 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee Once, Then Act: Vision-Language-Action Model with Task Learning from One-Shot Video Demonstrations
Dec 08, 2025Developing robust and general-purpose manipulation policies represents a fundamental objective in robotics research. While Vision-Language-Action (VLA) models have demonstrated promising capabilities for end-to-end robot control, existing approaches still exhibit limited generalization to tasks beyond their training distributions. In contrast, humans possess remarkable proficiency in acquiring novel skills by simply observing others performing them once. Inspired by this capability, we propose ViVLA, a generalist robotic manipulation policy that achieves efficient task learning from a single expert demonstration video at test time. Our approach jointly processes an expert demonstration video alongside the robot's visual observations to predict both the demonstrated action sequences and subsequent robot actions, effectively distilling fine-grained manipulation knowledge from expert behavior and transferring it seamlessly to the agent. To enhance the performance of ViVLA, we develop a scalable expert-agent pair data generation pipeline capable of synthesizing paired trajectories from easily accessible human videos, further augmented by curated pairs from publicly available datasets. This pipeline produces a total of 892,911 expert-agent samples for training ViVLA. Experimental results demonstrate that our ViVLA is able to acquire novel manipulation skills from only a single expert demonstration video at test time. Our approach achieves over 30% improvement on unseen LIBERO tasks and maintains above 35% gains with cross-embodiment videos. Real-world experiments demonstrate effective learning from human videos, yielding more than 38% improvement on unseen tasks.
OmniMap: A General Mapping Framework Integrating Optics, Geometry, and Semantics
Sep 09, 2025Robotic systems demand accurate and comprehensive 3D environment perception, requiring simultaneous capture of photo-realistic appearance (optical), precise layout shape (geometric), and open-vocabulary scene understanding (semantic). Existing methods typically achieve only partial fulfillment of these requirements while exhibiting optical blurring, geometric irregularities, and semantic ambiguities. To address these challenges, we propose OmniMap. Overall, OmniMap represents the first online mapping framework that simultaneously captures optical, geometric, and semantic scene attributes while maintaining real-time performance and model compactness. At the architectural level, OmniMap employs a tightly coupled 3DGS-Voxel hybrid representation that combines fine-grained modeling with structural stability. At the implementation level, OmniMap identifies key challenges across different modalities and introduces several innovations: adaptive camera modeling for motion blur and exposure compensation, hybrid incremental representation with normal constraints, and probabilistic fusion for robust instance-level understanding. Extensive experiments show OmniMap's superior performance in rendering fidelity, geometric accuracy, and zero-shot semantic segmentation compared to state-of-the-art methods across diverse scenes. The framework's versatility is further evidenced through a variety of downstream applications, including multi-domain scene Q&A, interactive editing, perception-guided manipulation, and map-assisted navigation.
OpenVox: Real-time Instance-level Open-vocabulary Probabilistic Voxel Representation
Feb 23, 2025In recent years, vision-language models (VLMs) have advanced open-vocabulary mapping, enabling mobile robots to simultaneously achieve environmental reconstruction and high-level semantic understanding. While integrated object cognition helps mitigate semantic ambiguity in point-wise feature maps, efficiently obtaining rich semantic understanding and robust incremental reconstruction at the instance-level remains challenging. To address these challenges, we introduce OpenVox, a real-time incremental open-vocabulary probabilistic instance voxel representation. In the front-end, we design an efficient instance segmentation and comprehension pipeline that enhances language reasoning through encoding captions. In the back-end, we implement probabilistic instance voxels and formulate the cross-frame incremental fusion process into two subtasks: instance association and live map evolution, ensuring robustness to sensor and segmentation noise. Extensive evaluations across multiple datasets demonstrate that OpenVox achieves state-of-the-art performance in zero-shot instance segmentation, semantic segmentation, and open-vocabulary retrieval. Furthermore, real-world robotics experiments validate OpenVox's capability for stable, real-time operation.
