 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA 2.5 $μ$W 30 nV/$\surd$Hz Instrumentation Amplifier for Bioimpedance Sensors with Source Degenerated Current Mirror and DTMOS Transistor
Jan 03, 2026This paper proposes a low-power and low-noise instrumentation amplifier (IA) tailored for bioimpedance sensing applications. The design originates from a gain-boosted flipped voltage follower (FVF) transconductance (TC) stage and integrates two complementary circuit techniques to improve the noise performance. To achieve an optimal balance between input-referred noise and available voltage headroom, a source-degenerated current mirror (SDCM) is adopted, resulting in reducing the input-referred noise by 7.95% compared with a conventional current mirror structure. In addition, a dynamic threshold MOSFET (DTMOS) scheme is employed to enhance the effective transconductance, leading to a further 11.66% reduction in input-referred noise. Simulated in a 28 nm CMOS process demonstrate that the proposed IA achieves an input-referred noise floor of 30 nV/$\surd$Hz and a bandwidth of 1.44 MHz, while consuming only 2.5 $μ$W from a 0.8 V supply. Compared to the baseline design, the proposed approach achieves a 32.4% reduction in power consumption without degrading noise performance. The complete design parameters are open-sourced in this paper, to ensure reproducibility and facilitate future developments.
UAV-Enabled Passive 6DMA for ISAC: Joint Location, Orientation, and Reflection Optimization
May 15, 2025Improving the fundamental performance trade-off in integrated sensing and communication (ISAC) systems has been deemed as one of the most significant challenges. To address it, we propose in this letter a novel ISAC system that leverages an unmanned aerial vehicle (UAV)-mounted intelligent reflecting surface (IRS) and the UAV's maneuverability in six-dimensional (6D) space, i.e., three-dimensional (3D) location and 3D rotation, thus referred to as passive 6D movable antenna (6DMA). We aim to maximize the signal-to-noise ratio (SNR) for sensing a single target while ensuring a minimum SNR at a communication user equipment (UE), by jointly optimizing the transmit beamforming at the ISAC base station (BS), the 3D location and orientation as well as the reflection coefficients of the IRS. To solve this challenging non-convex optimization problem, we propose a two-stage approach. In the first stage, we aim to optimize the IRS's 3D location, 3D orientation, and reflection coefficients to enhance both the channel correlations and power gains for sensing and communication. Given their optimized parameters, the optimal transmit beamforming at the ISAC BS is derived in closed form. Simulation results demonstrate that the proposed passive 6DMA-enabled ISAC system significantly improves the sensing and communication trade-off by simultaneously enhancing channel correlations and power gains, and outperforms other baseline schemes.
Enhancing LLM-Based Short Answer Grading with Retrieval-Augmented Generation
Apr 07, 2025



Short answer assessment is a vital component of science education, allowing evaluation of students' complex three-dimensional understanding. Large language models (LLMs) that possess human-like ability in linguistic tasks are increasingly popular in assisting human graders to reduce their workload. However, LLMs' limitations in domain knowledge restrict their understanding in task-specific requirements and hinder their ability to achieve satisfactory performance. Retrieval-augmented generation (RAG) emerges as a promising solution by enabling LLMs to access relevant domain-specific knowledge during assessment. In this work, we propose an adaptive RAG framework for automated grading that dynamically retrieves and incorporates domain-specific knowledge based on the question and student answer context. Our approach combines semantic search and curated educational sources to retrieve valuable reference materials. Experimental results in a science education dataset demonstrate that our system achieves an improvement in grading accuracy compared to baseline LLM approaches. The findings suggest that RAG-enhanced grading systems can serve as reliable support with efficient performance gains.
A Pairwise Comparison Relation-assisted Multi-objective Evolutionary Neural Architecture Search Method with Multi-population Mechanism
Jul 22, 2024Neural architecture search (NAS) enables re-searchers to automatically explore vast search spaces and find efficient neural networks. But NAS suffers from a key bottleneck, i.e., numerous architectures need to be evaluated during the search process, which requires a lot of computing resources and time. In order to improve the efficiency of NAS, a series of methods have been proposed to reduce the evaluation time of neural architectures. However, they are not efficient enough and still only focus on the accuracy of architectures. In addition to the classification accuracy, more efficient and smaller network architectures are required in real-world applications. To address the above problems, we propose the SMEM-NAS, a pairwise com-parison relation-assisted multi-objective evolutionary algorithm based on a multi-population mechanism. In the SMEM-NAS, a surrogate model is constructed based on pairwise compari-son relations to predict the accuracy ranking of architectures, rather than the absolute accuracy. Moreover, two populations cooperate with each other in the search process, i.e., a main population guides the evolution, while a vice population expands the diversity. Our method aims to provide high-performance models that take into account multiple optimization objectives. We conduct a series of experiments on the CIFAR-10, CIFAR-100 and ImageNet datasets to verify its effectiveness. With only a single GPU searching for 0.17 days, competitive architectures can be found by SMEM-NAS which achieves 78.91% accuracy with the MAdds of 570M on the ImageNet. This work makes a significant advance in the important field of NAS.
