 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuntimeSlicer: Towards Generalizable Unified Runtime State Representation for Failure Management
Mar 23, 2026Modern software systems operate at unprecedented scale and complexity, where effective failure management is critical yet increasingly challenging. Metrics, traces, and logs provide complementary views of system runtime behavior, but existing failure management approaches typically rely on task-oriented pipelines that tightly couple modality-specific preprocessing, representation learning, and downstream models, resulting in limited generalization across tasks and systems. To fill this gap, we propose RuntimeSlicer, a unified runtime state representation model towards generalizable failure management. RuntimeSlicer pre-trains a task-agnostic representation model that directly encodes metrics, traces, and logs into a single, aligned system-state embedding capturing the holistic runtime condition of the system. To train RuntimeSlicer, we introduce Unified Runtime Contrastive Learning, which integrates heterogeneous training data sources and optimizes complementary objectives for cross-modality alignment and temporal consistency. Building upon the learned system-state embeddings, we further propose State-Aware Task-Oriented Tuning, which performs unsupervised partitioning of runtime states and enables state-conditioned adaptation for downstream tasks. This design allows lightweight task-oriented models to be trained on top of the unified embedding without redesigning modality-specific encoders or preprocessing pipelines. Preliminary experiments on the AIOps 2022 dataset demonstrate the feasibility and effectiveness of RuntimeSlicer for system state modeling and failure management tasks.
Efficient Failure Management for Multi-Agent Systems with Reasoning Trace Representation
Mar 23, 2026Large Language Models (LLM)-based Multi-Agent Systems (MASs) have emerged as a new paradigm in software system design, increasingly demonstrating strong reasoning and collaboration capabilities. As these systems become more complex and autonomous, effective failure management is essential to ensure reliability and availability. However, existing approaches often rely on per-trace reasoning, which leads to low efficiency, and neglect historical failure patterns, limiting diagnostic accuracy. In this paper, we conduct a preliminary empirical study to demonstrate the necessity, potential, and challenges of leveraging historical failure patterns to enhance failure management in MASs. Building on this insight, we propose \textbf{EAGER}, an efficient failure management framework for multi-agent systems based on reasoning trace representation. EAGER employs unsupervised reasoning-scoped contrastive learning to encode both intra-agent reasoning and inter-agent coordination, enabling real-time step-wise failure detection, diagnosis, and reflexive mitigation guided by historical failure knowledge. Preliminary evaluations on three open-source MASs demonstrate the effectiveness of EAGER and highlight promising directions for future research in reliable multi-agent system operations.
Advancing Cancer Prognosis with Hierarchical Fusion of Genomic, Proteomic and Pathology Imaging Data from a Systems Biology Perspective
Mar 14, 2026To enhance the precision of cancer prognosis, recent research has increasingly focused on multimodal survival methods by integrating genomic data and histology images. However, current approaches overlook the fact that the proteome serves as an intermediate layer bridging genomic alterations and histopathological features while providing complementary biological information essential for survival prediction. This biological reality exposes another architectural limitation: existing integrative analysis studies fuse these heterogeneous data sources in a flat manner that fails to capture their inherent biological hierarchy. To address these limitations, we propose HFGPI, a hierarchical fusion framework that models the biological progression from genes to proteins to histology images from a systems biology perspective. Specifically, we introduce Molecular Tokenizer, a molecular encoding strategy that integrates identity embeddings with expression profiles to construct biologically informed representations for genes and proteins. We then develop Gene-Regulated Protein Fusion (GRPF), which employs graph-aware cross-attention with structure-preserving alignment to explicitly model gene-protein regulatory relationships and generate gene-regulated protein representations. Additionally, we propose Protein-Guided Hypergraph Learning (PGHL), which establishes associations between proteins and image patches, leveraging hypergraph convolution to capture higher-order protein-morphology relationships. The final features are progressively fused across hierarchical layers to achieve precise survival outcome prediction. Extensive experiments on five benchmark datasets demonstrate the superiority of HFGPI over state-of-the-art methods.
