 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViM-Q: Scalable Algorithm-Hardware Co-Design for Vision Mamba Model Inference on FPGA
May 03, 2026Vision Mamba (ViM) models offer a compelling efficiency advantage over Transformers by leveraging the linear complexity of State Space Models (SSMs), yet efficiently deploying them on FPGAs remains challenging. Linear layers struggle with dynamic activation outliers that render static quantization ineffective, while uniform quantization fails to capture the weight distribution at low bit-widths. Furthermore, while associative scan accelerates SSMs on GPUs, its memory access patterns are misaligned with the streaming dataflow required by FPGAs. To address these challenges, we present ViM-Q, a scalable algorithm-hardware co-design for end-to-end ViM inference on the edge. We introduce a hardware-aware quantization scheme combining dynamic per-token activation quantization and per-channel smoothing to mitigate outliers, alongside a custom 4-bit per-block Additive Power-of-Two (APoT) weight quantization. The models are deployed on a runtime-parameterizable FPGA accelerator featuring a linear engine employing a Lookup-Table (LUT) unit to replace multiplications with shift-add operations, and a fine-grained pipelined SSM engine that parallelizes the state dimension while preserving sequential recurrence. Crucially, the hardware supports runtime configuration, adapting to diverse dimensions and input resolutions across the ViM family. Implemented on an AMD ZCU102 FPGA, ViM-Q achieves an average 4.96x speedup and 59.8x energy efficiency gain over a quantized NVIDIA RTX 3090 GPU baseline for low-batch inference on ViM-tiny. This co-design shows a viable path for deploying ViM models on resource-constrained edge devices.
SwiftChannel: Algorithm-Hardware Co-Design for Deep Learning-Based 5G Channel Estimation
May 03, 2026Channel estimation is crucial in 5G communication networks for optimizing transmission parameters and ensuring reliable, high-speed communication. However, the use of multiple-input and multiple-output (MIMO) and millimeter-wave (mmWave) in 5G networks presents challenges in achieving accurate estimation under strict latency requirements on resource-limited hardware platforms. To address these challenges, we propose SwiftChannel, an algorithm-hardware co-design framework that integrates a hardware-friendly deep learning-based channel estimator with a dedicated accelerator. Our approach employs a convolutional neural network enhanced with a parameter-free attention mechanism, which effectively reconstructs full-resolution spatial-frequency domain channel matrices from low-resolution least squares (LS) estimates. We further develop a multi-stage model compression pipeline combining knowledge distillation, convolution re-parameterization, and quantization-aware training, resulting in substantial model size reduction with negligible accuracy loss. The hardware accelerator, implementing the compressed model and the LS estimator on FPGA platforms using High-level Synthesis (HLS), features a fine-grained pipeline architecture and optimized dataflow strategies. Tested on a Zynq UltraScale+ RFSoC, the accelerator achieves sub-millisecond latency, providing up to 24x speed-up and over 33x improvement in energy efficiency compared to GPU-based solutions. Extensive evaluations demonstrate that the proposed design generalizes not only across various noise levels and user mobilities, but also to a variety of unseen channel profiles, outperforming state-of-the-art baselines. By unifying algorithmic innovation with hardware-aware design, our work presents a future-proof channel estimation solution for 5G MIMO systems.
MoToRec: Sparse-Regularized Multimodal Tokenization for Cold-Start Recommendation
Feb 11, 2026Graph neural networks (GNNs) have revolutionized recommender systems by effectively modeling complex user-item interactions, yet data sparsity and the item cold-start problem significantly impair performance, particularly for new items with limited or no interaction history. While multimodal content offers a promising solution, existing methods result in suboptimal representations for new items due to noise and entanglement in sparse data. To address this, we transform multimodal recommendation into discrete semantic tokenization. We present Sparse-Regularized Multimodal Tokenization for Cold-Start Recommendation (MoToRec), a framework centered on a sparsely-regularized Residual Quantized Variational Autoencoder (RQ-VAE) that generates a compositional semantic code of discrete, interpretable tokens, promoting disentangled representations. MoToRec's architecture is enhanced by three synergistic components: (1) a sparsely-regularized RQ-VAE that promotes disentangled representations, (2) a novel adaptive rarity amplification that promotes prioritized learning for cold-start items, and (3) a hierarchical multi-source graph encoder for robust signal fusion with collaborative signals. Extensive experiments on three large-scale datasets demonstrate MoToRec's superiority over state-of-the-art methods in both overall and cold-start scenarios. Our work validates that discrete tokenization provides an effective and scalable alternative for mitigating the long-standing cold-start challenge.