Bidirectionally Deformable Motion Modulation For Video-based Human Pose Transfer
Jul 18, 2023



Video-based human pose transfer is a video-to-video generation task that animates a plain source human image based on a series of target human poses. Considering the difficulties in transferring highly structural patterns on the garments and discontinuous poses, existing methods often generate unsatisfactory results such as distorted textures and flickering artifacts. To address these issues, we propose a novel Deformable Motion Modulation (DMM) that utilizes geometric kernel offset with adaptive weight modulation to simultaneously perform feature alignment and style transfer. Different from normal style modulation used in style transfer, the proposed modulation mechanism adaptively reconstructs smoothed frames from style codes according to the object shape through an irregular receptive field of view. To enhance the spatio-temporal consistency, we leverage bidirectional propagation to extract the hidden motion information from a warped image sequence generated by noisy poses. The proposed feature propagation significantly enhances the motion prediction ability by forward and backward propagation. Both quantitative and qualitative experimental results demonstrate superiority over the state-of-the-arts in terms of image fidelity and visual continuity. The source code is publicly available at github.com/rocketappslab/bdmm.
Partial Connection Based on Channel Attention for Differentiable Neural Architecture Search
Aug 01, 2022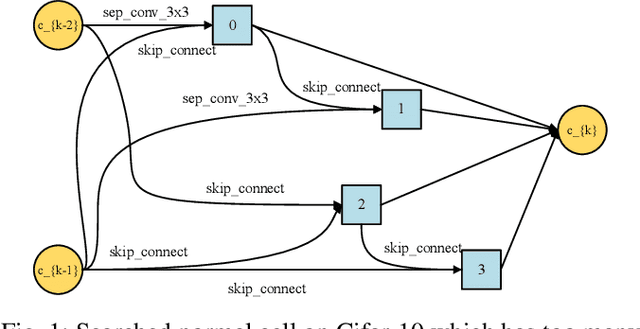
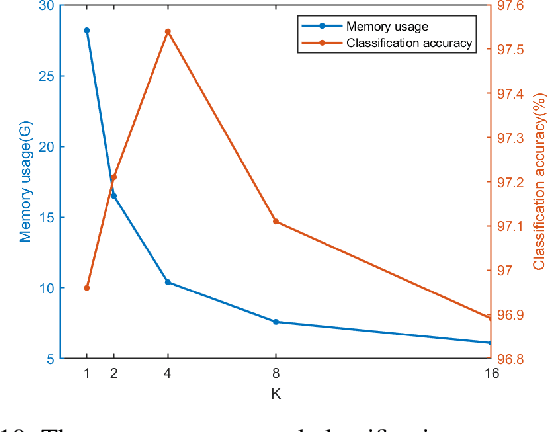
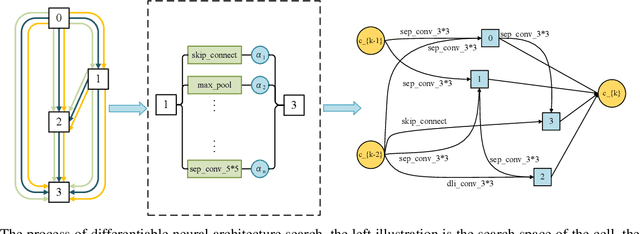
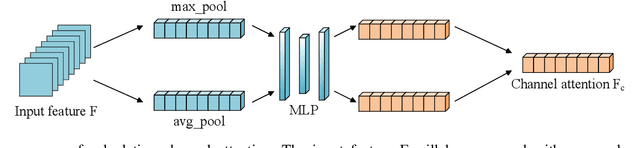
Differentiable neural architecture search (DARTS), as a gradient-guided search method, greatly reduces the cost of computation and speeds up the search. In DARTS, the architecture parameters are introduced to the candidate operations, but the parameters of some weight-equipped operations may not be trained well in the initial stage, which causes unfair competition between candidate operations. The weight-free operations appear in large numbers which results in the phenomenon of performance crash. Besides, a lot of memory will be occupied during training supernet which causes the memory utilization to be low. In this paper, a partial channel connection based on channel attention for differentiable neural architecture search (ADARTS) is proposed. Some channels with higher weights are selected through the attention mechanism and sent into the operation space while the other channels are directly contacted with the processed channels. Selecting a few channels with higher attention weights can better transmit important feature information into the search space and greatly improve search efficiency and memory utilization. The instability of network structure caused by random selection can also be avoided. The experimental results show that ADARTS achieved 2.46% and 17.06% classification error rates on CIFAR-10 and CIFAR-100, respectively. ADARTS can effectively solve the problem that too many skip connections appear in the search process and obtain network structures with better performance.
