 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMFineReason: Closing the Multimodal Reasoning Gap via Open Data-Centric Methods
Jan 29, 2026Recent advances in Vision Language Models (VLMs) have driven significant progress in visual reasoning. However, open-source VLMs still lag behind proprietary systems, largely due to the lack of high-quality reasoning data. Existing datasets offer limited coverage of challenging domains such as STEM diagrams and visual puzzles, and lack consistent, long-form Chain-of-Thought (CoT) annotations essential for eliciting strong reasoning capabilities. To bridge this gap, we introduce MMFineReason, a large-scale multimodal reasoning dataset comprising 1.8M samples and 5.1B solution tokens, featuring high-quality reasoning annotations distilled from Qwen3-VL-235B-A22B-Thinking. The dataset is established via a systematic three-stage pipeline: (1) large-scale data collection and standardization, (2) CoT rationale generation, and (3) comprehensive selection based on reasoning quality and difficulty awareness. The resulting dataset spans STEM problems, visual puzzles, games, and complex diagrams, with each sample annotated with visually grounded reasoning traces. We fine-tune Qwen3-VL-Instruct on MMFineReason to develop MMFineReason-2B/4B/8B versions. Our models establish new state-of-the-art results for their size class. Notably, MMFineReason-4B succesfully surpasses Qwen3-VL-8B-Thinking, and MMFineReason-8B even outperforms Qwen3-VL-30B-A3B-Thinking while approaching Qwen3-VL-32B-Thinking, demonstrating remarkable parameter efficiency. Crucially, we uncover a "less is more" phenomenon via our difficulty-aware filtering strategy: a subset of just 7\% (123K samples) achieves performance comparable to the full dataset. Notably, we reveal a synergistic effect where reasoning-oriented data composition simultaneously boosts general capabilities.
ChartVerse: Scaling Chart Reasoning via Reliable Programmatic Synthesis from Scratch
Jan 20, 2026Chart reasoning is a critical capability for Vision Language Models (VLMs). However, the development of open-source models is severely hindered by the lack of high-quality training data. Existing datasets suffer from a dual challenge: synthetic charts are often simplistic and repetitive, while the associated QA pairs are prone to hallucinations and lack the reasoning depth required for complex tasks. To bridge this gap, we propose ChartVerse, a scalable framework designed to synthesize complex charts and reliable reasoning data from scratch. (1) To address the bottleneck of simple patterns, we first introduce Rollout Posterior Entropy (RPE), a novel metric that quantifies chart complexity. Guided by RPE, we develop complexity-aware chart coder to autonomously synthesize diverse, high-complexity charts via executable programs. (2) To guarantee reasoning rigor, we develop truth-anchored inverse QA synthesis. Diverging from standard generation, we adopt an answer-first paradigm: we extract deterministic answers directly from the source code, generate questions conditional on these anchors, and enforce strict consistency verification. To further elevate difficulty and reasoning depth, we filter samples based on model fail-rate and distill high-quality Chain-of-Thought (CoT) reasoning. We curate ChartVerse-SFT-600K and ChartVerse-RL-40K using Qwen3-VL-30B-A3B-Thinking as the teacher. Experimental results demonstrate that ChartVerse-8B achieves state-of-the-art performance, notably surpassing its teacher and rivaling the stronger Qwen3-VL-32B-Thinking.
Scientific Image Synthesis: Benchmarking, Methodologies, and Downstream Utility
Jan 17, 2026While synthetic data has proven effective for improving scientific reasoning in the text domain, multimodal reasoning remains constrained by the difficulty of synthesizing scientifically rigorous images. Existing Text-to-Image (T2I) models often produce outputs that are visually plausible yet scientifically incorrect, resulting in a persistent visual-logic divergence that limits their value for downstream reasoning. Motivated by recent advances in next-generation T2I models, we conduct a systematic study of scientific image synthesis across generation paradigms, evaluation, and downstream use. We analyze both direct pixel-based generation and programmatic synthesis, and propose ImgCoder, a logic-driven framework that follows an explicit "understand - plan - code" workflow to improve structural precision. To rigorously assess scientific correctness, we introduce SciGenBench, which evaluates generated images based on information utility and logical validity. Our evaluation reveals systematic failure modes in pixel-based models and highlights a fundamental expressiveness-precision trade-off. Finally, we show that fine-tuning Large Multimodal Models (LMMs) on rigorously verified synthetic scientific images yields consistent reasoning gains, with potential scaling trends analogous to the text domain, validating high-fidelity scientific synthesis as a viable path to unlocking massive multimodal reasoning capabilities.
