 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Less is More: The LLM Scaling Paradox in Context Compression
Feb 10, 2026Scaling up model parameters has long been a prevalent training paradigm driven by the assumption that larger models yield superior generation capabilities. However, under lossy context compression in a compressor-decoder setup, we observe a Size-Fidelity Paradox: increasing the compressor size can lessen the faithfulness of reconstructed contexts though training loss decreases. Through extensive experiments across models from 0.6B to 90B, we coin this paradox arising from two dominant factors: 1) knowledge overwriting: larger models increasingly replace source facts with their own prior beliefs, e.g., ``the white strawberry'' $\to$ ``the red strawberry''; and 2) semantic drift: larger models tend to paraphrase or restructure content instead of reproducing it verbatim, e.g., ``Alice hit Bob'' $\to$ ``Bob hit Alice''. By holding model size fixed, we reflect on the emergent properties of compressed context representations. We show that the culprit is not parameter count itself, but the excessive semantic capacity and amplified generative uncertainty that accompany scaling. Specifically, the increased rank of context embeddings facilitates prior knowledge intrusion, whereas higher entropy over token prediction distributions promotes rewriting. Our results complement existing evaluations over context compression paradigm, underpinning a breakdown in scaling laws for faithful preservation in open-ended generation.
TrajAD: Trajectory Anomaly Detection for Trustworthy LLM Agents
Feb 06, 2026We address the problem of runtime trajectory anomaly detection, a critical capability for enabling trustworthy LLM agents. Current safety measures predominantly focus on static input/output filtering. However, we argue that ensuring LLM agents reliability requires auditing the intermediate execution process. In this work, we formulate the task of Trajectory Anomaly Detection. The goal is not merely detection, but precise error localization. This capability is essential for enabling efficient rollback-and-retry. To achieve this, we construct TrajBench, a dataset synthesized via a perturb-and-complete strategy to cover diverse procedural anomalies. Using this benchmark, we investigate the capability of models in process supervision. We observe that general-purpose LLMs, even with zero-shot prompting, struggle to identify and localize these anomalies. This reveals that generalized capabilities do not automatically translate to process reliability. To address this, we propose TrajAD, a specialized verifier trained with fine-grained process supervision. Our approach outperforms baselines, demonstrating that specialized supervision is essential for building trustworthy agents.
Enhancing Zero-Shot Image Recognition in Vision-Language Models through Human-like Concept Guidance
Mar 21, 2025
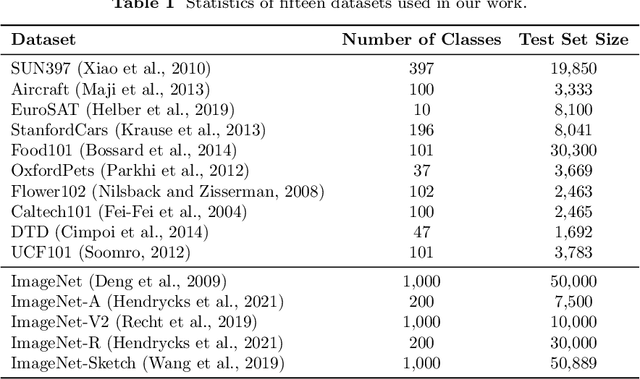


In zero-shot image recognition tasks, humans demonstrate remarkable flexibility in classifying unseen categories by composing known simpler concepts. However, existing vision-language models (VLMs), despite achieving significant progress through large-scale natural language supervision, often underperform in real-world applications because of sub-optimal prompt engineering and the inability to adapt effectively to target classes. To address these issues, we propose a Concept-guided Human-like Bayesian Reasoning (CHBR) framework. Grounded in Bayes' theorem, CHBR models the concept used in human image recognition as latent variables and formulates this task by summing across potential concepts, weighted by a prior distribution and a likelihood function. To tackle the intractable computation over an infinite concept space, we introduce an importance sampling algorithm that iteratively prompts large language models (LLMs) to generate discriminative concepts, emphasizing inter-class differences. We further propose three heuristic approaches involving Average Likelihood, Confidence Likelihood, and Test Time Augmentation (TTA) Likelihood, which dynamically refine the combination of concepts based on the test image. Extensive evaluations across fifteen datasets demonstrate that CHBR consistently outperforms existing state-of-the-art zero-shot generalization methods.