See Once, Then Act: Vision-Language-Action Model with Task Learning from One-Shot Video Demonstrations
Dec 08, 2025Developing robust and general-purpose manipulation policies represents a fundamental objective in robotics research. While Vision-Language-Action (VLA) models have demonstrated promising capabilities for end-to-end robot control, existing approaches still exhibit limited generalization to tasks beyond their training distributions. In contrast, humans possess remarkable proficiency in acquiring novel skills by simply observing others performing them once. Inspired by this capability, we propose ViVLA, a generalist robotic manipulation policy that achieves efficient task learning from a single expert demonstration video at test time. Our approach jointly processes an expert demonstration video alongside the robot's visual observations to predict both the demonstrated action sequences and subsequent robot actions, effectively distilling fine-grained manipulation knowledge from expert behavior and transferring it seamlessly to the agent. To enhance the performance of ViVLA, we develop a scalable expert-agent pair data generation pipeline capable of synthesizing paired trajectories from easily accessible human videos, further augmented by curated pairs from publicly available datasets. This pipeline produces a total of 892,911 expert-agent samples for training ViVLA. Experimental results demonstrate that our ViVLA is able to acquire novel manipulation skills from only a single expert demonstration video at test time. Our approach achieves over 30% improvement on unseen LIBERO tasks and maintains above 35% gains with cross-embodiment videos. Real-world experiments demonstrate effective learning from human videos, yielding more than 38% improvement on unseen tasks.
FMimic: Foundation Models are Fine-grained Action Learners from Human Videos
Jul 28, 2025Visual imitation learning (VIL) provides an efficient and intuitive strategy for robotic systems to acquire novel skills. Recent advancements in foundation models, particularly Vision Language Models (VLMs), have demonstrated remarkable capabilities in visual and linguistic reasoning for VIL tasks. Despite this progress, existing approaches primarily utilize these models for learning high-level plans from human demonstrations, relying on pre-defined motion primitives for executing physical interactions, which remains a major bottleneck for robotic systems. In this work, we present FMimic, a novel paradigm that harnesses foundation models to directly learn generalizable skills at even fine-grained action levels, using only a limited number of human videos. Extensive experiments demonstrate that our FMimic delivers strong performance with a single human video, and significantly outperforms all other methods with five videos. Furthermore, our method exhibits significant improvements of over 39% and 29% in RLBench multi-task experiments and real-world manipulation tasks, respectively, and exceeds baselines by more than 34% in high-precision tasks and 47% in long-horizon tasks.
DINO-CoDT: Multi-class Collaborative Detection and Tracking with Vision Foundation Models
Jun 09, 2025Collaborative perception plays a crucial role in enhancing environmental understanding by expanding the perceptual range and improving robustness against sensor failures, which primarily involves collaborative 3D detection and tracking tasks. The former focuses on object recognition in individual frames, while the latter captures continuous instance tracklets over time. However, existing works in both areas predominantly focus on the vehicle superclass, lacking effective solutions for both multi-class collaborative detection and tracking. This limitation hinders their applicability in real-world scenarios, which involve diverse object classes with varying appearances and motion patterns. To overcome these limitations, we propose a multi-class collaborative detection and tracking framework tailored for diverse road users. We first present a detector with a global spatial attention fusion (GSAF) module, enhancing multi-scale feature learning for objects of varying sizes. Next, we introduce a tracklet RE-IDentification (REID) module that leverages visual semantics with a vision foundation model to effectively reduce ID SWitch (IDSW) errors, in cases of erroneous mismatches involving small objects like pedestrians. We further design a velocity-based adaptive tracklet management (VATM) module that adjusts the tracking interval dynamically based on object motion. Extensive experiments on the V2X-Real and OPV2V datasets show that our approach significantly outperforms existing state-of-the-art methods in both detection and tracking accuracy.