OpenDataArena: A Fair and Open Arena for Benchmarking Post-Training Dataset Value
Dec 16, 2025
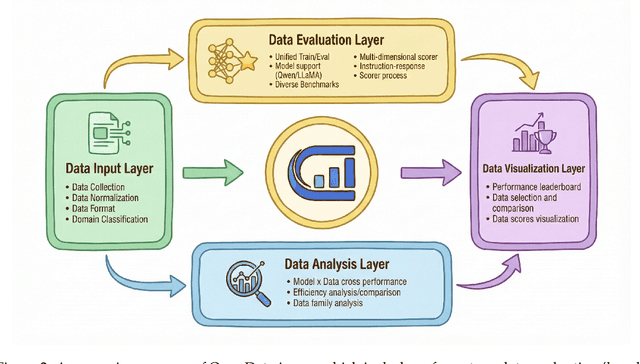

The rapid evolution of Large Language Models (LLMs) is predicated on the quality and diversity of post-training datasets. However, a critical dichotomy persists: while models are rigorously benchmarked, the data fueling them remains a black box--characterized by opaque composition, uncertain provenance, and a lack of systematic evaluation. This opacity hinders reproducibility and obscures the causal link between data characteristics and model behaviors. To bridge this gap, we introduce OpenDataArena (ODA), a holistic and open platform designed to benchmark the intrinsic value of post-training data. ODA establishes a comprehensive ecosystem comprising four key pillars: (i) a unified training-evaluation pipeline that ensures fair, open comparisons across diverse models (e.g., Llama, Qwen) and domains; (ii) a multi-dimensional scoring framework that profiles data quality along tens of distinct axes; (iii) an interactive data lineage explorer to visualize dataset genealogy and dissect component sources; and (iv) a fully open-source toolkit for training, evaluation, and scoring to foster data research. Extensive experiments on ODA--covering over 120 training datasets across multiple domains on 22 benchmarks, validated by more than 600 training runs and 40 million processed data points--reveal non-trivial insights. Our analysis uncovers the inherent trade-offs between data complexity and task performance, identifies redundancy in popular benchmarks through lineage tracing, and maps the genealogical relationships across datasets. We release all results, tools, and configurations to democratize access to high-quality data evaluation. Rather than merely expanding a leaderboard, ODA envisions a shift from trial-and-error data curation to a principled science of Data-Centric AI, paving the way for rigorous studies on data mixing laws and the strategic composition of foundation models.
Can One Domain Help Others? A Data-Centric Study on Multi-Domain Reasoning via Reinforcement Learning
Jul 23, 2025Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a powerful paradigm for enhancing the reasoning capabilities of LLMs. Existing research has predominantly concentrated on isolated reasoning domains such as mathematical problem-solving, coding tasks, or logical reasoning. However, real world reasoning scenarios inherently demand an integrated application of multiple cognitive skills. Despite this, the interplay among these reasoning skills under reinforcement learning remains poorly understood. To bridge this gap, we present a systematic investigation of multi-domain reasoning within the RLVR framework, explicitly focusing on three primary domains: mathematical reasoning, code generation, and logical puzzle solving. We conduct a comprehensive study comprising four key components: (1) Leveraging the GRPO algorithm and the Qwen-2.5-7B model family, our study thoroughly evaluates the models' in-domain improvements and cross-domain generalization capabilities when trained on single-domain datasets. (2) Additionally, we examine the intricate interactions including mutual enhancements and conflicts that emerge during combined cross-domain training. (3) To further understand the influence of SFT on RL, we also analyze and compare performance differences between base and instruct models under identical RL configurations. (4) Furthermore, we delve into critical RL training details, systematically exploring the impacts of curriculum learning strategies, variations in reward design, and language-specific factors. Through extensive experiments, our results offer significant insights into the dynamics governing domain interactions, revealing key factors influencing both specialized and generalizable reasoning performance. These findings provide valuable guidance for optimizing RL methodologies to foster comprehensive, multi-domain reasoning capabilities in LLMs.