Large Language Models for Lossless Image Compression: Next-Pixel Prediction in Language Space is All You Need
Nov 19, 2024



We have recently witnessed that ``Intelligence" and `` Compression" are the two sides of the same coin, where the language large model (LLM) with unprecedented intelligence is a general-purpose lossless compressor for various data modalities. This attribute particularly appeals to the lossless image compression community, given the increasing need to compress high-resolution images in the current streaming media era. Consequently, a spontaneous envision emerges: Can the compression performance of the LLM elevate lossless image compression to new heights? However, our findings indicate that the naive application of LLM-based lossless image compressors suffers from a considerable performance gap compared with existing state-of-the-art (SOTA) codecs on common benchmark datasets. In light of this, we are dedicated to fulfilling the unprecedented intelligence (compression) capacity of the LLM for lossless image compression tasks, thereby bridging the gap between theoretical and practical compression performance. Specifically, we propose P$^{2}$-LLM, a next-pixel prediction-based LLM, which integrates various elaborated insights and methodologies, \textit{e.g.,} pixel-level priors, the in-context ability of LLM, and a pixel-level semantic preservation strategy, to enhance the understanding capacity of pixel sequences for better next-pixel predictions. Extensive experiments on benchmark datasets demonstrate that P$^{2}$-LLM can beat SOTA classical and learned codecs.
Gradient-Congruity Guided Federated Sparse Training
May 02, 2024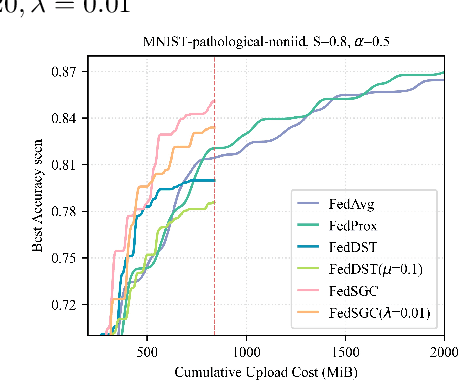
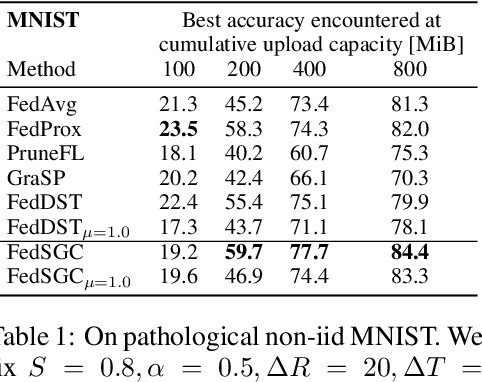
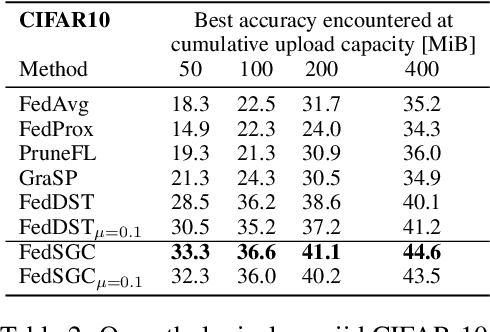
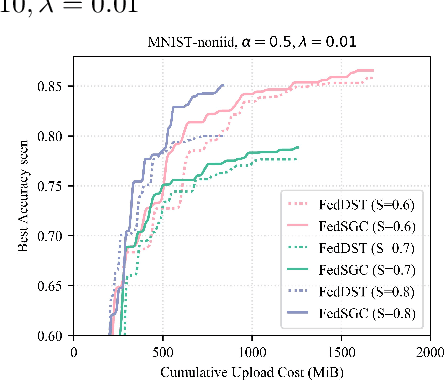
Edge computing allows artificial intelligence and machine learning models to be deployed on edge devices, where they can learn from local data and collaborate to form a global model. Federated learning (FL) is a distributed machine learning technique that facilitates this process while preserving data privacy. However, FL also faces challenges such as high computational and communication costs regarding resource-constrained devices, and poor generalization performance due to the heterogeneity of data across edge clients and the presence of out-of-distribution data. In this paper, we propose the Gradient-Congruity Guided Federated Sparse Training (FedSGC), a novel method that integrates dynamic sparse training and gradient congruity inspection into federated learning framework to address these issues. Our method leverages the idea that the neurons, in which the associated gradients with conflicting directions with respect to the global model contain irrelevant or less generalized information for other clients, and could be pruned during the sparse training process. Conversely, the neurons where the associated gradients with consistent directions could be grown in a higher priority. In this way, FedSGC can greatly reduce the local computation and communication overheads while, at the same time, enhancing the generalization abilities of FL. We evaluate our method on challenging non-i.i.d settings and show that it achieves competitive accuracy with state-of-the-art FL methods across various scenarios while minimizing computation and communication costs.
