 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHDAM: Heuristic Difference Attention Module for Convolutional Neural Networks
Feb 19, 2022


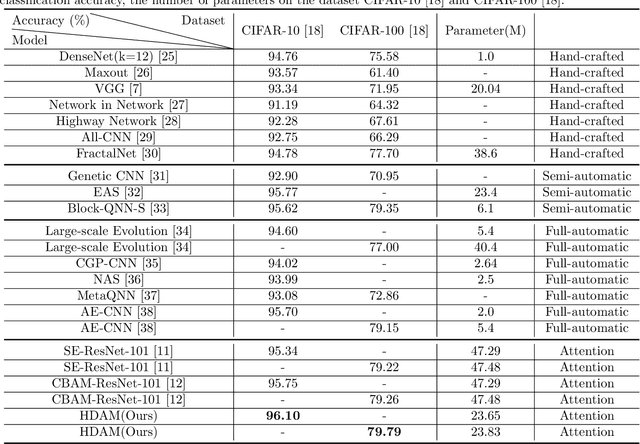
The attention mechanism is one of the most important priori knowledge to enhance convolutional neural networks. Most attention mechanisms are bound to the convolutional layer and use local or global contextual information to recalibrate the input. This is a popular attention strategy design method. Global contextual information helps the network to consider the overall distribution, while local contextual information is more general. The contextual information makes the network pay attention to the mean or maximum value of a particular receptive field. Different from the most attention mechanism, this article proposes a novel attention mechanism with the heuristic difference attention module, HDAM. HDAM's input recalibration is based on the difference between the local and global contextual information instead of the mean and maximum values. At the same time, to make different layers have a more suitable local receptive field size and increase the exibility of the local receptive field design, we use genetic algorithm to heuristically produce local receptive fields. First, HDAM extracts the mean value of the global and local receptive fields as the corresponding contextual information. Then the difference between the global and local contextual information is calculated. Finally HDAM uses this difference to recalibrate the input. In addition, we use the heuristic ability of genetic algorithm to search for the local receptive field size of each layer. Our experiments on CIFAR-10 and CIFAR-100 show that HDAM can use fewer parameters than other attention mechanisms to achieve higher accuracy. We implement HDAM with the Python library, Pytorch, and the code and models will be publicly available.
ConAM: Confidence Attention Module for Convolutional Neural Networks
Oct 27, 2021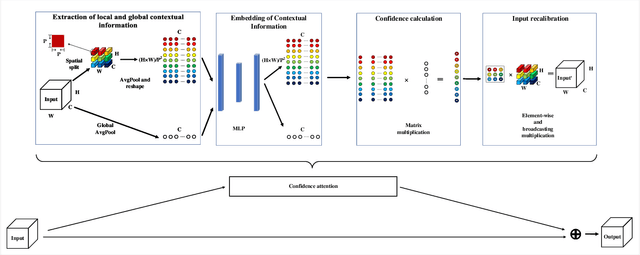

