 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAPT: Confusion-Aware Prompt Tuning for Reducing Vision-Language Misalignment
Mar 03, 2026Vision-language models like CLIP have achieved remarkable progress in cross-modal representation learning, yet suffer from systematic misclassifications among visually and semantically similar categories. We observe that such confusion patterns are not random but persistently occur between specific category pairs, revealing the model's intrinsic bias and limited fine-grained discriminative ability. To address this, we propose CAPT, a Confusion-Aware Prompt Tuning framework that enables models to learn from their own misalignment. Specifically, we construct a Confusion Bank to explicitly model stable confusion relationships across categories and misclassified samples. On this basis, we introduce a Semantic Confusion Miner (SEM) to capture global inter-class confusion through semantic difference and commonality prompts, and a Sample Confusion Miner (SAM) to retrieve representative misclassified instances from the bank and capture sample-level cues through a Diff-Manner Adapter that integrates global and local contexts. To further unify confusion information across different granularities, a Multi-Granularity Difference Expert (MGDE) module is designed to jointly leverage semantic- and sample-level experts for more robust confusion-aware reasoning. Extensive experiments on 11 benchmark datasets demonstrate that our method significantly reduces confusion-induced errors while enhancing the discriminability and generalization of both base and novel classes, successfully resolving 50.72 percent of confusable sample pairs. Code will be released at https://github.com/greatest-gourmet/CAPT.
SciFig: Towards Automating Scientific Figure Generation
Jan 07, 2026Creating high-quality figures and visualizations for scientific papers is a time-consuming task that requires both deep domain knowledge and professional design skills. Despite over 2.5 million scientific papers published annually, the figure generation process remains largely manual. We introduce $\textbf{SciFig}$, an end-to-end AI agent system that generates publication-ready pipeline figures directly from research paper texts. SciFig uses a hierarchical layout generation strategy, which parses research descriptions to identify component relationships, groups related elements into functional modules, and generates inter-module connections to establish visual organization. Furthermore, an iterative chain-of-thought (CoT) feedback mechanism progressively improves layouts through multiple rounds of visual analysis and reasoning. We introduce a rubric-based evaluation framework that analyzes 2,219 real scientific figures to extract evaluation rubrics and automatically generates comprehensive evaluation criteria. SciFig demonstrates remarkable performance: achieving 70.1$\%$ overall quality on dataset-level evaluation and 66.2$\%$ on paper-specific evaluation, and consistently high scores across metrics such as visual clarity, structural organization, and scientific accuracy. SciFig figure generation pipeline and our evaluation benchmark will be open-sourced.
Generative forecasting of brain activity enhances Alzheimer's classification and interpretation
Oct 30, 2024
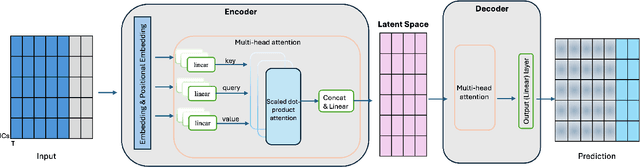
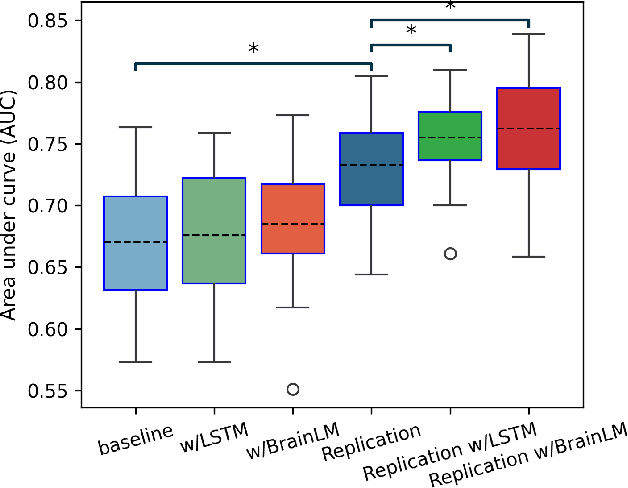
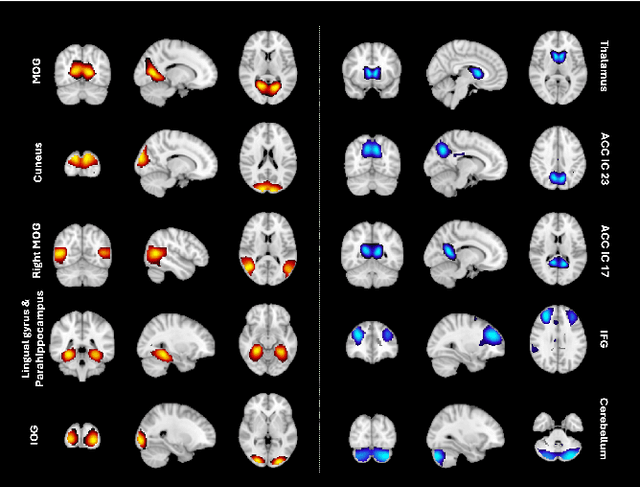