OpenIN: Open-Vocabulary Instance-Oriented Navigation in Dynamic Domestic Environments
Jan 08, 2025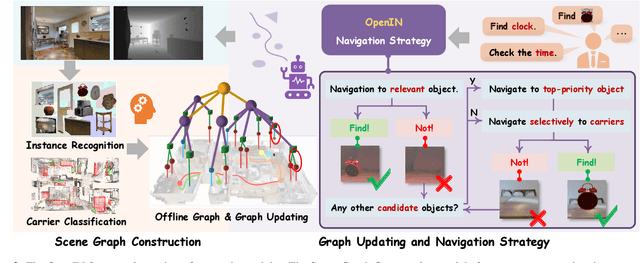
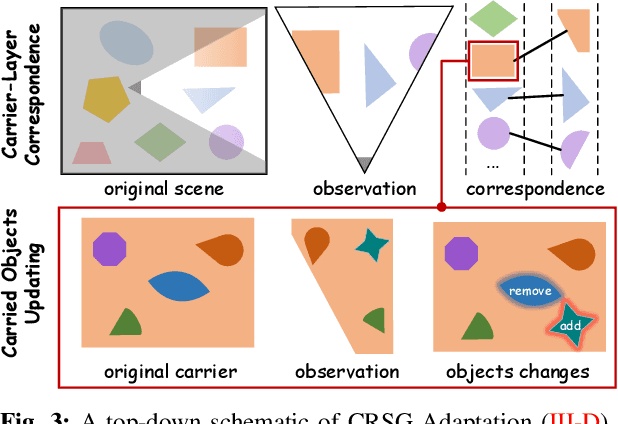
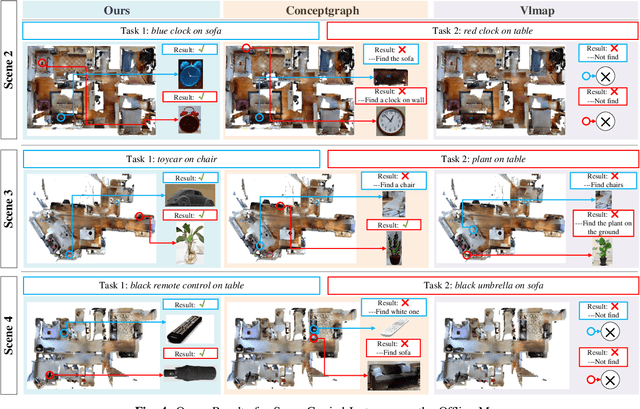
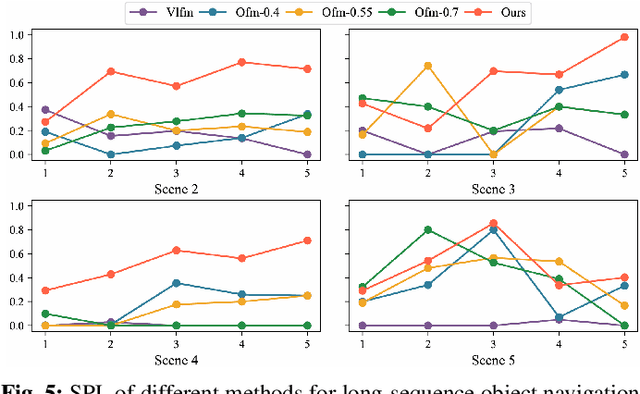
In daily domestic settings, frequently used objects like cups often have unfixed positions and multiple instances within the same category, and their carriers frequently change as well. As a result, it becomes challenging for a robot to efficiently navigate to a specific instance. To tackle this challenge, the robot must capture and update scene changes and plans continuously. However, current object navigation approaches primarily focus on the semantic level and lack the ability to dynamically update scene representation. In contrast, this paper captures the relationships between frequently used objects and their static carriers. It constructs an open-vocabulary Carrier-Relationship Scene Graph (CRSG) and updates the carrying status during robot navigation to reflect the dynamic changes of the scene. Based on the CRSG, we further propose an instance navigation strategy that models the navigation process as a Markov Decision Process. At each step, decisions are informed by the Large Language Model's commonsense knowledge and visual-language feature similarity. We designed a series of long-sequence navigation tasks for frequently used everyday items in the Habitat simulator. The results demonstrate that by updating the CRSG, the robot can efficiently navigate to moved targets. Additionally, we deployed our algorithm on a real robot and validated its practical effectiveness. The project page can be found here: https://OpenIN-nav.github.io.
LCP-Fusion: A Neural Implicit SLAM with Enhanced Local Constraints and Computable Prior
Nov 06, 2024Recently the dense Simultaneous Localization and Mapping (SLAM) based on neural implicit representation has shown impressive progress in hole filling and high-fidelity mapping. Nevertheless, existing methods either heavily rely on known scene bounds or suffer inconsistent reconstruction due to drift in potential loop-closure regions, or both, which can be attributed to the inflexible representation and lack of local constraints. In this paper, we present LCP-Fusion, a neural implicit SLAM system with enhanced local constraints and computable prior, which takes the sparse voxel octree structure containing feature grids and SDF priors as hybrid scene representation, enabling the scalability and robustness during mapping and tracking. To enhance the local constraints, we propose a novel sliding window selection strategy based on visual overlap to address the loop-closure, and a practical warping loss to constrain relative poses. Moreover, we estimate SDF priors as coarse initialization for implicit features, which brings additional explicit constraints and robustness, especially when a light but efficient adaptive early ending is adopted. Experiments demonstrate that our method achieve better localization accuracy and reconstruction consistency than existing RGB-D implicit SLAM, especially in challenging real scenes (ScanNet) as well as self-captured scenes with unknown scene bounds. The code is available at https://github.com/laliwang/LCP-Fusion.
