 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWireless communication empowers online scheduling of partially-observable transportation multi-robot systems in a smart factory
Mar 25, 2026Achieving agile and reconfigurable production flows in smart factories depends on online multi-robot task assignment (MRTA), which requires online collision-free and congestion-free route scheduling of transportation multi-robot systems (T-MRS), e.g., collaborative automatic guided vehicles (AGVs). Due to the real-time operational requirements and dynamic interactions between T-MRS and production MRS, online scheduling under partial observability in dynamic factory environments remains a significant and under-explored challenge. This paper proposes a novel communication-enabled online scheduling framework that explicitly couples wireless machine-to-machine (M2M) networking with route scheduling, enabling AGVs to exchange intention information, e.g., planned routes, to overcome partial observations and assist complex computation of online scheduling. Specifically, we determine intelligent AGVs' intention and sensor data as new M2M traffic and tailor the retransmission-free multi-link transmission networking to meet real-time operation demands. This scheduling-oriented networking is then integrated with a simulated annealing-based MRTA scheme and a congestion-aware A*-based route scheduling method. The integrated communication and scheduling scheme allows AGVs to dynamically adjust collision-free and congestion-free routes with reduced computational overhead. Numerical experiments shows the impacts from wireless communication on the performance of T-MRS and suggest that the proposed integrated scheme significantly enhances scheduling efficiency compared to other baselines, even under high AGV load conditions and limited channel resources. Moreover, the results reveal that the scheduling-oriented wireless M2M communication design fundamentally differs from human-to-human communications, implying new technological opportunities in a wireless networked smart factory.
Coverage Performance Analysis of FAS-enhanced LoRa Wide Area Networks under both Co-SF and Inter-SF Interference
Jan 28, 2026This paper presents an analytical framework for evaluating the coverage performance of the fluid antenna system (FAS)-enhanced LoRa wide-area networks (LoRaWANs). We investigate the effects of large-scale pathloss in LoRaWAN, small-scale fading characterized by FAS, and dense interference (i.e., collision in an ALOHA-based mechanism) arising from randomly deployed end devices (EDs). Both co-spreading factor (co-SF) interference (with the same SF) and inter-SF interference (with different SFs) are introduced into the network, and their differences in physical characteristics are also considered in the analysis. Additionally, simple yet accurate statistical approximations of the FAS channel envelope and power are derived using the extreme-value theorem. Based on the approximated channel expression, the theoretical coverage probability of the proposed FAS-enhanced LoRaWAN is derived. Numerical results validate our analytical approximations by exhibiting close agreement with the exact correlation model. Notably, it is revealed that a FAS with a normalized aperture of 1 times 1 can greatly enhance network performance, in terms of both ED numbers and coverage range.
HeterCSI: Channel-Adaptive Heterogeneous CSI Pretraining Framework for Generalized Wireless Foundation Models
Jan 26, 2026Wireless foundation models promise transformative capabilities for channel state information (CSI) processing across diverse 6G network applications, yet face fundamental challenges due to the inherent dual heterogeneity of CSI across both scale and scenario dimensions. However, current pretraining approaches either constrain inputs to fixed dimensions or isolate training by scale, limiting the generalization and scalability of wireless foundation models. In this paper, we propose HeterCSI, a channel-adaptive pretraining framework that reconciles training efficiency with robust cross-scenario generalization via a new understanding of gradient dynamics in heterogeneous CSI pretraining. Our key insight reveals that CSI scale heterogeneity primarily causes destructive gradient interference, while scenario diversity actually promotes constructive gradient alignment when properly managed. Specifically, we formulate heterogeneous CSI batch construction as a partitioning optimization problem that minimizes zero-padding overhead while preserving scenario diversity. To solve this, we develop a scale-aware adaptive batching strategy that aligns CSI samples of similar scales, and design a double-masking mechanism to isolate valid signals from padding artifacts. Extensive experiments on 12 datasets demonstrate that HeterCSI establishes a generalized foundation model without scenario-specific finetuning, achieving superior average performance over full-shot baselines. Compared to the state-of-the-art zero-shot benchmark WiFo, it reduces NMSE by 7.19 dB, 4.08 dB, and 5.27 dB for CSI reconstruction, time-domain, and frequency-domain prediction, respectively. The proposed HeterCSI framework also reduces training latency by 53% compared to existing approaches while improving generalization performance by 1.53 dB on average.