CipherBank: Exploring the Boundary of LLM Reasoning Capabilities through Cryptography Challenges
Apr 27, 2025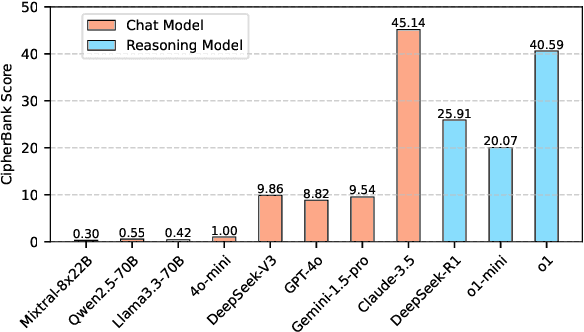



Large language models (LLMs) have demonstrated remarkable capabilities, especially the recent advancements in reasoning, such as o1 and o3, pushing the boundaries of AI. Despite these impressive achievements in mathematics and coding, the reasoning abilities of LLMs in domains requiring cryptographic expertise remain underexplored. In this paper, we introduce CipherBank, a comprehensive benchmark designed to evaluate the reasoning capabilities of LLMs in cryptographic decryption tasks. CipherBank comprises 2,358 meticulously crafted problems, covering 262 unique plaintexts across 5 domains and 14 subdomains, with a focus on privacy-sensitive and real-world scenarios that necessitate encryption. From a cryptographic perspective, CipherBank incorporates 3 major categories of encryption methods, spanning 9 distinct algorithms, ranging from classical ciphers to custom cryptographic techniques. We evaluate state-of-the-art LLMs on CipherBank, e.g., GPT-4o, DeepSeek-V3, and cutting-edge reasoning-focused models such as o1 and DeepSeek-R1. Our results reveal significant gaps in reasoning abilities not only between general-purpose chat LLMs and reasoning-focused LLMs but also in the performance of current reasoning-focused models when applied to classical cryptographic decryption tasks, highlighting the challenges these models face in understanding and manipulating encrypted data. Through detailed analysis and error investigations, we provide several key observations that shed light on the limitations and potential improvement areas for LLMs in cryptographic reasoning. These findings underscore the need for continuous advancements in LLM reasoning capabilities.
MathFusion: Enhancing Mathematic Problem-solving of LLM through Instruction Fusion
Mar 20, 2025Large Language Models (LLMs) have shown impressive progress in mathematical reasoning. While data augmentation is promising to enhance mathematical problem-solving ability, current approaches are predominantly limited to instance-level modifications-such as rephrasing or generating syntactic variations-which fail to capture and leverage the intrinsic relational structures inherent in mathematical knowledge. Inspired by human learning processes, where mathematical proficiency develops through systematic exposure to interconnected concepts, we introduce MathFusion, a novel framework that enhances mathematical reasoning through cross-problem instruction synthesis. MathFusion implements this through three fusion strategies: (1) sequential fusion, which chains related problems to model solution dependencies; (2) parallel fusion, which combines analogous problems to reinforce conceptual understanding; and (3) conditional fusion, which creates context-aware selective problems to enhance reasoning flexibility. By applying these strategies, we generate a new dataset, \textbf{MathFusionQA}, followed by fine-tuning models (DeepSeekMath-7B, Mistral-7B, Llama3-8B) on it. Experimental results demonstrate that MathFusion achieves substantial improvements in mathematical reasoning while maintaining high data efficiency, boosting performance by 18.0 points in accuracy across diverse benchmarks while requiring only 45K additional synthetic instructions, representing a substantial improvement over traditional single-instruction approaches. Our datasets, models, and code are publicly available at https://github.com/QizhiPei/mathfusion.
MetaLadder: Ascending Mathematical Solution Quality via Analogical-Problem Reasoning Transfer
Mar 19, 2025Large Language Models (LLMs) have demonstrated promising capabilities in solving mathematical reasoning tasks, leveraging Chain-of-Thought (CoT) data as a vital component in guiding answer generation. Current paradigms typically generate CoT and answers directly for a given problem, diverging from human problem-solving strategies to some extent. Humans often solve problems by recalling analogous cases and leveraging their solutions to reason about the current task. Inspired by this cognitive process, we propose \textbf{MetaLadder}, a novel framework that explicitly prompts LLMs to recall and reflect on meta-problems, those structurally or semantically analogous problems, alongside their CoT solutions before addressing the target problem. Additionally, we introduce a problem-restating mechanism to enhance the model's comprehension of the target problem by regenerating the original question, which further improves reasoning accuracy. Therefore, the model can achieve reasoning transfer from analogical problems, mimicking human-like "learning from examples" and generalization abilities. Extensive experiments on mathematical benchmarks demonstrate that our MetaLadder significantly boosts LLMs' problem-solving accuracy, largely outperforming standard CoT-based methods (\textbf{10.3\%} accuracy gain) and other methods. Our code and data has been released at https://github.com/LHL3341/MetaLadder.
