 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain-of-Glimpse: Search-Guided Progressive Object-Grounded Reasoning for Video Understanding
Apr 16, 2026Video understanding requires identifying and reasoning over semantically discriminative visual objects across frames, yet existing object-agnostic solutions struggle to effectively handle substantial object variations over time. To address this, we introduce Chain-of-Glimpse, a search-guided progressive object-grounded reasoning framework that explicitly anchors each reasoning step to specific visual evidence regions, enabling compositional and multi-step decision-making. Formally, Chain-of-Glimpse formulates video reasoning as a step-by-step process that incrementally builds spatially grounded traces around task-relevant visual objects, thereby mitigating over-reliance on saliency-driven cues. Specifically, Chain-of-Glimpse features a search-guided controller, optimized via reinforcement learning with a format reward that significantly incentivizes grounding capability, to iteratively ground visual evidence regions and form reliable reasoning trajectories, yielding accurate and interpretable multi-step decisions. Extensive evaluations on both in domain NExTQA and out-of-domain Video-Holmes, CG-Bench Reasoning, and VRBench benchmarks demonstrate consistent performance gains, robustness and generalization of Chain-of-Glimpse across diverse video reasoning tasks.
OAHuman: Occlusion-Aware 3D Human Reconstruction from Monocular Images
Mar 15, 2026Monocular 3D human reconstruction in real-world scenarios remains highly challenging due to frequent occlusions from surrounding objects, people, or image truncation. Such occlusions lead to missing geometry and unreliable appearance cues, severely degrading the completeness and realism of reconstructed human models. Although recent neural implicit methods achieve impressive results on clean inputs, they struggle under occlusion due to entangled modeling of shape and texture. In this paper, we propose OAHuman, an occlusion-aware framework that explicitly decouples geometry reconstruction and texture synthesis for robust 3D human modeling from a single RGB image. The core innovation lies in the decoupling-perception paradigm, which addresses the fundamental issue of geometry-texture cross-contamination in occluded regions. Our framework ensures that geometry reconstruction is perceptually reinforced even in occluded areas, isolating it from texture interference. In parallel, texture synthesis is learned exclusively from visible regions, preventing texture errors from being transferred to the occluded areas. This decoupling approach enables OAHuman to achieve robust and high-fidelity reconstruction under occlusion, which has been a long-standing challenge in the field. Extensive experiments on occlusion-rich benchmarks demonstrate that OAHuman achieves superior performance in terms of structural completeness, surface detail, and texture realism, significantly improving monocular 3D human reconstruction under occlusion conditions.
Unlocking High-Fidelity Analog Joint Source-Channel Coding on Standard Digital Transceivers
Mar 10, 2026Analog joint source-channel coding (JSCC) has demonstrated superior performance for semantic communications through graceful degradation across channel conditions. However, a fundamental hardware-software mismatch prevents deployment on modern digital physical layers (PHYs): analog JSCC generates continuous-valued symbols requiring infinite waveform diversity, while digital PHYs produce a finite set of discrete waveforms and employ non-differentiable operations that break end-to-end gradient flow. Existing solutions either fundamentally limit representation granularity or require impractical white-box PHY access. We introduce D2AJSCC, a novel framework enabling high-fidelity analog JSCC deployment on standard digital PHYs. Our approach exploits orthogonal frequency-division multiplexing's parallel subcarrier structure as a waveform synthesizer: computational PHY inversion determines input bitstreams that orchestrate subcarrier amplitudes and phases to emulate ideal analog waveforms. To enable end-to-end training despite non-differentiable PHY operations, we develop ProxyNet-a differentiable neural surrogate of the communication link that provides uninterrupted gradient flow while preventing JSCC degeneration. Simulation results for image transmission over WiFi PHY demonstrate that our system achieves near-ideal analog JSCC performance with graceful degradation across SNR conditions, while baselines exhibit cliff effects or catastrophic failures. By enabling next-generation semantic transmission on legacy infrastructure without hardware modification, our framework promotes sustainable network evolution and bridges the critical gap between analog JSCC's theoretical promise and practical deployment on ubiquitous digital hardware.