Advancing LLM-Based Security Automation with Customized Group Relative Policy Optimization for Zero-Touch Networks
Dec 10, 2025Zero-Touch Networks (ZTNs) represent a transformative paradigm toward fully automated and intelligent network management, providing the scalability and adaptability required for the complexity of sixth-generation (6G) networks. However, the distributed architecture, high openness, and deep heterogeneity of 6G networks expand the attack surface and pose unprecedented security challenges. To address this, security automation aims to enable intelligent security management across dynamic and complex environments, serving as a key capability for securing 6G ZTNs. Despite its promise, implementing security automation in 6G ZTNs presents two primary challenges: 1) automating the lifecycle from security strategy generation to validation and update under real-world, parallel, and adversarial conditions, and 2) adapting security strategies to evolving threats and dynamic environments. This motivates us to propose SecLoop and SA-GRPO. SecLoop constitutes the first fully automated framework that integrates large language models (LLMs) across the entire lifecycle of security strategy generation, orchestration, response, and feedback, enabling intelligent and adaptive defenses in dynamic network environments, thus tackling the first challenge. Furthermore, we propose SA-GRPO, a novel security-aware group relative policy optimization algorithm that iteratively refines security strategies by contrasting group feedback collected from parallel SecLoop executions, thereby addressing the second challenge. Extensive real-world experiments on five benchmarks, including 11 MITRE ATT&CK processes and over 20 types of attacks, demonstrate the superiority of the proposed SecLoop and SA-GRPO. We will release our platform to the community, facilitating the advancement of security automation towards next generation communications.
A Novel Indicator for Quantifying and Minimizing Information Utility Loss of Robot Teams
Jun 17, 2025The timely exchange of information among robots within a team is vital, but it can be constrained by limited wireless capacity. The inability to deliver information promptly can result in estimation errors that impact collaborative efforts among robots. In this paper, we propose a new metric termed Loss of Information Utility (LoIU) to quantify the freshness and utility of information critical for cooperation. The metric enables robots to prioritize information transmissions within bandwidth constraints. We also propose the estimation of LoIU using belief distributions and accordingly optimize both transmission schedule and resource allocation strategy for device-to-device transmissions to minimize the time-average LoIU within a robot team. A semi-decentralized Multi-Agent Deep Deterministic Policy Gradient framework is developed, where each robot functions as an actor responsible for scheduling transmissions among its collaborators while a central critic periodically evaluates and refines the actors in response to mobility and interference. Simulations validate the effectiveness of our approach, demonstrating an enhancement of information freshness and utility by 98%, compared to alternative methods.
Convergence-Privacy-Fairness Trade-Off in Personalized Federated Learning
Jun 17, 2025Personalized federated learning (PFL), e.g., the renowned Ditto, strikes a balance between personalization and generalization by conducting federated learning (FL) to guide personalized learning (PL). While FL is unaffected by personalized model training, in Ditto, PL depends on the outcome of the FL. However, the clients' concern about their privacy and consequent perturbation of their local models can affect the convergence and (performance) fairness of PL. This paper presents PFL, called DP-Ditto, which is a non-trivial extension of Ditto under the protection of differential privacy (DP), and analyzes the trade-off among its privacy guarantee, model convergence, and performance distribution fairness. We also analyze the convergence upper bound of the personalized models under DP-Ditto and derive the optimal number of global aggregations given a privacy budget. Further, we analyze the performance fairness of the personalized models, and reveal the feasibility of optimizing DP-Ditto jointly for convergence and fairness. Experiments validate our analysis and demonstrate that DP-Ditto can surpass the DP-perturbed versions of the state-of-the-art PFL models, such as FedAMP, pFedMe, APPLE, and FedALA, by over 32.71% in fairness and 9.66% in accuracy.
Advancing Expert Specialization for Better MoE
May 28, 2025

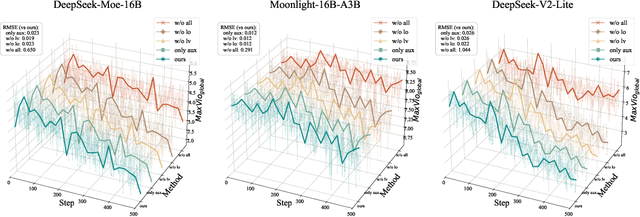

Mixture-of-Experts (MoE) models enable efficient scaling of large language models (LLMs) by activating only a subset of experts per input. However, we observe that the commonly used auxiliary load balancing loss often leads to expert overlap and overly uniform routing, which hinders expert specialization and degrades overall performance during post-training. To address this, we propose a simple yet effective solution that introduces two complementary objectives: (1) an orthogonality loss to encourage experts to process distinct types of tokens, and (2) a variance loss to encourage more discriminative routing decisions. Gradient-level analysis demonstrates that these objectives are compatible with the existing auxiliary loss and contribute to optimizing the training process. Experimental results over various model architectures and across multiple benchmarks show that our method significantly enhances expert specialization. Notably, our method improves classic MoE baselines with auxiliary loss by up to 23.79%, while also maintaining load balancing in downstream tasks, without any architectural modifications or additional components. We will release our code to contribute to the community.