Understanding the relationship between cognition and intrinsic brain activity through purely data-driven approaches remains a significant challenge in neuroscience. Resting-state functional magnetic resonance imaging (rs-fMRI) offers a non-invasive method to monitor regional neural activity, providing a rich and complex spatiotemporal data structure. Deep learning has shown promise in capturing these intricate representations. However, the limited availability of large datasets, especially for disease-specific groups such as Alzheimer's Disease (AD), constrains the generalizability of deep learning models. In this study, we focus on multivariate time series forecasting of independent component networks derived from rs-fMRI as a form of data augmentation, using both a conventional LSTM-based model and the novel Transformer-based BrainLM model. We assess their utility in AD classification, demonstrating how generative forecasting enhances classification performance. Post-hoc interpretation of BrainLM reveals class-specific brain network sensitivities associated with AD.
ContextBLIP: Doubly Contextual Alignment for Contrastive Image Retrieval from Linguistically Complex Descriptions
May 29, 2024Image retrieval from contextual descriptions (IRCD) aims to identify an image within a set of minimally contrastive candidates based on linguistically complex text. Despite the success of VLMs, they still significantly lag behind human performance in IRCD. The main challenges lie in aligning key contextual cues in two modalities, where these subtle cues are concealed in tiny areas of multiple contrastive images and within the complex linguistics of textual descriptions. This motivates us to propose ContextBLIP, a simple yet effective method that relies on a doubly contextual alignment scheme for challenging IRCD. Specifically, 1) our model comprises a multi-scale adapter, a matching loss, and a text-guided masking loss. The adapter learns to capture fine-grained visual cues. The two losses enable iterative supervision for the adapter, gradually highlighting the focal patches of a single image to the key textual cues. We term such a way as intra-contextual alignment. 2) Then, ContextBLIP further employs an inter-context encoder to learn dependencies among candidates, facilitating alignment between the text to multiple images. We term this step as inter-contextual alignment. Consequently, the nuanced cues concealed in each modality can be effectively aligned. Experiments on two benchmarks show the superiority of our method. We observe that ContextBLIP can yield comparable results with GPT-4V, despite involving about 7,500 times fewer parameters.
Improving age prediction: Utilizing LSTM-based dynamic forecasting for data augmentation in multivariate time series analysis
Dec 11, 2023

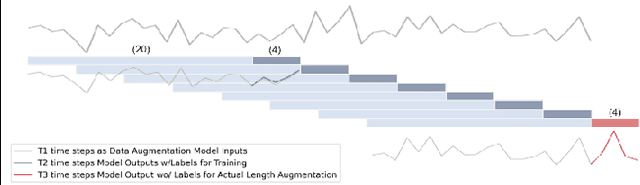

The high dimensionality and complexity of neuroimaging data necessitate large datasets to develop robust and high-performing deep learning models. However, the neuroimaging field is notably hampered by the scarcity of such datasets. In this work, we proposed a data augmentation and validation framework that utilizes dynamic forecasting with Long Short-Term Memory (LSTM) networks to enrich datasets. We extended multivariate time series data by predicting the time courses of independent component networks (ICNs) in both one-step and recursive configurations. The effectiveness of these augmented datasets was then compared with the original data using various deep learning models designed for chronological age prediction tasks. The results suggest that our approach improves model performance, providing a robust solution to overcome the challenges presented by the limited size of neuroimaging datasets.
