 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenVox: Real-time Instance-level Open-vocabulary Probabilistic Voxel Representation
Feb 23, 2025In recent years, vision-language models (VLMs) have advanced open-vocabulary mapping, enabling mobile robots to simultaneously achieve environmental reconstruction and high-level semantic understanding. While integrated object cognition helps mitigate semantic ambiguity in point-wise feature maps, efficiently obtaining rich semantic understanding and robust incremental reconstruction at the instance-level remains challenging. To address these challenges, we introduce OpenVox, a real-time incremental open-vocabulary probabilistic instance voxel representation. In the front-end, we design an efficient instance segmentation and comprehension pipeline that enhances language reasoning through encoding captions. In the back-end, we implement probabilistic instance voxels and formulate the cross-frame incremental fusion process into two subtasks: instance association and live map evolution, ensuring robustness to sensor and segmentation noise. Extensive evaluations across multiple datasets demonstrate that OpenVox achieves state-of-the-art performance in zero-shot instance segmentation, semantic segmentation, and open-vocabulary retrieval. Furthermore, real-world robotics experiments validate OpenVox's capability for stable, real-time operation.
Multi-objective Feature Selection with Missing Data in Classification
Apr 18, 2021
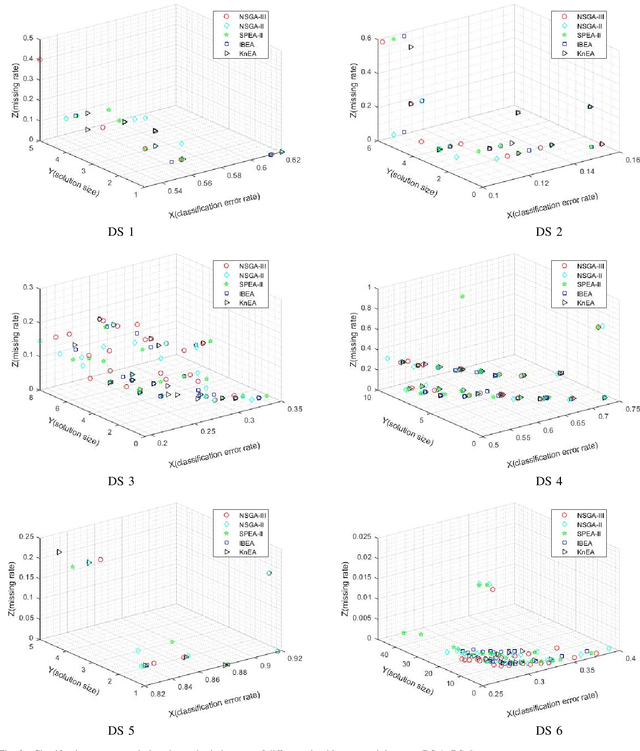
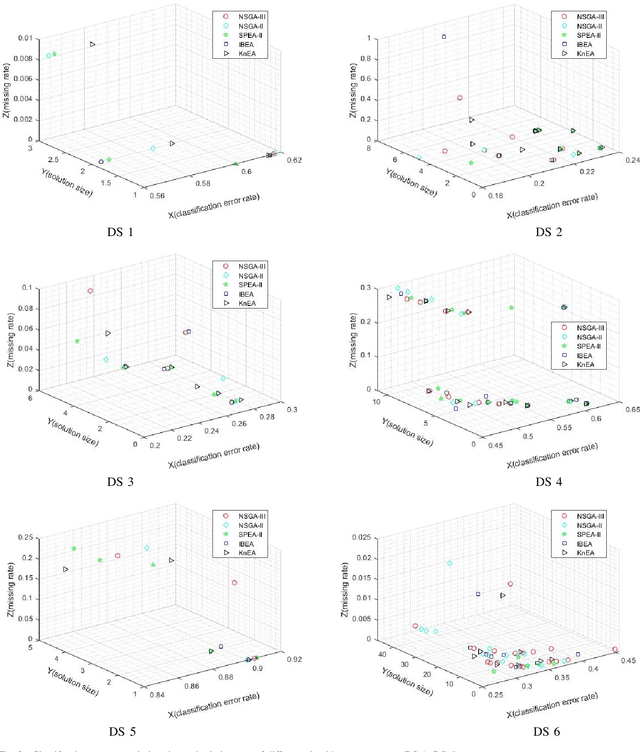
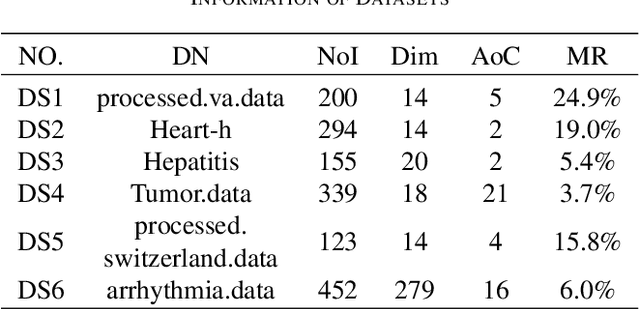
Feature selection (FS) is an important research topic in machine learning. Usually, FS is modelled as a+ bi-objective optimization problem whose objectives are: 1) classification accuracy; 2) number of features. One of the main issues in real-world applications is missing data. Databases with missing data are likely to be unreliable. Thus, FS performed on a data set missing some data is also unreliable. In order to directly control this issue plaguing the field, we propose in this study a novel modelling of FS: we include reliability as the third objective of the problem. In order to address the modified problem, we propose the application of the non-dominated sorting genetic algorithm-III (NSGA-III). We selected six incomplete data sets from the University of California Irvine (UCI) machine learning repository. We used the mean imputation method to deal with the missing data. In the experiments, k-nearest neighbors (K-NN) is used as the classifier to evaluate the feature subsets. Experimental results show that the proposed three-objective model coupled with NSGA-III efficiently addresses the FS problem for the six data sets included in this study.