OpenIN: Open-Vocabulary Instance-Oriented Navigation in Dynamic Domestic Environments
Jan 08, 2025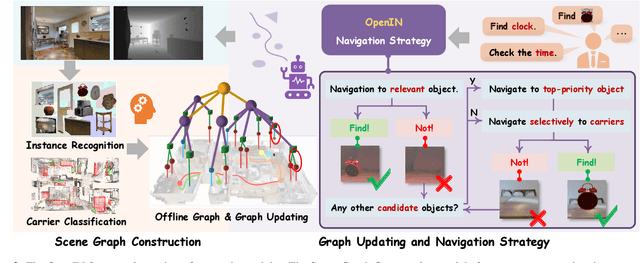
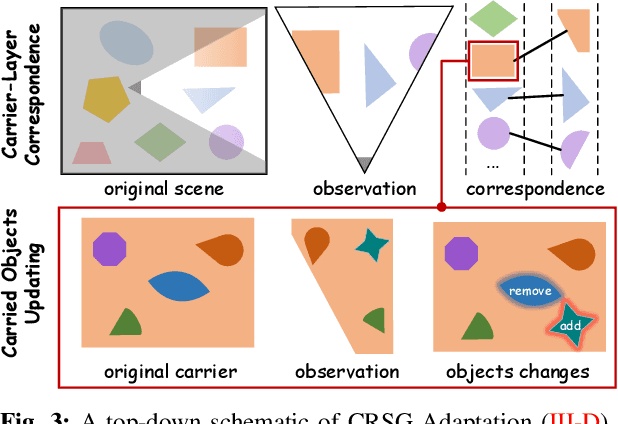
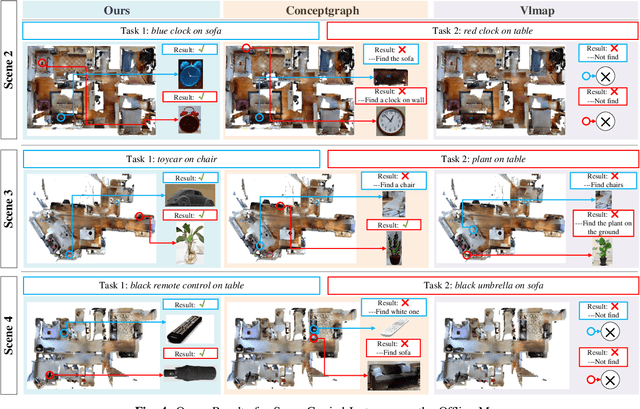
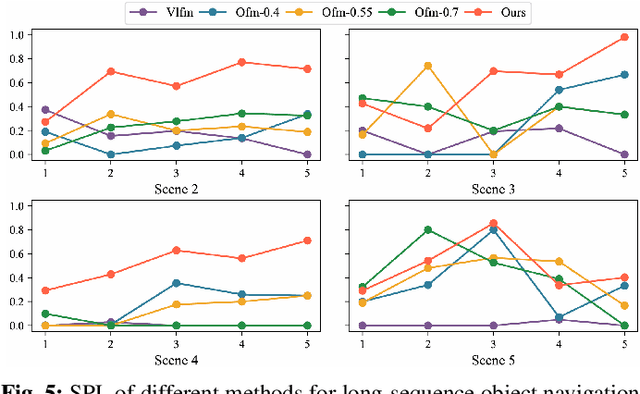
In daily domestic settings, frequently used objects like cups often have unfixed positions and multiple instances within the same category, and their carriers frequently change as well. As a result, it becomes challenging for a robot to efficiently navigate to a specific instance. To tackle this challenge, the robot must capture and update scene changes and plans continuously. However, current object navigation approaches primarily focus on the semantic level and lack the ability to dynamically update scene representation. In contrast, this paper captures the relationships between frequently used objects and their static carriers. It constructs an open-vocabulary Carrier-Relationship Scene Graph (CRSG) and updates the carrying status during robot navigation to reflect the dynamic changes of the scene. Based on the CRSG, we further propose an instance navigation strategy that models the navigation process as a Markov Decision Process. At each step, decisions are informed by the Large Language Model's commonsense knowledge and visual-language feature similarity. We designed a series of long-sequence navigation tasks for frequently used everyday items in the Habitat simulator. The results demonstrate that by updating the CRSG, the robot can efficiently navigate to moved targets. Additionally, we deployed our algorithm on a real robot and validated its practical effectiveness. The project page can be found here: https://OpenIN-nav.github.io.