RO-SVD: A Reconfigurable Hardware Copyright Protection Framework for AIGC Applications
Jun 17, 2024



The dramatic surge in the utilisation of generative artificial intelligence (GenAI) underscores the need for a secure and efficient mechanism to responsibly manage, use and disseminate multi-dimensional data generated by artificial intelligence (AI). In this paper, we propose a blockchain-based copyright traceability framework called ring oscillator-singular value decomposition (RO-SVD), which introduces decomposition computing to approximate low-rank matrices generated from hardware entropy sources and establishes an AI-generated content (AIGC) copyright traceability mechanism at the device level. By leveraging the parallelism and reconfigurability of field-programmable gate arrays (FPGAs), our framework can be easily constructed on existing AI-accelerated devices and provide a low-cost solution to emerging copyright issues of AIGC. We developed a hardware-software (HW/SW) co-design prototype based on comprehensive analysis and on-board experiments with multiple AI-applicable FPGAs. Using AI-generated images as a case study, our framework demonstrated effectiveness and emphasised customisation, unpredictability, efficiency, management and reconfigurability. To the best of our knowledge, this is the first practical hardware study discussing and implementing copyright traceability specifically for AI-generated content.
Gradient-Congruity Guided Federated Sparse Training
May 02, 2024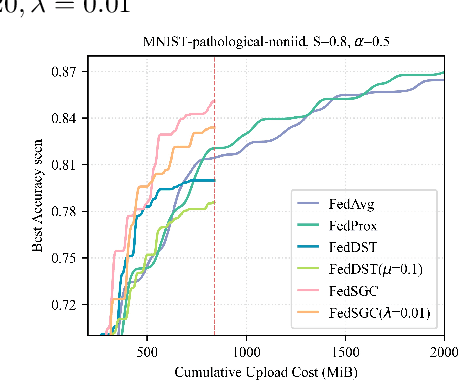
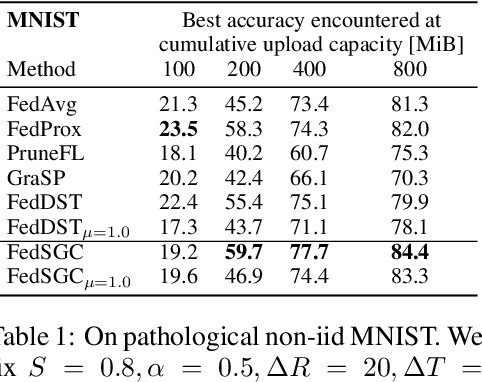
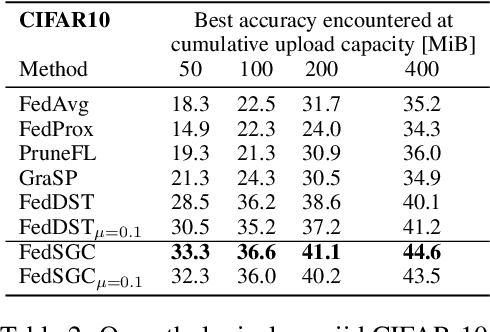
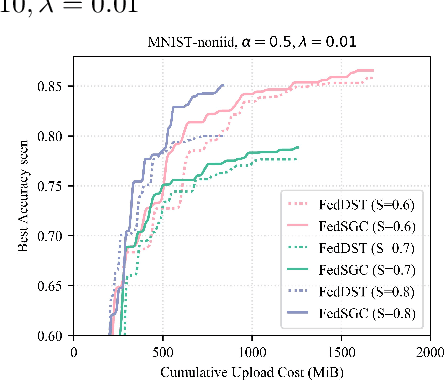
Edge computing allows artificial intelligence and machine learning models to be deployed on edge devices, where they can learn from local data and collaborate to form a global model. Federated learning (FL) is a distributed machine learning technique that facilitates this process while preserving data privacy. However, FL also faces challenges such as high computational and communication costs regarding resource-constrained devices, and poor generalization performance due to the heterogeneity of data across edge clients and the presence of out-of-distribution data. In this paper, we propose the Gradient-Congruity Guided Federated Sparse Training (FedSGC), a novel method that integrates dynamic sparse training and gradient congruity inspection into federated learning framework to address these issues. Our method leverages the idea that the neurons, in which the associated gradients with conflicting directions with respect to the global model contain irrelevant or less generalized information for other clients, and could be pruned during the sparse training process. Conversely, the neurons where the associated gradients with consistent directions could be grown in a higher priority. In this way, FedSGC can greatly reduce the local computation and communication overheads while, at the same time, enhancing the generalization abilities of FL. We evaluate our method on challenging non-i.i.d settings and show that it achieves competitive accuracy with state-of-the-art FL methods across various scenarios while minimizing computation and communication costs.