Neuron Activation Coverage: Rethinking Out-of-distribution Detection and Generalization
Jun 05, 2023



The out-of-distribution (OOD) problem generally arises when neural networks encounter data that significantly deviates from the training data distribution, \ie, in-distribution (InD). In this paper, we study the OOD problem from a neuron activation view. We first formulate neuron activation states by considering both the neuron output and its influence on model decisions. Then, we propose the concept of \textit{neuron activation coverage} (NAC), which characterizes the neuron behaviors under InD and OOD data. Leveraging our NAC, we show that 1) InD and OOD inputs can be naturally separated based on the neuron behavior, which significantly eases the OOD detection problem and achieves a record-breaking performance of 0.03% FPR95 on ResNet-50, outperforming the previous best method by 20.67%; 2) a positive correlation between NAC and model generalization ability consistently holds across architectures and datasets, which enables a NAC-based criterion for evaluating model robustness. By comparison with the traditional validation criterion, we show that NAC-based criterion not only can select more robust models, but also has a stronger correlation with OOD test performance.
M3FAS: An Accurate and Robust MultiModal Mobile Face Anti-Spoofing System
Feb 03, 2023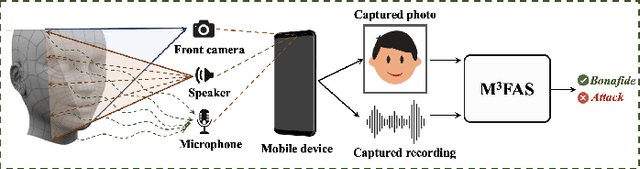
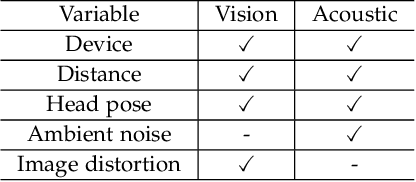
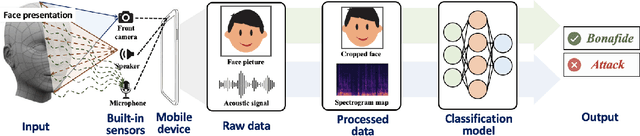
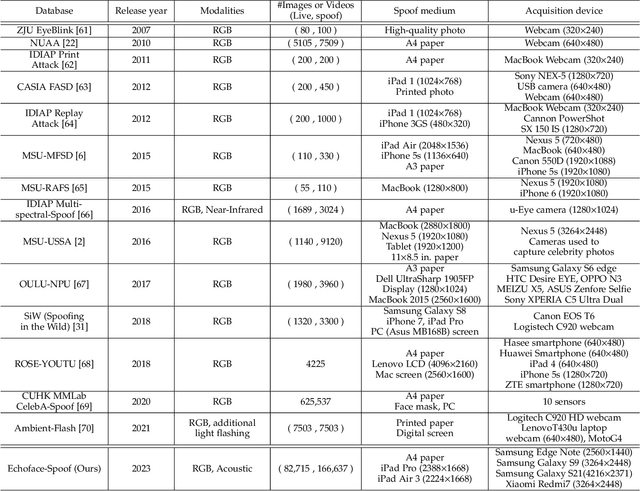
Face presentation attacks (FPA), also known as face spoofing, have brought increasing concerns to the public through various malicious applications, such as financial fraud and privacy leakage. Therefore, safeguarding face recognition systems against FPA is of utmost importance. Although existing learning-based face anti-spoofing (FAS) models can achieve outstanding detection performance, they lack generalization capability and suffer significant performance drops in unforeseen environments. Many methodologies seek to use auxiliary modality data (e.g., depth and infrared maps) during the presentation attack detection (PAD) to address this limitation. However, these methods can be limited since (1) they require specific sensors such as depth and infrared cameras for data capture, which are rarely available on commodity mobile devices, and (2) they cannot work properly in practical scenarios when either modality is missing or of poor quality. In this paper, we devise an accurate and robust MultiModal Mobile Face Anti-Spoofing system named M3FAS to overcome the issues above. The innovation of this work mainly lies in the following aspects: (1) To achieve robust PAD, our system combines visual and auditory modalities using three pervasively available sensors: camera, speaker, and microphone; (2) We design a novel two-branch neural network with three hierarchical feature aggregation modules to perform cross-modal feature fusion; (3). We propose a multi-head training strategy. The model outputs three predictions from the vision, acoustic, and fusion heads, enabling a more flexible PAD. Extensive experiments have demonstrated the accuracy, robustness, and flexibility of M3FAS under various challenging experimental settings.
Generalization Beyond Feature Alignment: Concept Activation-Guided Contrastive Learning
Nov 13, 2022Learning invariant representations via contrastive learning has seen state-of-the-art performance in domain generalization (DG). Despite such success, in this paper, we find that its core learning strategy -- feature alignment -- could heavily hinder the model generalization. Inspired by the recent progress in neuron interpretability, we characterize this problem from a neuron activation view. Specifically, by treating feature elements as neuron activation states, we show that conventional alignment methods tend to deteriorate the diversity of learned invariant features, as they indiscriminately minimize all neuron activation differences. This instead ignores rich relations among neurons -- many of them often identify the same visual concepts though they emerge differently. With this finding, we present a simple yet effective approach, \textit{Concept Contrast} (CoCo), which relaxes element-wise feature alignments by contrasting