HDAM: Heuristic Difference Attention Module for Convolutional Neural Networks
Feb 19, 2022


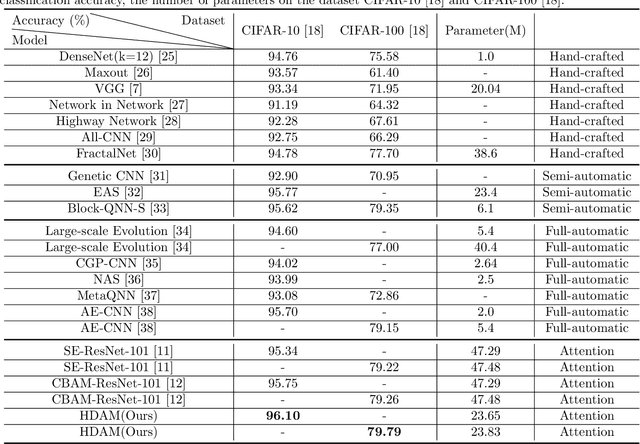
The attention mechanism is one of the most important priori knowledge to enhance convolutional neural networks. Most attention mechanisms are bound to the convolutional layer and use local or global contextual information to recalibrate the input. This is a popular attention strategy design method. Global contextual information helps the network to consider the overall distribution, while local contextual information is more general. The contextual information makes the network pay attention to the mean or maximum value of a particular receptive field. Different from the most attention mechanism, this article proposes a novel attention mechanism with the heuristic difference attention module, HDAM. HDAM's input recalibration is based on the difference between the local and global contextual information instead of the mean and maximum values. At the same time, to make different layers have a more suitable local receptive field size and increase the exibility of the local receptive field design, we use genetic algorithm to heuristically produce local receptive fields. First, HDAM extracts the mean value of the global and local receptive fields as the corresponding contextual information. Then the difference between the global and local contextual information is calculated. Finally HDAM uses this difference to recalibrate the input. In addition, we use the heuristic ability of genetic algorithm to search for the local receptive field size of each layer. Our experiments on CIFAR-10 and CIFAR-100 show that HDAM can use fewer parameters than other attention mechanisms to achieve higher accuracy. We implement HDAM with the Python library, Pytorch, and the code and models will be publicly available.
ConAM: Confidence Attention Module for Convolutional Neural Networks
Oct 27, 2021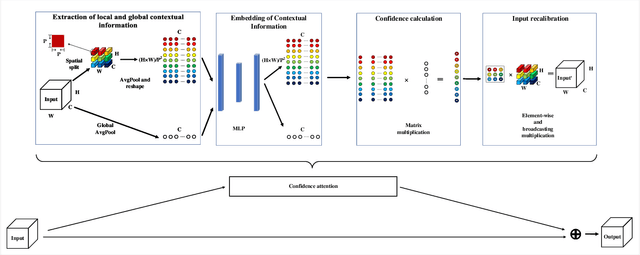
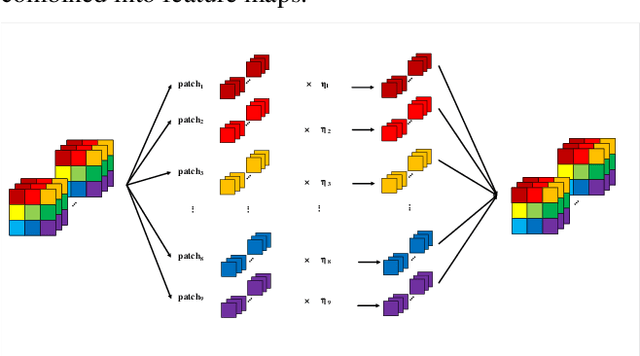

The so-called ``attention'' is an efficient mechanism to improve the performance of convolutional neural networks. It uses contextual information to recalibrate the input to strengthen the propagation of informative features. However, the majority of the attention mechanisms only consider either local or global contextual information, which is singular to extract features. Moreover, many existing mechanisms directly use the contextual information to recalibrate the input, which unilaterally enhances the propagation of the informative features, but does not suppress the useless ones. This paper proposes a new attention mechanism module based on the correlation between local and global contextual information and we name this correlation as confidence. The novel attention mechanism extracts the local and global contextual information simultaneously, and calculates the confidence between them, then uses this confidence to recalibrate the input pixels. The extraction of local and global contextual information increases the diversity of features. The recalibration with confidence suppresses useless information while enhancing the informative one with fewer parameters. We use CIFAR-10 and CIFAR-100 in our experiments and explore the performance of our method's components by sufficient ablation studies. Finally, we compare our method with a various state-of-the-art convolutional neural networks and the results show that our method completely surpasses these models. We implement ConAM with the Python library, Pytorch, and the code and models will be publicly available.