Experiment-based deep learning approach for power allocation with a programmable metasurface
Jul 26, 2023



Deep learning, as a highly efficient method for metasurface inverse design, commonly use simulation data to train deep neural networks (DNNs) that can map desired functionalities to proper metasurface designs. However, the assumptions and simplifications made in the simulation model may not reflect the actual behavior of a complex system, leading to suboptimal performance of the DNNs in practical scenarios. To address this issue, we propose an experiment-based deep learning approach for metasurface inverse design and demonstrate its effectiveness for power allocation in complex environments with obstacles. Enabled by the tunability of a programmable metasurface, large sets of experimental data in various configurations can be collected for DNN training. The DNN trained by experimental data can inherently incorporate complex factors and can adapt to changed environments through its on-site data-collecting and fast-retraining capability. The proposed experiment-based DNN holds the potential for intelligent and energy-efficient wireless communication in complex indoor environments.
Bidirectionally Deformable Motion Modulation For Video-based Human Pose Transfer
Jul 18, 2023



Video-based human pose transfer is a video-to-video generation task that animates a plain source human image based on a series of target human poses. Considering the difficulties in transferring highly structural patterns on the garments and discontinuous poses, existing methods often generate unsatisfactory results such as distorted textures and flickering artifacts. To address these issues, we propose a novel Deformable Motion Modulation (DMM) that utilizes geometric kernel offset with adaptive weight modulation to simultaneously perform feature alignment and style transfer. Different from normal style modulation used in style transfer, the proposed modulation mechanism adaptively reconstructs smoothed frames from style codes according to the object shape through an irregular receptive field of view. To enhance the spatio-temporal consistency, we leverage bidirectional propagation to extract the hidden motion information from a warped image sequence generated by noisy poses. The proposed feature propagation significantly enhances the motion prediction ability by forward and backward propagation. Both quantitative and qualitative experimental results demonstrate superiority over the state-of-the-arts in terms of image fidelity and visual continuity. The source code is publicly available at github.com/rocketappslab/bdmm.
Dynamic Sparse Training: Find Efficient Sparse Network From Scratch With Trainable Masked Layers
May 14, 2020
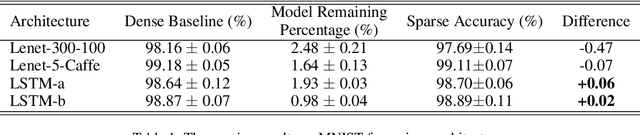

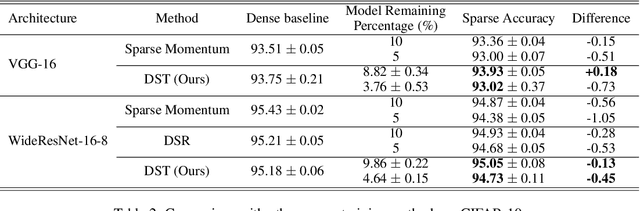
We present a novel network pruning algorithm called Dynamic Sparse Training that can jointly find the optimal network parameters and sparse network structure in a unified optimization process with trainable pruning thresholds. These thresholds can have fine-grained layer-wise adjustments dynamically via backpropagation. We demonstrate that our dynamic sparse training algorithm can easily train very sparse neural network models with little performance loss using the same number of training epochs as dense models. Dynamic Sparse Training achieves the state of the art performance compared with other sparse training algorithms on various network architectures. Additionally, we have several surprising observations that provide strong evidence for the effectiveness and efficiency of our algorithm. These observations reveal the underlying problems of traditional three-stage pruning algorithms and present the potential guidance provided by our algorithm to the design of more compact network architectures.
