 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniLegs: Universal Multi-Legged Robot Control through Morphology-Agnostic Policy Distillation
Jul 30, 2025Developing controllers that generalize across diverse robot morphologies remains a significant challenge in legged locomotion. Traditional approaches either create specialized controllers for each morphology or compromise performance for generality. This paper introduces a two-stage teacher-student framework that bridges this gap through policy distillation. First, we train specialized teacher policies optimized for individual morphologies, capturing the unique optimal control strategies for each robot design. Then, we distill this specialized expertise into a single Transformer-based student policy capable of controlling robots with varying leg configurations. Our experiments across five distinct legged morphologies demonstrate that our approach preserves morphology-specific optimal behaviors, with the Transformer architecture achieving 94.47\% of teacher performance on training morphologies and 72.64\% on unseen robot designs. Comparative analysis reveals that Transformer-based architectures consistently outperform MLP baselines by leveraging attention mechanisms to effectively model joint relationships across different kinematic structures. We validate our approach through successful deployment on a physical quadruped robot, demonstrating the practical viability of our morphology-agnostic control framework. This work presents a scalable solution for developing universal legged robot controllers that maintain near-optimal performance while generalizing across diverse morphologies.
IDEAL: Data Equilibrium Adaptation for Multi-Capability Language Model Alignment
May 19, 2025



Large Language Models (LLMs) have achieved impressive performance through Supervised Fine-tuning (SFT) on diverse instructional datasets. When training on multiple capabilities simultaneously, the mixture training dataset, governed by volumes of data from different domains, is a critical factor that directly impacts the final model's performance. Unlike many studies that focus on enhancing the quality of training datasets through data selection methods, few works explore the intricate relationship between the compositional quantity of mixture training datasets and the emergent capabilities of LLMs. Given the availability of a high-quality multi-domain training dataset, understanding the impact of data from each domain on the model's overall capabilities is crucial for preparing SFT data and training a well-balanced model that performs effectively across diverse domains. In this work, we introduce IDEAL, an innovative data equilibrium adaptation framework designed to effectively optimize volumes of data from different domains within mixture SFT datasets, thereby enhancing the model's alignment and performance across multiple capabilities. IDEAL employs a gradient-based approach to iteratively refine the training data distribution, dynamically adjusting the volumes of domain-specific data based on their impact on downstream task performance. By leveraging this adaptive mechanism, IDEAL ensures a balanced dataset composition, enabling the model to achieve robust generalization and consistent proficiency across diverse tasks. Experiments across different capabilities demonstrate that IDEAL outperforms conventional uniform data allocation strategies, achieving a comprehensive improvement of approximately 7% in multi-task evaluation scores.
CipherBank: Exploring the Boundary of LLM Reasoning Capabilities through Cryptography Challenges
Apr 27, 2025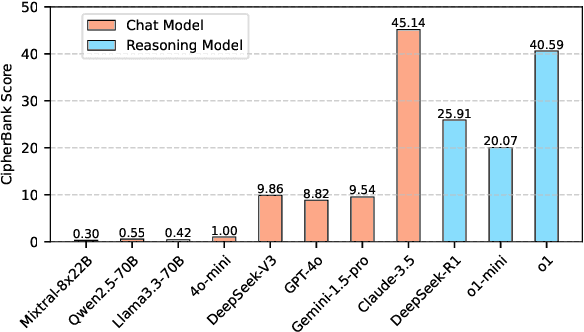