Where am I? Cross-View Geo-localization with Natural Language Descriptions
Dec 22, 2024Cross-view geo-localization identifies the locations of street-view images by matching them with geo-tagged satellite images or OSM. However, most studies focus on image-to-image retrieval, with fewer addressing text-guided retrieval, a task vital for applications like pedestrian navigation and emergency response. In this work, we introduce a novel task for cross-view geo-localization with natural language descriptions, which aims to retrieve corresponding satellite images or OSM database based on scene text. To support this task, we construct the CVG-Text dataset by collecting cross-view data from multiple cities and employing a scene text generation approach that leverages the annotation capabilities of Large Multimodal Models to produce high-quality scene text descriptions with localization details.Additionally, we propose a novel text-based retrieval localization method, CrossText2Loc, which improves recall by 10% and demonstrates excellent long-text retrieval capabilities. In terms of explainability, it not only provides similarity scores but also offers retrieval reasons. More information can be found at https://yejy53.github.io/CVG-Text/.
LOKI: A Comprehensive Synthetic Data Detection Benchmark using Large Multimodal Models
Oct 13, 2024
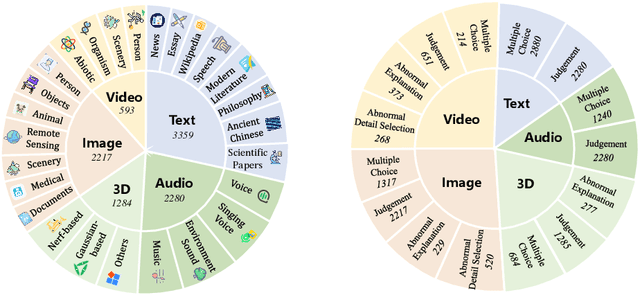

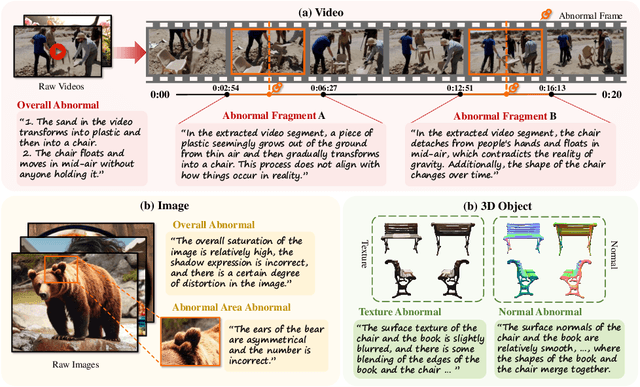
With the rapid development of AI-generated content, the future internet may be inundated with synthetic data, making the discrimination of authentic and credible multimodal data increasingly challenging. Synthetic data detection has thus garnered widespread attention, and the performance of large multimodal models (LMMs) in this task has attracted significant interest. LMMs can provide natural language explanations for their authenticity judgments, enhancing the explainability of synthetic content detection. Simultaneously, the task of distinguishing between real and synthetic data effectively tests the perception, knowledge, and reasoning capabilities of LMMs. In response, we introduce LOKI, a novel benchmark designed to evaluate the ability of LMMs to detect synthetic data across multiple modalities. LOKI encompasses video, image, 3D, text, and audio modalities, comprising 18K carefully curated questions across 26 subcategories with clear difficulty levels. The benchmark includes coarse-grained judgment and multiple-choice questions, as well as fine-grained anomaly selection and explanation tasks, allowing for a comprehensive analysis of LMMs. We evaluated 22 open-source LMMs and 6 closed-source models on LOKI, highlighting their potential as synthetic data detectors and also revealing some limitations in the development of LMM capabilities. More information about LOKI can be found at https://opendatalab.github.io/LOKI/