OpenObject-NAV: Open-Vocabulary Object-Oriented Navigation Based on Dynamic Carrier-Relationship Scene Graph
Sep 27, 2024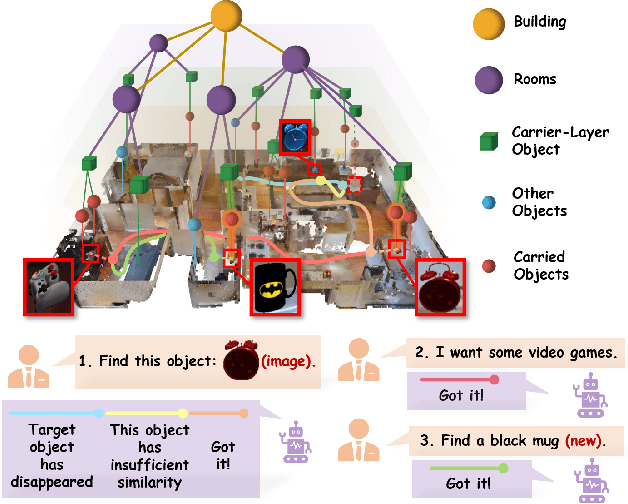
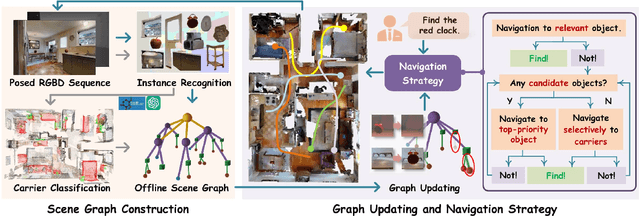
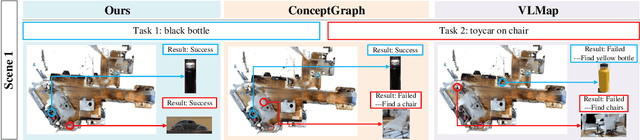
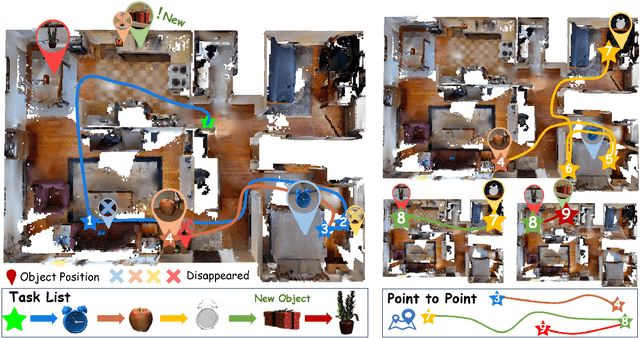
In everyday life, frequently used objects like cups often have unfixed positions and multiple instances within the same category, and their carriers frequently change as well. As a result, it becomes challenging for a robot to efficiently navigate to a specific instance. To tackle this challenge, the robot must capture and update scene changes and plans continuously. However, current object navigation approaches primarily focus on semantic-level and lack the ability to dynamically update scene representation. This paper captures the relationships between frequently used objects and their static carriers. It constructs an open-vocabulary Carrier-Relationship Scene Graph (CRSG) and updates the carrying status during robot navigation to reflect the dynamic changes of the scene. Based on the CRSG, we further propose an instance navigation strategy that models the navigation process as a Markov Decision Process. At each step, decisions are informed by Large Language Model's commonsense knowledge and visual-language feature similarity. We designed a series of long-sequence navigation tasks for frequently used everyday items in the Habitat simulator. The results demonstrate that by updating the CRSG, the robot can efficiently navigate to moved targets. Additionally, we deployed our algorithm on a real robot and validated its practical effectiveness.
