 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-objective Feature Selection with Missing Data in Classification
Paper and Code
Apr 18, 2021
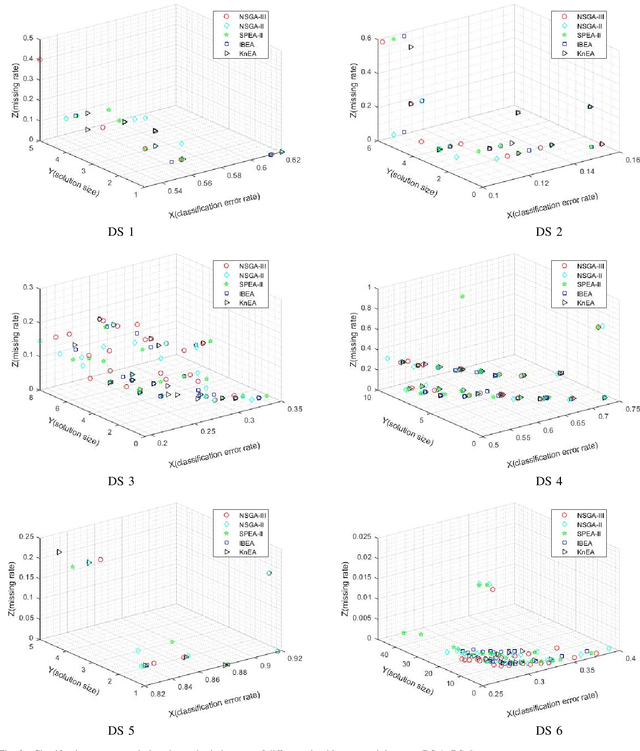
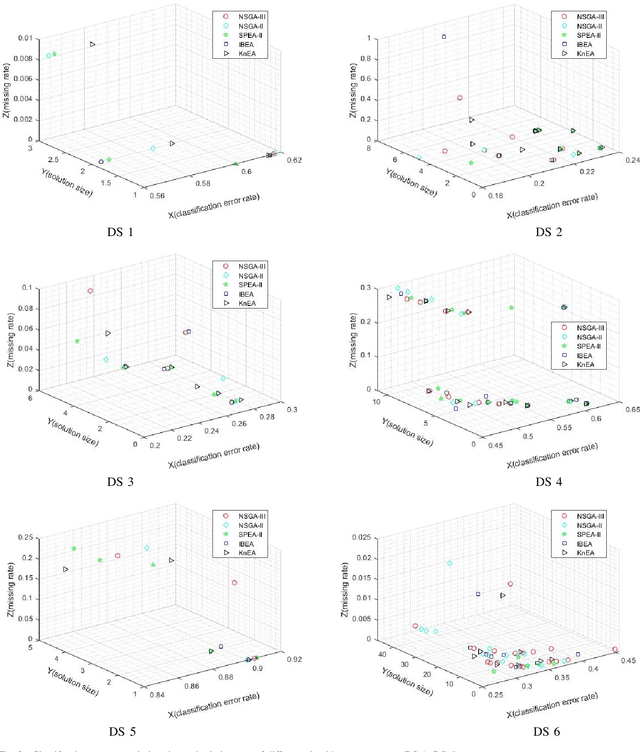
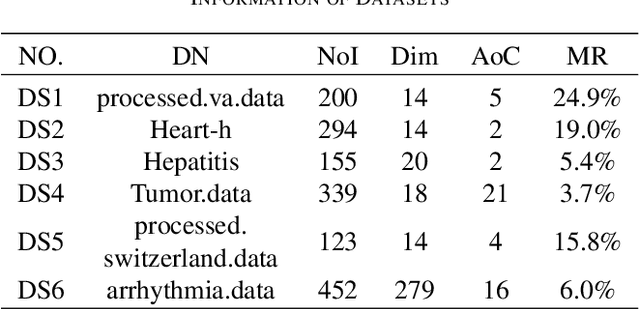
Feature selection (FS) is an important research topic in machine learning. Usually, FS is modelled as a+ bi-objective optimization problem whose objectives are: 1) classification accuracy; 2) number of features. One of the main issues in real-world applications is missing data. Databases with missing data are likely to be unreliable. Thus, FS performed on a data set missing some data is also unreliable. In order to directly control this issue plaguing the field, we propose in this study a novel modelling of FS: we include reliability as the third objective of the problem. In order to address the modified problem, we propose the application of the non-dominated sorting genetic algorithm-III (NSGA-III). We selected six incomplete data sets from the University of California Irvine (UCI) machine learning repository. We used the mean imputation method to deal with the missing data. In the experiments, k-nearest neighbors (K-NN) is used as the classifier to evaluate the feature subsets. Experimental results show that the proposed three-objective model coupled with NSGA-III efficiently addresses the FS problem for the six data sets included in this study.