VQ-DSC-R: Robust Vector Quantized-Enabled Digital Semantic Communication With OFDM Transmission
Feb 05, 2026Digital mapping of semantic features is essential for achieving interoperability between semantic communication and practical digital infrastructure. However, current research efforts predominantly concentrate on analog semantic communication with simplified channel models. To bridge these gaps, we develop a robust vector quantized-enabled digital semantic communication (VQ-DSC-R) system built upon orthogonal frequency division multiplexing (OFDM) transmission. Our work encompasses the framework design of VQ-DSC-R, followed by a comprehensive optimization study. Firstly, we design a Swin Transformer-based backbone for hierarchical semantic feature extraction, integrated with VQ modules that map the features into a shared semantic quantized codebook (SQC) for efficient index transmission. Secondly, we propose a differentiable vector quantization with adaptive noise-variance (ANDVQ) scheme to mitigate quantization errors in SQC, which dynamically adjusts the quantization process using K-nearest neighbor statistics, while exponential moving average mechanism stabilizes SQC training. Thirdly, for robust index transmission over multipath fading channel and noise, we develop a conditional diffusion model (CDM) to refine channel state information, and design an attention-based module to dynamically adapt to channel noise. The entire VQ-DSC-R system is optimized via a three-stage training strategy. Extensive experiments demonstrate superiority of VQ-DSC-R over benchmark schemes, achieving high compression ratios and robust performance in practical scenarios.
Secure Intellicise Wireless Network: Agentic AI for Coverless Semantic Steganography Communication
Jan 23, 2026Semantic Communication (SemCom), leveraging its significant advantages in transmission efficiency and reliability, has emerged as a core technology for constructing future intellicise (intelligent and concise) wireless networks. However, intelligent attacks represented by semantic eavesdropping pose severe challenges to the security of SemCom. To address this challenge, Semantic Steganographic Communication (SemSteCom) achieves ``invisible'' encryption by implicitly embedding private semantic information into cover modality carriers. The state-of-the-art study has further introduced generative diffusion models to directly generate stega images without relying on original cover images, effectively enhancing steganographic capacity. Nevertheless, the recovery process of private images is highly dependent on the guidance of private semantic keys, which may be inferred by intelligent eavesdroppers, thereby introducing new security threats. To address this issue, we propose an Agentic AI-driven SemSteCom (AgentSemSteCom) scheme, which includes semantic extraction, digital token controlled reference image generation, coverless steganography, semantic codec, and optional task-oriented enhancement modules. The proposed AgentSemSteCom scheme obviates the need for both cover images and private semantic keys, thereby boosting steganographic capacity while reinforcing transmission security. The simulation results on open-source datasets verify that, AgentSemSteCom achieves better transmission quality and higher security levels than the baseline scheme.
Integrated Sensing and Semantic Communication with Adaptive Source-Channel Coding
Jan 19, 2026Semantic communication has emerged as a new paradigm to facilitate the performance of integrated sensing and communication systems in 6G. However, most of the existing works mainly focus on sensing data compression to reduce the subsequent communication overheads, without considering the integrated transmission framework for both the SemCom and sensing tasks. This paper proposes an adaptive source-channel coding and beamforming design framework for integrated sensing and SemCom systems by jointly optimizing the coding rate for SemCom task and the transmit beamforming for both the SemCom and sensing tasks. Specifically, an end-to-end semantic distortion function is approximated by deriving an upper bound composing of source and channel coding induced components, and then a hybrid Cramér-Rao bound (HCRB) is also derived for target position under imperfect time synchronization. To facilitate the joint optimization, a distortion minimization problem is formulated by considering the HCRB threshold, channel uses, and power budget. Subsequently, an alternative optimization algorithm composed of successive convex approximation and fractional programming is proposed to address this problem by decoupling it into two subproblems for coding rate and beamforming designs, respectively. Simulation results demonstrate that our proposed scheme outperforms the conventional deep joint source-channel coding -water filling-zero forcing benchmark.