The so-called ``attention'' is an efficient mechanism to improve the performance of convolutional neural networks. It uses contextual information to recalibrate the input to strengthen the propagation of informative features. However, the majority of the attention mechanisms only consider either local or global contextual information, which is singular to extract features. Moreover, many existing mechanisms directly use the contextual information to recalibrate the input, which unilaterally enhances the propagation of the informative features, but does not suppress the useless ones. This paper proposes a new attention mechanism module based on the correlation between local and global contextual information and we name this correlation as confidence. The novel attention mechanism extracts the local and global contextual information simultaneously, and calculates the confidence between them, then uses this confidence to recalibrate the input pixels. The extraction of local and global contextual information increases the diversity of features. The recalibration with confidence suppresses useless information while enhancing the informative one with fewer parameters. We use CIFAR-10 and CIFAR-100 in our experiments and explore the performance of our method's components by sufficient ablation studies. Finally, we compare our method with a various state-of-the-art convolutional neural networks and the results show that our method completely surpasses these models. We implement ConAM with the Python library, Pytorch, and the code and models will be publicly available.
A Novel Sleep Stage Classification Using CNN Generated by an Efficient Neural Architecture Search with a New Data Processing Trick
Oct 27, 2021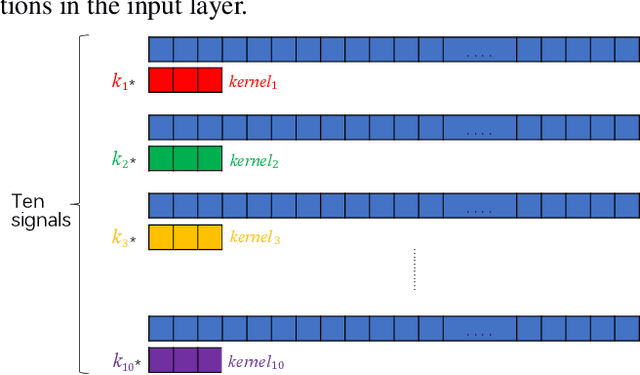
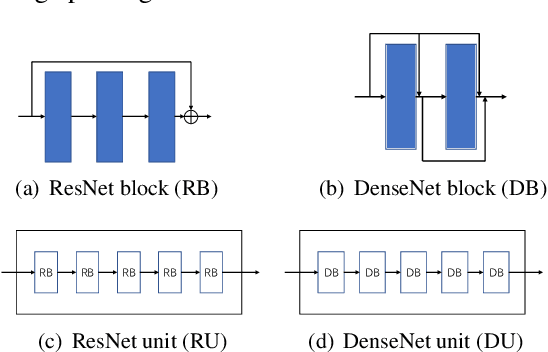

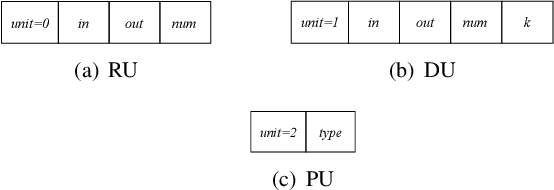
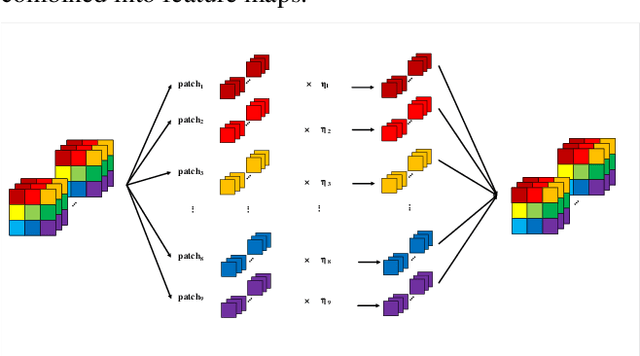
With the development of automatic sleep stage classification (ASSC) techniques, many classical methods such as k-means, decision tree, and SVM have been used in automatic sleep stage classification. However, few methods explore deep learning on ASSC. Meanwhile, most deep learning methods require extensive expertise and suffer from a mass of handcrafted steps which are time-consuming especially when dealing with multi-classification tasks. In this paper, we propose an efficient five-sleep-stage classification method using convolutional neural networks (CNNs) with a novel data processing trick and we design neural architecture search (NAS) technique based on genetic algorithm (GA), NAS-G, to search for the best CNN architecture. Firstly, we attach each kernel with an adaptive coefficient to enhance the signal processing of the inputs. This can enhance the propagation of informative features and suppress the propagation of useless features in the early stage of the network. Then, we make full use of GA's heuristic search and the advantage of no need for the gradient to search for the best architecture of CNN. This can achieve a CNN with better performance than a handcrafted one in a large search space at the minimum cost. We verify the convergence of our data processing trick and compare the performance of traditional CNNs before and after using our trick. Meanwhile, we compare the performance between the CNN generated through NAS-G and the traditional CNNs with our trick. The experiments demonstrate that the convergence of CNNs with data processing trick is faster than without data processing trick and the CNN with data processing trick generated by NAS-G outperforms the handcrafted counterparts that use the data processing trick too.