A Novel Sleep Stage Classification Using CNN Generated by an Efficient Neural Architecture Search with a New Data Processing Trick
Oct 27, 2021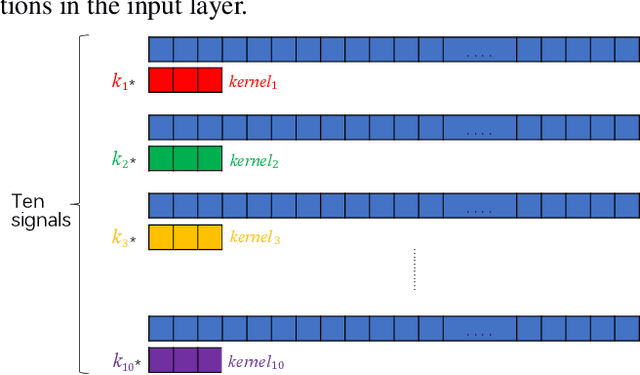
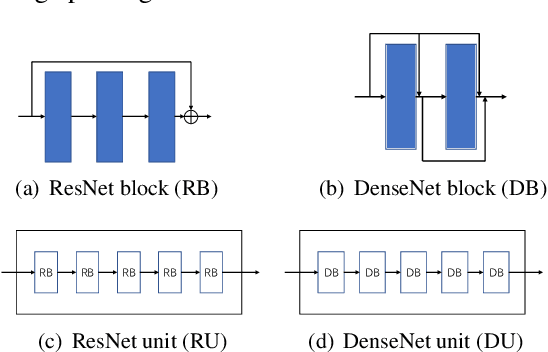

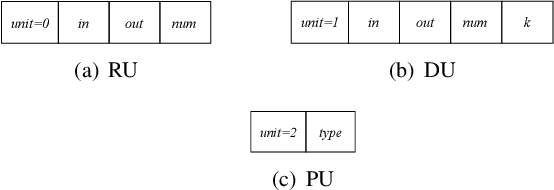
With the development of automatic sleep stage classification (ASSC) techniques, many classical methods such as k-means, decision tree, and SVM have been used in automatic sleep stage classification. However, few methods explore deep learning on ASSC. Meanwhile, most deep learning methods require extensive expertise and suffer from a mass of handcrafted steps which are time-consuming especially when dealing with multi-classification tasks. In this paper, we propose an efficient five-sleep-stage classification method using convolutional neural networks (CNNs) with a novel data processing trick and we design neural architecture search (NAS) technique based on genetic algorithm (GA), NAS-G, to search for the best CNN architecture. Firstly, we attach each kernel with an adaptive coefficient to enhance the signal processing of the inputs. This can enhance the propagation of informative features and suppress the propagation of useless features in the early stage of the network. Then, we make full use of GA's heuristic search and the advantage of no need for the gradient to search for the best architecture of CNN. This can achieve a CNN with better performance than a handcrafted one in a large search space at the minimum cost. We verify the convergence of our data processing trick and compare the performance of traditional CNNs before and after using our trick. Meanwhile, we compare the performance between the CNN generated through NAS-G and the traditional CNNs with our trick. The experiments demonstrate that the convergence of CNNs with data processing trick is faster than without data processing trick and the CNN with data processing trick generated by NAS-G outperforms the handcrafted counterparts that use the data processing trick too.