Vector Quantized-Aided XL-MIMO CSI Feedback with Channel Adaptive Transmission
Jan 12, 2026Efficient channel state information (CSI) feedback is critical for 6G extremely large-scale multiple-input multiple-output (XL-MIMO) systems to mitigate channel interference. However, the massive antenna scale imposes a severe burden on feedback overhead. Meanwhile, existing quantized feedback methods face dual challenges of limited quantization precision and insufficient channel robustness when compressing high-dimensional channel features into discrete symbols. To reduce these gaps, guided by the deep joint source-channel coding (DJSCC) framework, we propose a vector quantized (VQ)-aided scheme for CSI feedback in XL-MIMO systems considering the near-field effect, named VQ-DJSCC-F. Firstly, taking advantage of the sparsity of near-field channels in the polar-delay domain, we extract energy-concentrated features to reduce dimensionality. Then, we simultaneously design the Transformer and CNN (convolutional neural network) architectures as the backbones to hierarchically extract CSI features, followed by VQ modules projecting features into a discrete latent space. The entropy loss regularization in synergy with an exponential moving average (EMA) update strategy is introduced to maximize quantization precision. Furthermore, we develop an attention mechanism-driven channel adaptation module to mitigate the impact of wireless channel fading on the transmission of index sequences. Simulation results demonstrate that the proposed scheme achieves superior CSI reconstruction accuracy with lower feedback overheads under varying channel conditions.
Flow matching-based generative models for MIMO channel estimation
Nov 14, 2025Diffusion model (DM)-based channel estimation, which generates channel samples via a posteriori sampling stepwise with denoising process, has shown potential in high-precision channel state information (CSI) acquisition. However, slow sampling speed is an essential challenge for recent developed DM-based schemes. To alleviate this problem, we propose a novel flow matching (FM)-based generative model for multiple-input multiple-output (MIMO) channel estimation. We first formulate the channel estimation problem within FM framework, where the conditional probability path is constructed from the noisy channel distribution to the true channel distribution. In this case, the path evolves along the straight-line trajectory at a constant speed. Then, guided by this, we derive the velocity field that depends solely on the noise statistics to guide generative models training. Furthermore, during the sampling phase, we utilize the trained velocity field as prior information for channel estimation, which allows for quick and reliable noise channel enhancement via ordinary differential equation (ODE) Euler solver. Finally, numerical results demonstrate that the proposed FM-based channel estimation scheme can significantly reduce the sampling overhead compared to other popular DM-based schemes, such as the score matching (SM)-based scheme. Meanwhile, it achieves superior channel estimation accuracy under different channel conditions.