VLMimic: Vision Language Models are Visual Imitation Learner for Fine-grained Actions
Oct 29, 2024

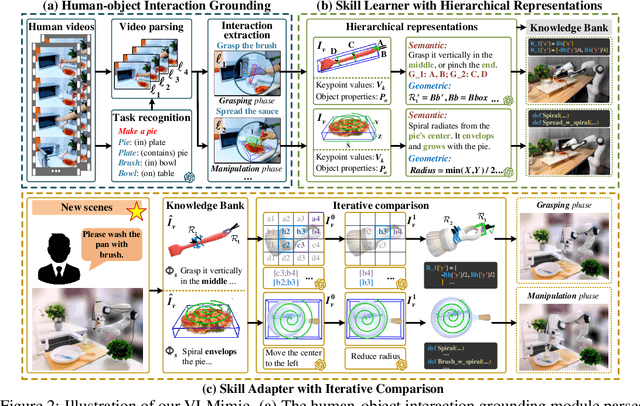

Visual imitation learning (VIL) provides an efficient and intuitive strategy for robotic systems to acquire novel skills. Recent advancements in Vision Language Models (VLMs) have demonstrated remarkable performance in vision and language reasoning capabilities for VIL tasks. Despite the progress, current VIL methods naively employ VLMs to learn high-level plans from human videos, relying on pre-defined motion primitives for executing physical interactions, which remains a major bottleneck. In this work, we present VLMimic, a novel paradigm that harnesses VLMs to directly learn even fine-grained action levels, only given a limited number of human videos. Specifically, VLMimic first grounds object-centric movements from human videos, and learns skills using hierarchical constraint representations, facilitating the derivation of skills with fine-grained action levels from limited human videos. These skills are refined and updated through an iterative comparison strategy, enabling efficient adaptation to unseen environments. Our extensive experiments exhibit that our VLMimic, using only 5 human videos, yields significant improvements of over 27% and 21% in RLBench and real-world manipulation tasks, and surpasses baselines by over 37% in long-horizon tasks.
OpenObject-NAV: Open-Vocabulary Object-Oriented Navigation Based on Dynamic Carrier-Relationship Scene Graph
Sep 27, 2024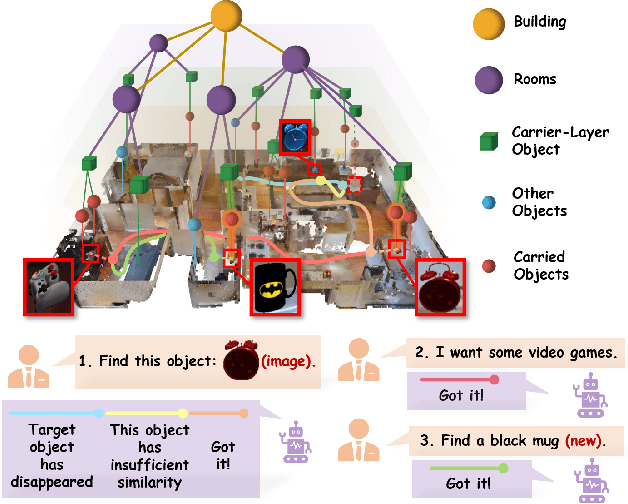
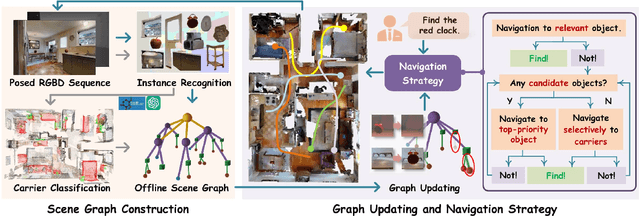
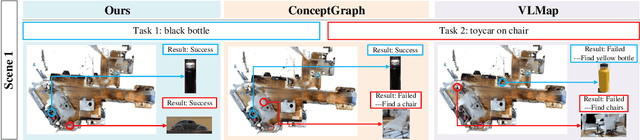
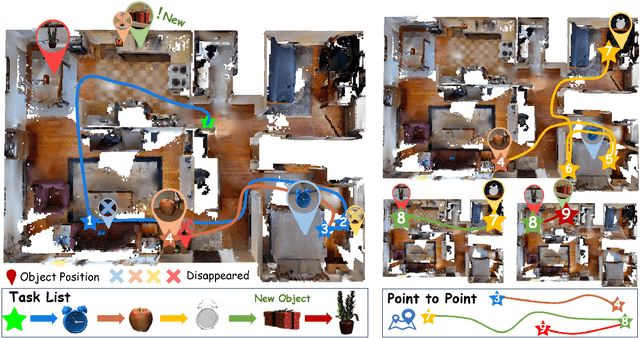
In everyday life, frequently used objects like cups often have unfixed positions and multiple instances within the same category, and their carriers frequently change as well. As a result, it becomes challenging for a robot to efficiently navigate to a specific instance. To tackle this challenge, the robot must capture and update scene changes and plans continuously. However, current object navigation approaches primarily focus on semantic-level and lack the ability to dynamically update scene representation. This paper captures the relationships between frequently used objects and their static carriers. It constructs an open-vocabulary Carrier-Relationship Scene Graph (CRSG) and updates the carrying status during robot navigation to reflect the dynamic changes of the scene. Based