high-level concepts encoded in neurons. This approach is highly flexible and can be integrated into any contrastive method in DG. Through extensive experiments, we further demonstrate that our CoCo promotes the diversity of feature representations, and consistently improves model generalization capability over the DomainBed benchmark.
A Unified End-to-End Retriever-Reader Framework for Knowledge-based VQA
Jun 30, 2022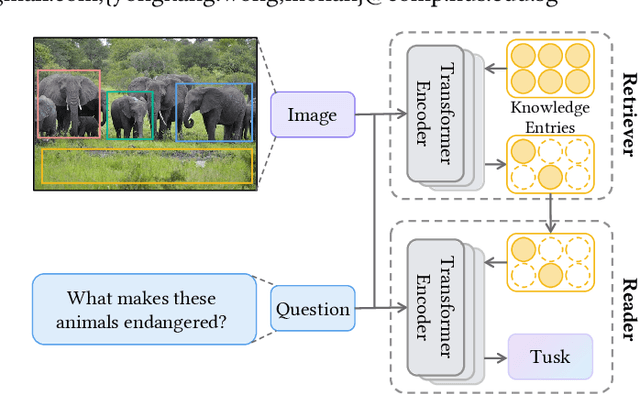
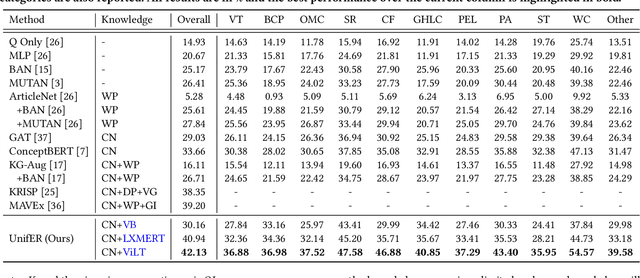
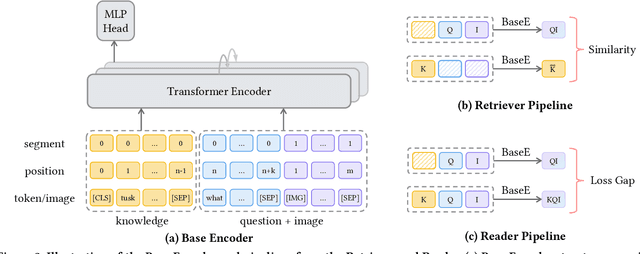
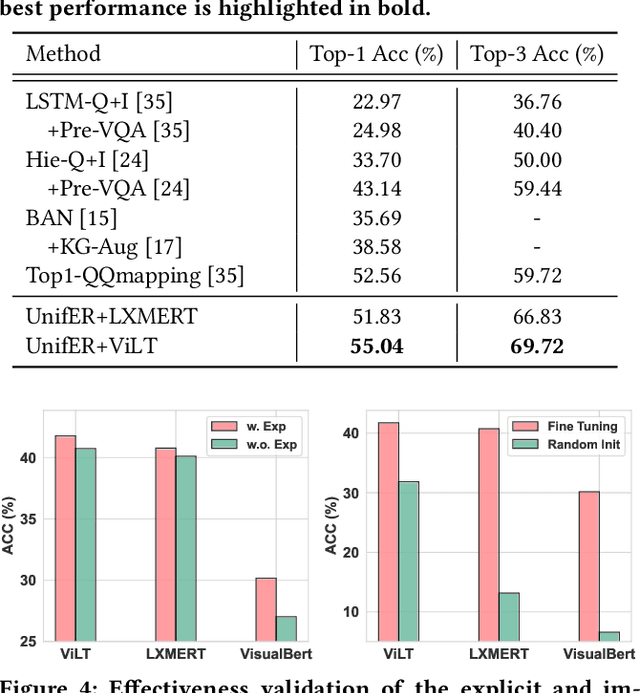
Knowledge-based Visual Question Answering (VQA) expects models to rely on external knowledge for robust answer prediction. Though significant it is, this paper discovers several leading factors impeding the advancement of current state-of-the-art methods. On the one hand, methods which exploit the explicit knowledge take the knowledge as a complement for the coarsely trained VQA model. Despite their effectiveness, these approaches often suffer from noise incorporation and error propagation. On the other hand, pertaining to the implicit knowledge, the multi-modal implicit knowledge for knowledge-based VQA still remains largely unexplored. This work presents a unified end-to-end retriever-reader framework towards knowledge-based VQA. In particular, we shed light on the multi-modal implicit knowledge from vision-language pre-training models to mine its potential in knowledge reasoning. As for the noise problem encountered by the retrieval operation on explicit knowledge, we design a novel scheme to create pseudo labels for effective knowledge supervision. This scheme is able to not only provide guidance for knowledge retrieval, but also drop these instances potentially error-prone towards question answering. To validate the effectiveness of the proposed method, we conduct extensive experiments on the benchmark dataset. The experimental results reveal that our method outperforms existing baselines by a noticeable margin. Beyond the reported numbers, this paper further spawns several insights on knowledge utilization for future research with some empirical findings.