Large language models (LLMs) have demonstrated remarkable capabilities, especially the recent advancements in reasoning, such as o1 and o3, pushing the boundaries of AI. Despite these impressive achievements in mathematics and coding, the reasoning abilities of LLMs in domains requiring cryptographic expertise remain underexplored. In this paper, we introduce CipherBank, a comprehensive benchmark designed to evaluate the reasoning capabilities of LLMs in cryptographic decryption tasks. CipherBank comprises 2,358 meticulously crafted problems, covering 262 unique plaintexts across 5 domains and 14 subdomains, with a focus on privacy-sensitive and real-world scenarios that necessitate encryption. From a cryptographic perspective, CipherBank incorporates 3 major categories of encryption methods, spanning 9 distinct algorithms, ranging from classical ciphers to custom cryptographic techniques. We evaluate state-of-the-art LLMs on CipherBank, e.g., GPT-4o, DeepSeek-V3, and cutting-edge reasoning-focused models such as o1 and DeepSeek-R1. Our results reveal significant gaps in reasoning abilities not only between general-purpose chat LLMs and reasoning-focused LLMs but also in the performance of current reasoning-focused models when applied to classical cryptographic decryption tasks, highlighting the challenges these models face in understanding and manipulating encrypted data. Through detailed analysis and error investigations, we provide several key observations that shed light on the limitations and potential improvement areas for LLMs in cryptographic reasoning. These findings underscore the need for continuous advancements in LLM reasoning capabilities.
MathFusion: Enhancing Mathematic Problem-solving of LLM through Instruction Fusion
Mar 20, 2025Large Language Models (LLMs) have shown impressive progress in mathematical reasoning. While data augmentation is promising to enhance mathematical problem-solving ability, current approaches are predominantly limited to instance-level modifications-such as rephrasing or generating syntactic variations-which fail to capture and leverage the intrinsic relational structures inherent in mathematical knowledge. Inspired by human learning processes, where mathematical proficiency develops through systematic exposure to interconnected concepts, we introduce MathFusion, a novel framework that enhances mathematical reasoning through cross-problem instruction synthesis. MathFusion implements this through three fusion strategies: (1) sequential fusion, which chains related problems to model solution dependencies; (2) parallel fusion, which combines analogous problems to reinforce conceptual understanding; and (3) conditional fusion, which creates context-aware selective problems to enhance reasoning flexibility. By applying these strategies, we generate a new dataset, \textbf{MathFusionQA}, followed by fine-tuning models (DeepSeekMath-7B, Mistral-7B, Llama3-8B) on it. Experimental results demonstrate that MathFusion achieves substantial improvements in mathematical reasoning while maintaining high data efficiency, boosting performance by 18.0 points in accuracy across diverse benchmarks while requiring only 45K additional synthetic instructions, representing a substantial improvement over traditional single-instruction approaches. Our datasets, models, and code are publicly available at https://github.com/QizhiPei/mathfusion.
Stochastic Trajectory Optimization for Demonstration Imitation
Aug 07, 2024


Humans often learn new skills by imitating the experts and gradually developing their proficiency. In this work, we introduce Stochastic Trajectory Optimization for Demonstration Imitation (STODI), a trajectory optimization framework for robots to imitate the shape of demonstration trajectories with improved dynamic performance. Consistent with the human learning process, demonstration imitation serves as an initial step, while trajectory optimization aims to enhance robot motion performance. By generating random noise and constructing proper cost functions, the STODI effectively explores and exploits generated noisy trajectories while preserving the demonstration shape characteristics. We employ three metrics to measure the similarity of trajectories in both the time and frequency domains to help with demonstration imitation. Theoretical analysis reveals relationships among these metrics, emphasizing the benefits of frequency-domain analysis for specific tasks. Experiments on a 7-DOF robotic arm in the PyBullet simulator validate the efficacy of the STODI framework, showcasing the improved optimization performance and stability compared to previous methods.
HiCRISP: A Hierarchical Closed-Loop Robotic Intelligent Self-Correction Planner
Sep 21, 2023



The integration of Large Language Models (LLMs) into robotics has revolutionized human-robot interactions and autonomous task planning. However, these systems are often unable to self-correct during the task execution, which hinders their adaptability in dynamic real-world environments. To address this issue, we present a Hierarchical Closed-loop Robotic Intelligent Self-correction Planner (HiCRISP), an innovative framework that enables robots to correct errors within individual steps during the task execution. HiCRISP actively monitors and adapts the task execution process, addressing both high-level planning and low-level action errors. Extensive benchmark experiments, encompassing virtual and real-world scenarios, showcase HiCRISP's exceptional performance, positioning it as a promising solution for robotic task planning with LLMs.