on the CRSG, we further propose an instance navigation strategy that models the navigation process as a Markov Decision Process. At each step, decisions are informed by Large Language Model's commonsense knowledge and visual-language feature similarity. We designed a series of long-sequence navigation tasks for frequently used everyday items in the Habitat simulator. The results demonstrate that by updating the CRSG, the robot can efficiently navigate to moved targets. Additionally, we deployed our algorithm on a real robot and validated its practical effectiveness.
Point Tree Transformer for Point Cloud Registration
Jun 25, 2024



Point cloud registration is a fundamental task in the fields of computer vision and robotics. Recent developments in transformer-based methods have demonstrated enhanced performance in this domain. However, the standard attention mechanism utilized in these methods often integrates many low-relevance points, thereby struggling to prioritize its attention weights on sparse yet meaningful points. This inefficiency leads to limited local structure modeling capabilities and quadratic computational complexity. To overcome these limitations, we propose the Point Tree Transformer (PTT), a novel transformer-based approach for point cloud registration that efficiently extracts comprehensive local and global features while maintaining linear computational complexity. The PTT constructs hierarchical feature trees from point clouds in a coarse-to-dense manner, and introduces a novel Point Tree Attention (PTA) mechanism, which follows the tree structure to facilitate the progressive convergence of attended regions towards salient points. Specifically, each tree layer selectively identifies a subset of key points with the highest attention scores. Subsequent layers focus attention on areas of significant relevance, derived from the child points of the selected point set. The feature extraction process additionally incorporates coarse point features that capture high-level semantic information, thus facilitating local structure modeling and the progressive integration of multiscale information. Consequently, PTA empowers the model to concentrate on crucial local structures and derive detailed local information while maintaining linear computational complexity. Extensive experiments conducted on the 3DMatch, ModelNet40, and KITTI datasets demonstrate that our method achieves superior performance over the state-of-the-art methods.