal implicit confidence signals that can guide more accurate localization. Leveraging this insight, we propose GUI-RC (Region Consistency), a test-time scaling method that constructs spatial voting grids from multiple sampled predictions to identify consensus regions where models show highest agreement. Without any training, GUI-RC improves accuracy by 2-3% across various architectures on ScreenSpot benchmarks. We further introduce GUI-RCPO (Region Consistency Policy Optimization), which transforms these consistency patterns into rewards for test-time reinforcement learning. By computing how well each prediction aligns with the collective consensus, GUI-RCPO enables models to iteratively refine their outputs on unlabeled data during inference. Extensive experiments demonstrate the generality of our approach: GUI-RC boosts Qwen2.5-VL-3B-Instruct from 80.11% to 83.57% on ScreenSpot-v2, while GUI-RCPO further improves it to 85.14% through self-supervised optimization. Our approach reveals the untapped potential of test-time scaling and test-time reinforcement learning for GUI grounding, offering a promising path toward more robust and data-efficient GUI agents.
ViewSpatial-Bench: Evaluating Multi-perspective Spatial Localization in Vision-Language Models
May 27, 2025



Vision-language models (VLMs) have demonstrated remarkable capabilities in understanding and reasoning about visual content, but significant challenges persist in tasks requiring cross-viewpoint understanding and spatial reasoning. We identify a critical limitation: current VLMs excel primarily at egocentric spatial reasoning (from the camera's perspective) but fail to generalize to allocentric viewpoints when required to adopt another entity's spatial frame of reference. We introduce ViewSpatial-Bench, the first comprehensive benchmark designed specifically for multi-viewpoint spatial localization recognition evaluation across five distinct task types, supported by an automated 3D annotation pipeline that generates precise directional labels. Comprehensive evaluation of diverse VLMs on ViewSpatial-Bench reveals a significant performance disparity: models demonstrate reasonable performance on camera-perspective tasks but exhibit reduced accuracy when reasoning from a human viewpoint. By fine-tuning VLMs on our multi-perspective spatial dataset, we achieve an overall performance improvement of 46.24% across tasks, highlighting the efficacy of our approach. Our work establishes a crucial benchmark for spatial intelligence in embodied AI systems and provides empirical evidence that modeling 3D spatial relationships enhances VLMs' corresponding spatial comprehension capabilities.
Mind the Gap: Bridging Thought Leap for Improved Chain-of-Thought Tuning
May 21, 2025Large language models (LLMs) have achieved remarkable progress on mathematical tasks through Chain-of-Thought (CoT) reasoning. However, existing mathematical CoT datasets often suffer from Thought Leaps due to experts omitting intermediate steps, which negatively impacts model learning and generalization. We propose the CoT Thought Leap Bridge Task, which aims to automatically detect leaps and generate missing intermediate reasoning steps to restore the completeness and coherence of CoT. To facilitate this, we constructed a specialized training dataset called ScaleQM+, based on the structured ScaleQuestMath dataset, and trained CoT-Bridge to bridge thought leaps. Through comprehensive experiments on mathematical reasoning benchmarks, we demonstrate that models fine-tuned on bridged datasets consistently outperform those trained on original datasets, with improvements of up to +5.87% on NuminaMath. Our approach effectively enhances distilled data (+3.02%) and provides better starting points for reinforcement learning (+3.1%), functioning as a plug-and-play module compatible with existing optimization techniques. Furthermore, CoT-Bridge demonstrate improved generalization to out-of-domain logical reasoning tasks, confirming that enhancing reasoning completeness yields broadly applicable benefits.
Multicast Scheduling for Multi-Message over Multi-Channel: A Permutation-based Wolpertinger Deep Reinforcement Learning Method
May 19, 2022

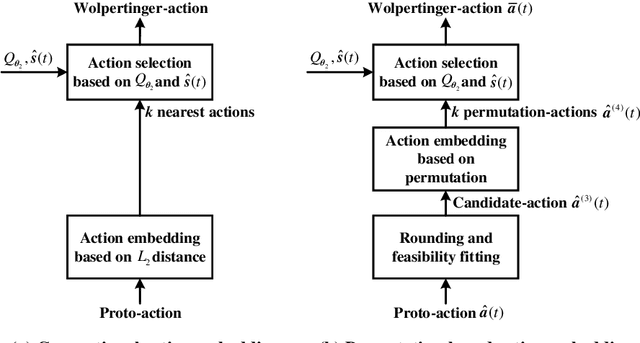
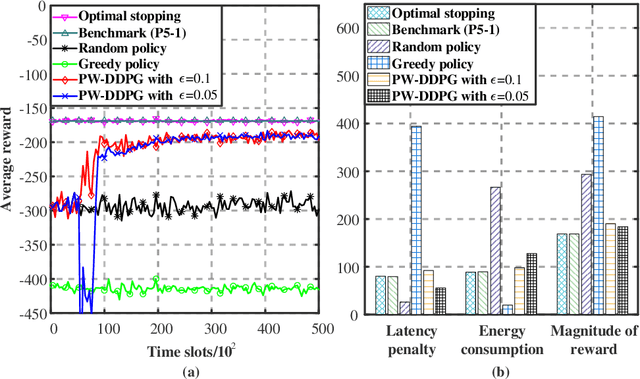
Multicasting is an efficient technique to simultaneously transmit common messages from the base station (BS) to multiple mobile users (MUs). The multicast scheduling problem for multiple messages over multiple channels, which jointly minimizes the energy consumption of the BS and the latency of serving asynchronized requests from the MUs, is formulated as an infinite-horizon Markov decision process (MDP) with large discrete action space and multiple time-varying constraints, which has not been efficiently addressed in the literatures. By studying the intrinsic features of this MDP under stationary policies and refining the reward function, we first simplify it to an equivalent form with a much smaller state space. Then, we propose a modified deep reinforcement learning (DRL) algorithm, namely the permutation-based Wolpertinger deep deterministic policy gradient (PW-DDPG), to solve the simplified problem. Specifically, PW-DDPG utilizes a permutation-based action embedding module to address the large discrete action space issue and a feasible exploration module to deal with the time-varying constraints. Moreover, as a benchmark, an upper bound of the considered MDP is derived by solving an integer programming problem. Numerical results validate that the proposed algorithm achieves close performance to the derived benchmark.