VQ-VAE Based Digital Semantic Communication with Importance-Aware OFDM Transmission
Aug 12, 2025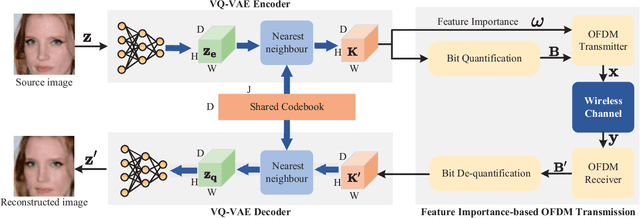
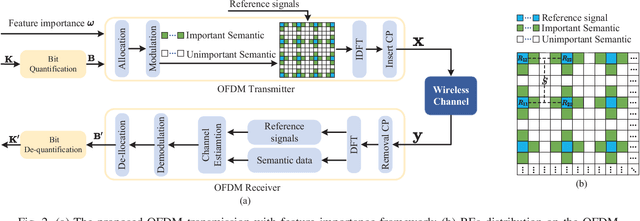
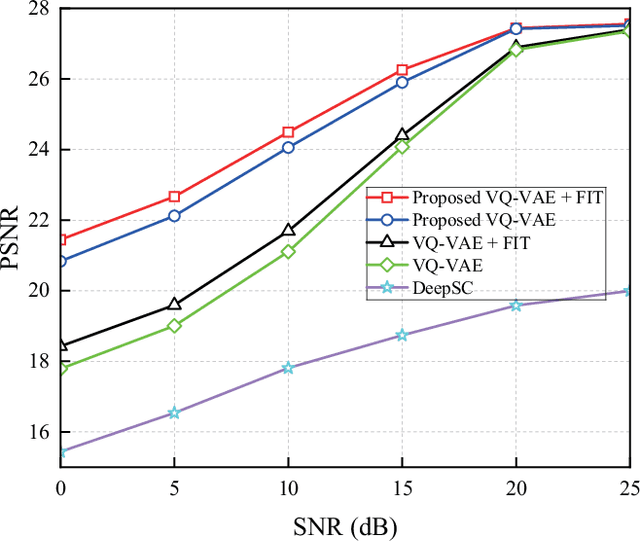
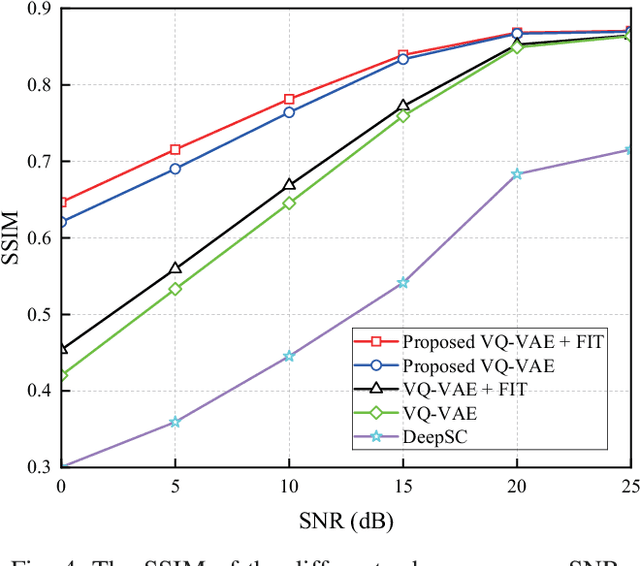
Semantic communication (SemCom) significantly reduces redundant data and improves transmission efficiency by extracting the latent features of information. However, most of the conventional deep learning-based SemCom systems focus on analog transmission and lack in compatibility with practical digital communications. This paper proposes a vector quantized-variational autoencoder (VQ-VAE) based digital SemCom system that directly transmits the semantic features and incorporates the importance-aware orthogonal frequency division multiplexing (OFDM) transmission to enhance the SemCom performance, where the VQ-VAE generates a discrete codebook shared between the transmitter and receiver. At transmitter, the latent semantic features are firstly extracted by VQ-VAE, and then the shared codebook is adopted to match these features, which are subsequently transformed into a discrete version to adapt the digital transmission. To protect the semantic information, an importance-aware OFDM transmission strategy is proposed to allocate the key features near the OFDM reference signals, where the feature importance is derived from the gradient-based method. At the receiver, the features are rematched with the shared codebook to further correct errors. Finally, experimental results demonstrate that our proposed scheme outperforms the conventional DeepSC and achieves better reconstruction performance under low SNR region.
AHPPEBot: Autonomous Robot for Tomato Harvesting based on Phenotyping and Pose Estimation
May 11, 2024



To address the limitations inherent to conventional automated harvesting robots specifically their suboptimal success rates and risk of crop damage, we design a novel bot named AHPPEBot which is capable of autonomous harvesting based on crop phenotyping and pose estimation. Specifically, In phenotyping, the detection, association, and maturity estimation of tomato trusses and individual fruits are accomplished through a multi-task YOLOv5 model coupled with a detection-based adaptive DBScan clustering algorithm. In pose estimation, we employ a deep learning model to predict seven semantic keypoints on the pedicel. These keypoints assist in the robot's path planning, minimize target contact, and facilitate the use of our specialized end effector for harvesting. In autonomous tomato harvesting experiments conducted in commercial greenhouses, our proposed robot achieved a harvesting success rate of 86.67%, with an average successful harvest time of 32.46 s, showcasing its continuous and robust harvesting capabilities. The result underscores the potential of harvesting robots to bridge the labor gap in agriculture.