Rethinking Attention-Model Explainability through Faithfulness Violation Test
Jan 28, 2022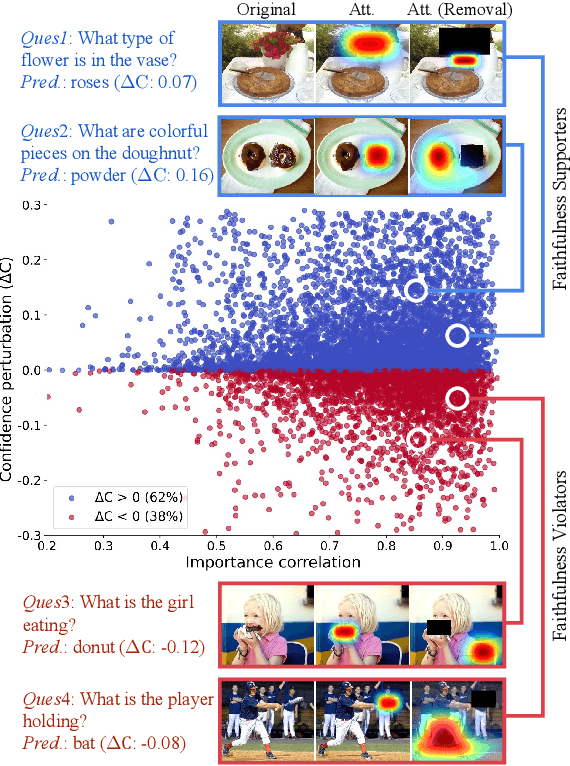
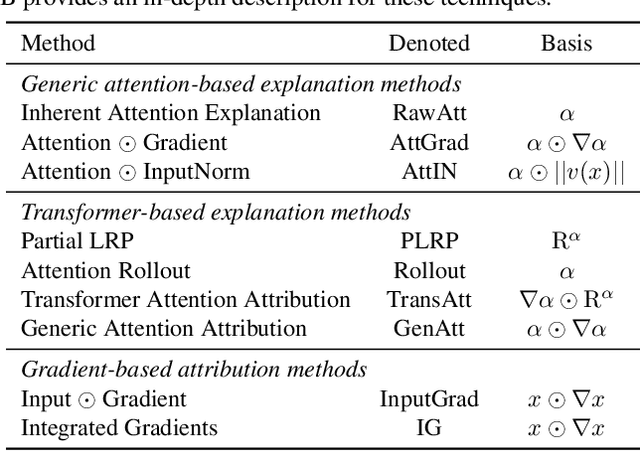
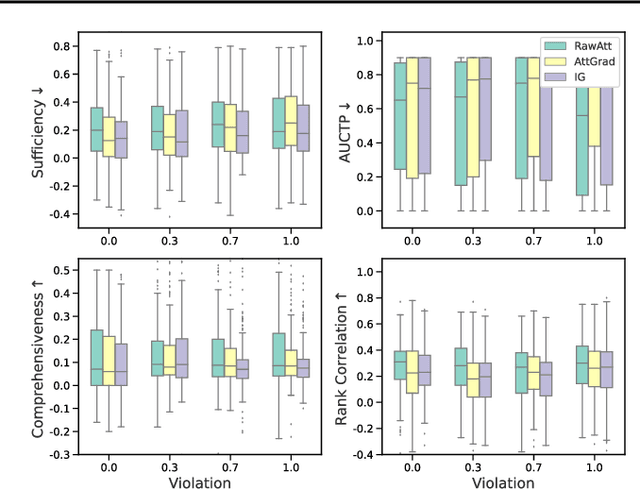
Attention mechanisms are dominating the explainability of deep models. They produce probability distributions over the input, which are widely deemed as feature-importance indicators. However, in this paper, we find one critical limitation in attention explanations: weakness in identifying the polarity of feature impact. This would be somehow misleading -- features with higher attention weights may not faithfully contribute to model predictions; instead, they can impose suppression effects. With this finding, we reflect on the explainability of current attention-based techniques, such as Attentio$\odot$Gradient and LRP-based attention explanations. We first propose an actionable diagnostic methodology (henceforth faithfulness violation test) to measure the consistency between explanation weights and the impact polarity. Through the extensive experiments, we then show that most tested explanation methods are unexpectedly hindered by the faithfulness violation issue, especially the raw attention. Empirical analyses on the factors affecting violation issues further provide useful observations for adopting explanation methods in attention models.