Coexistence between Task- and Data-Oriented Communications: A Whittle's Index Guided Multi-Agent Reinforcement Learning Approach
May 19, 2022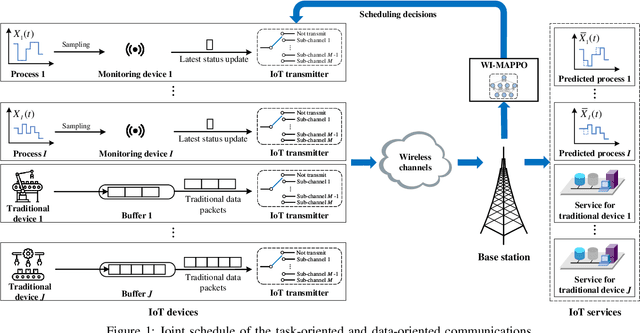
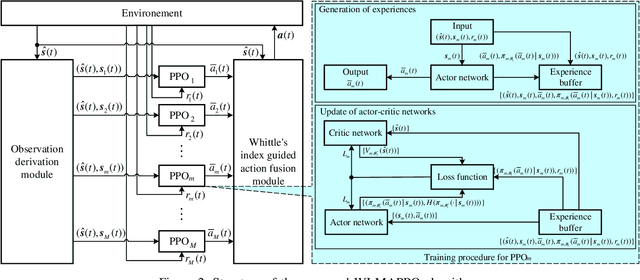
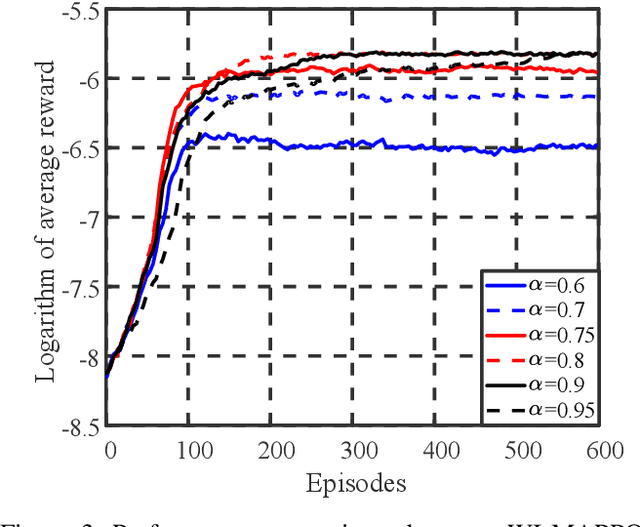
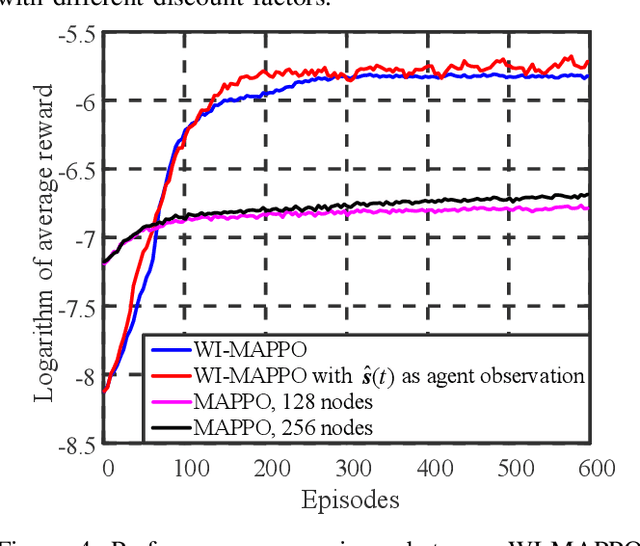
We investigate the coexistence of task-oriented and data-oriented communications in a IoT system that shares a group of channels, and study the scheduling problem to jointly optimize the weighted age of incorrect information (AoII) and throughput, which are the performance metrics of the two types of communications, respectively. This problem is formulated as a Markov decision problem, which is difficult to solve due to the large discrete action space and the time-varying action constraints induced by the stochastic availability of channels. By exploiting the intrinsic properties of this problem and reformulating the reward function based on channel statistics, we first simplify the solution space, state space, and optimality criteria, and convert it to an equivalent Markov game, for which the large discrete action space issue is greatly relieved. Then, we propose a Whittle's index guided multi-agent proximal policy optimization (WI-MAPPO) algorithm to solve the considered game, where the embedded Whittle's index module further shrinks the action space, and the proposed offline training algorithm extends the training kernel of conventional MAPPO to address the issue of time-varying constraints. Finally, numerical results validate that the proposed algorithm significantly outperforms state-of-the-art age of information (AoI) based algorithms under scenarios with insufficient channel resources.