Clicking Matters:Towards Interactive Human Parsing
Nov 11, 2021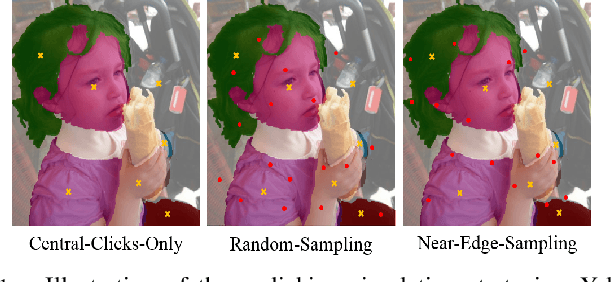
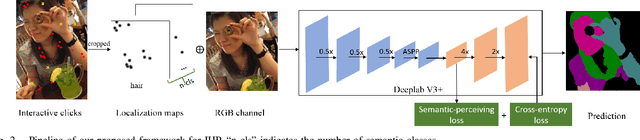
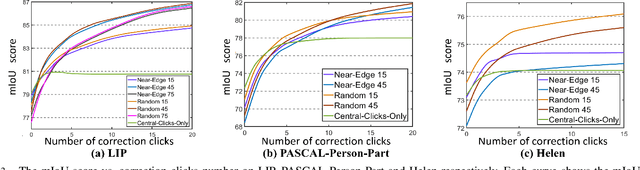
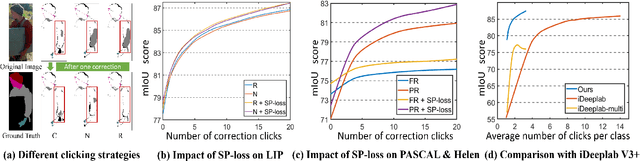
In this work, we focus on Interactive Human Parsing (IHP), which aims to segment a human image into multiple human body parts with guidance from users' interactions. This new task inherits the class-aware property of human parsing, which cannot be well solved by traditional interactive image segmentation approaches that are generally class-agnostic. To tackle this new task, we first exploit user clicks to identify different human parts in the given image. These clicks are subsequently transformed into semantic-aware localization maps, which are concatenated with the RGB image to form the input of the segmentation network and generate the initial parsing result. To enable the network to better perceive user's purpose during the correction process, we investigate several principal ways for the refinement, and reveal that random-sampling-based click augmentation is the best way for promoting the correction effectiveness. Furthermore, we also propose a semantic-perceiving loss (SP-loss) to augment the training, which can effectively exploit the semantic relationships of clicks for better optimization. To the best knowledge, this work is the first attempt to tackle the human parsing task under the interactive setting. Our IHP solution achieves 85\% mIoU on the benchmark LIP, 80\% mIoU on PASCAL-Person-Part and CIHP, 75\% mIoU on Helen with only 1.95, 3.02, 2.84 and 1.09 clicks per class respectively. These results demonstrate that we can simply acquire high-quality human parsing masks with only a few human effort. We hope this work can motivate more researchers to develop data-efficient solutions to IHP in the future.
Improved Detection of Adversarial Images Using Deep Neural Networks
Jul 10, 2020



Machine learning techniques are immensely deployed in both industry and academy. Recent studies indicate that machine learning models used for classification tasks are vulnerable to adversarial examples, which limits the usage of applications in the fields with high precision requirements. We propose a new approach called Feature Map Denoising to detect the adversarial inputs and show the performance of detection on the mixed dataset consisting of adversarial examples generated by different attack algorithms, which can be used to associate with any pre-trained DNNs at a low cost. Wiener filter is also introduced as the denoise algorithm to the defense model, which can further improve performance. Experimental results indicate that good accuracy of detecting the adversarial examples can be achieved through our Feature Map Denoising algorithm.