Accurate and Compact Convolutional Neural Networks with Trained Binarization
Sep 25, 2019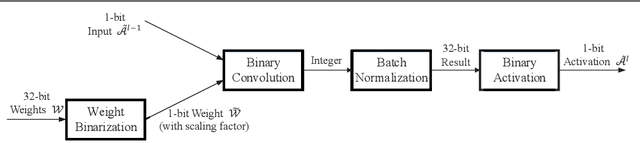
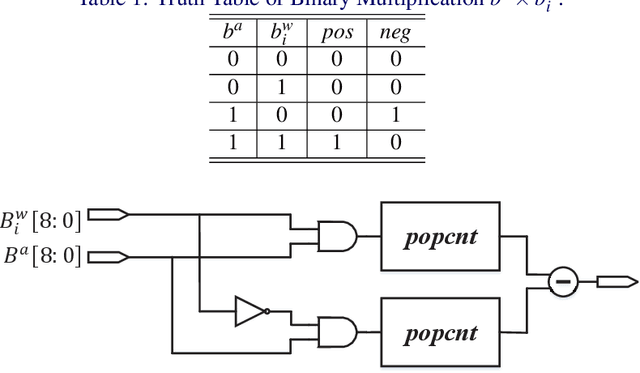
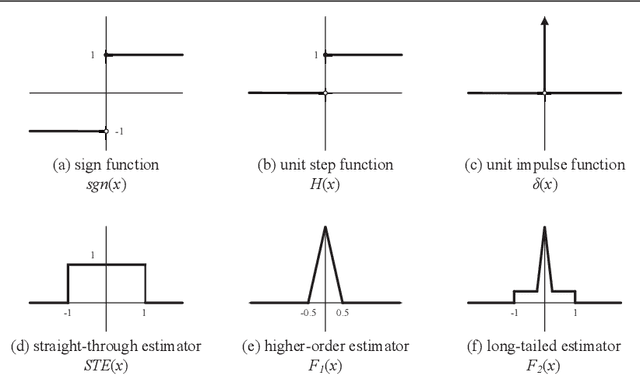
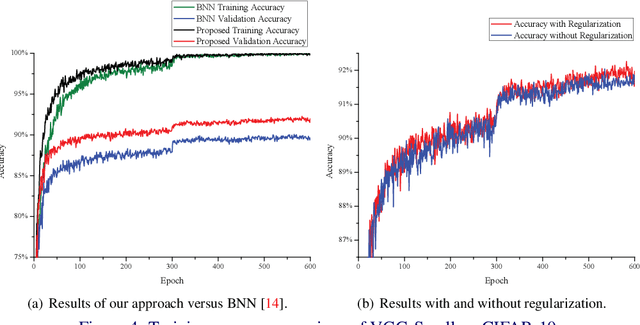
Although convolutional neural networks (CNNs) are now widely used in various computer vision applications, its huge resource demanding on parameter storage and computation makes the deployment on mobile and embedded devices difficult. Recently, binary convolutional neural networks are explored to help alleviate this issue by quantizing both weights and activations with only 1 single bit. However, there may exist a noticeable accuracy degradation when compared with full-precision models. In this paper, we propose an improved training approach towards compact binary CNNs with higher accuracy. Trainable scaling factors for both weights and activations are introduced to increase the value range. These scaling factors will be trained jointly with other parameters via backpropagation. Besides, a specific training algorithm is developed including tight approximation for derivative of discontinuous binarization function and $L_2$ regularization acting on weight scaling factors. With these improvements, the binary CNN achieves 92.3% accuracy on CIFAR-10 with VGG-Small network. On ImageNet, our method also obtains 46.1% top-1 accuracy with AlexNet and 54.2% with Resnet-18 surpassing previous works.