Multi-objective Feature Selection with Missing Data in Classification
Apr 18, 2021
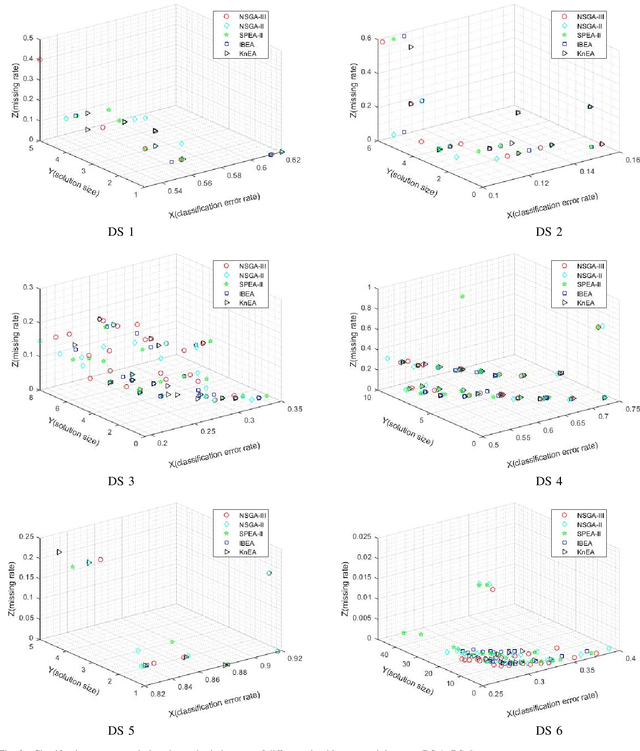
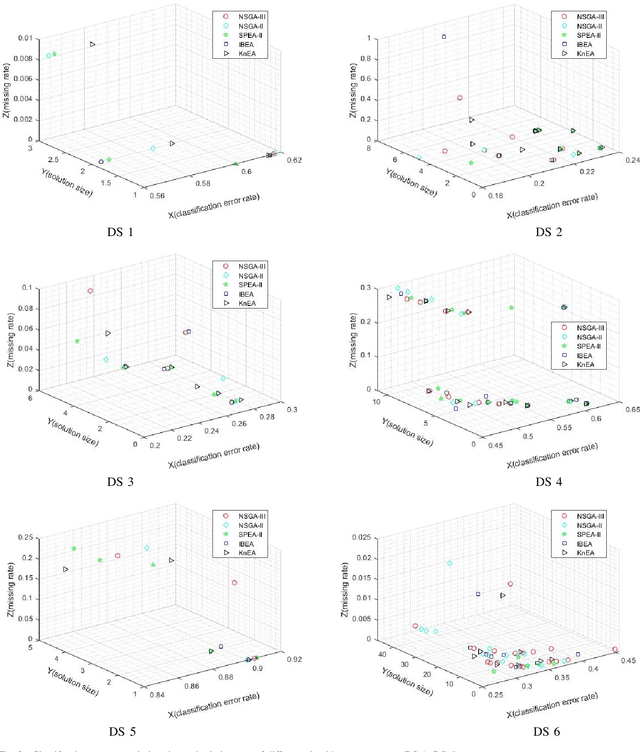
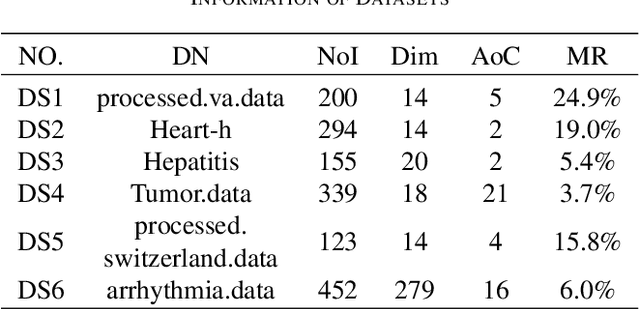
Feature selection (FS) is an important research topic in machine learning. Usually, FS is modelled as a+ bi-objective optimization problem whose objectives are: 1) classification accuracy; 2) number of features. One of the main issues in real-world applications is missing data. Databases with missing data are likely to be unreliable. Thus, FS performed on a data set missing some data is also unreliable. In order to directly control this issue plaguing the field, we propose in this study a novel modelling of FS: we include reliability as the third objective of the problem. In order to address the modified problem, we propose the application of the non-dominated sorting genetic algorithm-III (NSGA-III). We selected six incomplete data sets from the University of California Irvine (UCI) machine learning repository. We used the mean imputation method to deal with the missing data. In the experiments, k-nearest neighbors (K-NN) is used as the classifier to evaluate the feature subsets. Experimental results show that the proposed three-objective model coupled with NSGA-III efficiently addresses the FS problem for the six data sets included in this study.