220 GHz RIS-Aided Multi-user Terahertz Communication System: Prototype Design and Over-the-Air Experimental Trials
Feb 24, 2025Terahertz (THz) communication technology is regarded as a promising enabler for achieving ultra-high data rate transmission in next-generation communication systems. To mitigate the high path loss in THz systems, the transmitting beams are typically narrow and highly directional, which makes it difficult for a single beam to serve multiple users simultaneously. To address this challenge, reconfigurable intelligent surfaces (RIS), which can dynamically manipulate the wireless propagation environment, have been integrated into THz communication systems to extend coverage. Existing works mostly remain theoretical analysis and simulation, while prototype validation of RIS-assisted THz communication systems is scarce. In this paper, we designed a liquid crystal-based RIS operating at 220 GHz supporting both single-user and multi-user communication scenarios, followed by a RIS-aided THz communication system prototype. To enhance the system performance, we developed a beamforming method including a real-time power feedback control, which is compatible with both single-beam and multibeam modes. To support simultaneous multi-user transmission, we designed an OFDM-based resource allocation scheme. In our experiments, the received power gain with RIS is no less than 10 dB in the single-beam mode, and no less than 5 dB in the multi-beam mode. With the assistance of RIS, the achievable rate of the system could reach 2.341 Gbps with 3 users sharing 400 MHz bandwidth and the bit error rate (BER) of the system decreased sharply. Finally, an image transmission experiment was conducted to vividly show that the receiver could recover the transmitted information correctly with the help of RIS. The experimental results also demonstrated that the received signal quality was enhanced through power feedback adjustments.
On Performance of LoRa Fluid Antenna Systems
Feb 21, 2025This paper advocates a fluid antenna system (FAS) assisting long-range communication (LoRa-FAS) for Internet-of-Things (IoT) applications. Our focus is on pilot sequence overhead and placement for FAS. Specifically, we consider embedding pilot sequences within symbols to reduce the equivalent symbol error rate (SER), leveraging the fact that the pilot sequences do not convey source information and correlation detection at the LoRa receiver needs not be performed across the entire symbol. We obtain closed-form approximations for the probability density function (PDF) and cumulative distribution function (CDF) of the FAS channel, assuming perfect channel state information (CSI). Moreover, the approximate SER, hence the bit error rate (BER), of the proposed LoRa-FAS is derived. Simulation results indicate that substantial SER gains can be achieved by FAS within the LoRa framework, even with a limited size of FAS. Furthermore, our analytical results align well with that of the Clarke's exact spatial correlation model. Finally, the correlation factor for the block correlation model should be selected as the proportion of the exact correlation matrix's eigenvalues greater than $1$.
Overview of AI and Communication for 6G Network: Fundamentals, Challenges, and Future Research Opportunities
Dec 19, 2024



With the increasing demand for seamless connectivity and intelligent communication, the integration of artificial intelligence (AI) and communication for sixth-generation (6G) network is emerging as a revolutionary architecture. This paper presents a comprehensive overview of AI and communication for 6G networks, emphasizing their foundational principles, inherent challenges, and future research opportunities. We commence with a retrospective analysis of AI and the evolution of large-scale AI models, underscoring their pivotal roles in shaping contemporary communication technologies. The discourse then transitions to a detailed exposition of the envisioned integration of AI within 6G networks, delineated across three progressive developmental stages. The initial stage, AI for Network, focuses on employing AI to augment network performance, optimize efficiency, and enhance user service experiences. The subsequent stage, Network for AI, highlights the role of the network in facilitating and buttressing AI operations and presents key enabling technologies, including digital twins for AI and semantic communication. In the final stage, AI as a Service, it is anticipated that future 6G networks will innately provide AI functions as services and support application scenarios like immersive communication and intelligent industrial robots. Specifically, we have defined the quality of AI service, which refers to the measurement framework system of AI services within the network. In addition to these developmental stages, we thoroughly examine the standardization processes pertinent to AI in network contexts, highlighting key milestones and ongoing efforts. Finally, we outline promising future research opportunities that could drive the evolution and refinement of AI and communication for 6G, positioning them as a cornerstone of next-generation communication infrastructure.