A Robust Background Initialization Algorithm with Superpixel Motion Detection
May 17, 2018
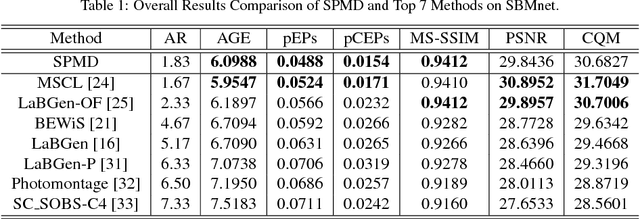
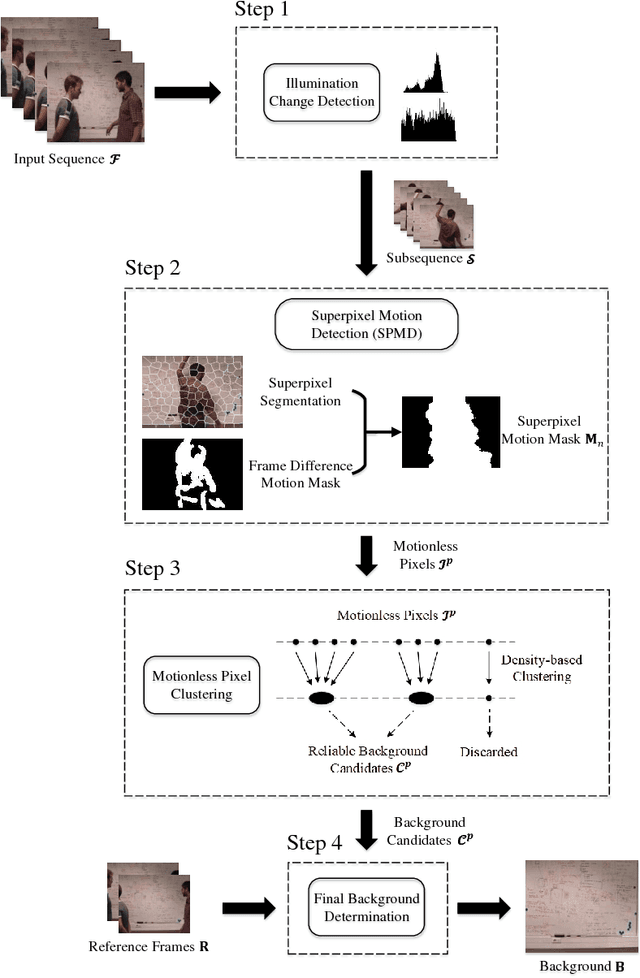
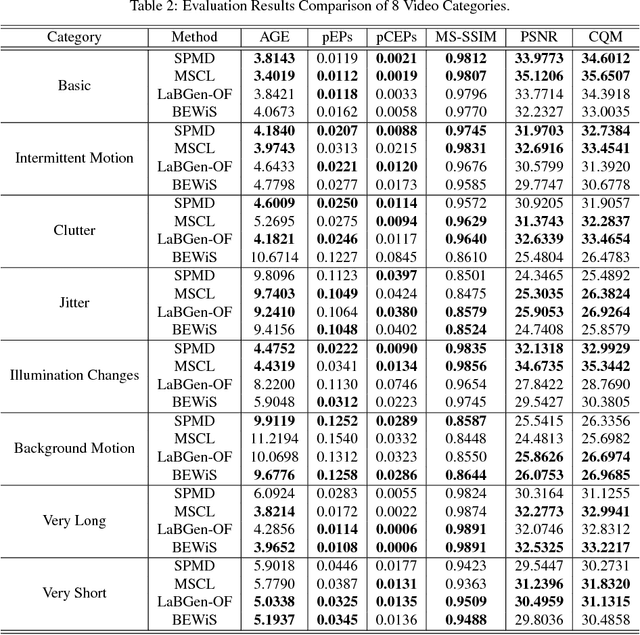
Scene background initialization allows the recovery of a clear image without foreground objects from a video sequence, which is generally the first step in many computer vision and video processing applications. The process may be strongly affected by some challenges such as illumination changes, foreground cluttering, intermittent movement, etc. In this paper, a robust background initialization approach based on superpixel motion detection is proposed. Both spatial and temporal characteristics of frames are adopted to effectively eliminate foreground objects. A subsequence with stable illumination condition is first selected for background estimation. Images are segmented into superpixels to preserve spatial texture information and foreground objects are eliminated by superpixel motion filtering process. A low-complexity density-based clustering is then performed to generate reliable background candidates for final background determination. The approach has been evaluated on SBMnet dataset and it achieves a performance superior or comparable to other state-of-the-art works with faster processing speed. Moreover, in those complex and dynamic categories, the algorithm produces the best results showing the robustness against very challenging scenarios.