OpenObj: Open-Vocabulary Object-Level Neural Radiance Fields with Fine-Grained Understanding
Jun 12, 2024In recent years, there has been a surge of interest in open-vocabulary 3D scene reconstruction facilitated by visual language models (VLMs), which showcase remarkable capabilities in open-set retrieval. However, existing methods face some limitations: they either focus on learning point-wise features, resulting in blurry semantic understanding, or solely tackle object-level reconstruction, thereby overlooking the intricate details of the object's interior. To address these challenges, we introduce OpenObj, an innovative approach to build open-vocabulary object-level Neural Radiance Fields (NeRF) with fine-grained understanding. In essence, OpenObj establishes a robust framework for efficient and watertight scene modeling and comprehension at the object-level. Moreover, we incorporate part-level features into the neural fields, enabling a nuanced representation of object interiors. This approach captures object-level instances while maintaining a fine-grained understanding. The results on multiple datasets demonstrate that OpenObj achieves superior performance in zero-shot semantic segmentation and retrieval tasks. Additionally, OpenObj supports real-world robotics tasks at multiple scales, including global movement and local manipulation.
LGSDF: Continual Global Learning of Signed Distance Fields Aided by Local Updating
Apr 08, 2024Implicit reconstruction of ESDF (Euclidean Signed Distance Field) involves training a neural network to regress the signed distance from any point to the nearest obstacle, which has the advantages of lightweight storage and continuous querying. However, existing algorithms usually rely on conflicting raw observations as training data, resulting in poor map performance. In this paper, we propose LGSDF, an ESDF continual Global learning algorithm aided by Local updating. At the front end, axis-aligned grids are dynamically updated by pre-processed sensor observations, where incremental fusion alleviates estimation error caused by limited viewing directions. At the back end, a randomly initialized implicit ESDF neural network performs continual self-supervised learning guided by these grids to generate smooth and continuous maps. The results on multiple scenes show that LGSDF can construct more accurate ESDF maps and meshes compared with SOTA (State Of The Art) explicit and implicit mapping algorithms. The source code of LGSDF is publicly available at https://github.com/BIT-DYN/LGSDF.
OpenGraph: Open-Vocabulary Hierarchical 3D Graph Representation in Large-Scale Outdoor Environments
Mar 28, 2024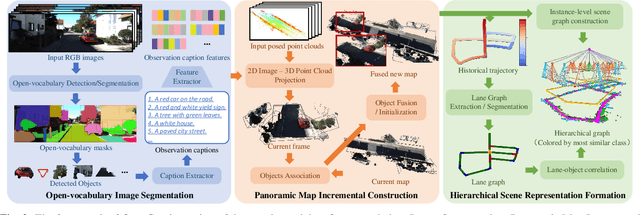
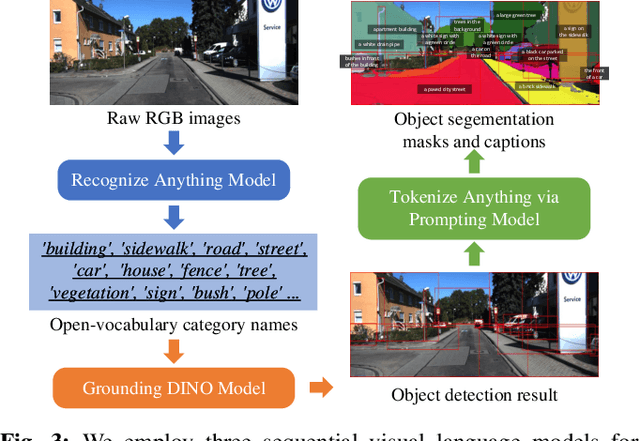

Environment representations endowed with sophisticated semantics are pivotal for facilitating seamless interaction between robots and humans, enabling them to effectively carry out various tasks. Open-vocabulary maps, powered by Visual-Language models (VLMs), possess inherent advantages, including zero-shot learning and support for open-set classes. However, existing open-vocabulary maps are primarily designed for small-scale environments, such as desktops or rooms, and are typically geared towards limited-area tasks involving robotic indoor navigation or in-place manipulation. They face challenges in direct generalization to outdoor environments characterized by numerous objects and complex tasks, owing to limitations in both understanding level and map structure. In this work, we propose OpenGraph, the first open-vocabulary hierarchical graph representation designed for large-scale outdoor environments. OpenGraph initially extracts instances and their captions from visual images, enhancing textual reasoning by encoding them. Subsequently, it achieves 3D incremental object-centric mapping with feature embedding by projecting images onto LiDAR point clouds. Finally, the environment is segmented based on lane graph connectivity to construct a hierarchical graph. Validation results from public dataset SemanticKITTI demonstrate that OpenGraph achieves the highest segmentation and query accuracy. The source code of OpenGraph is publicly available at https://github.com/BIT-DYN/OpenGraph.