 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM3FAS: An Accurate and Robust MultiModal Mobile Face Anti-Spoofing System
Paper and Code
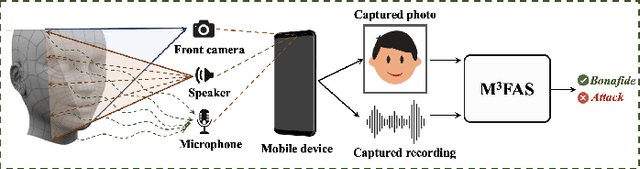
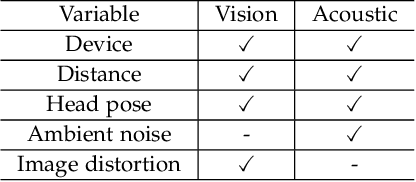
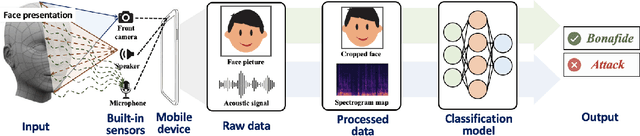
Face presentation attacks (FPA), also known as face spoofing, have brought increasing concerns to the public through various malicious applications, such as financial fraud and privacy leakage. Therefore, safeguarding face recognition systems against FPA is of utmost importance. Although existing learning-based face anti-spoofing (FAS) models can achieve outstanding detection performance, they lack generalization capability and suffer significant performance drops in unforeseen environments. Many methodologies seek to use auxiliary modality data (e.g., depth and infrared maps) during the presentation attack detection (PAD) to address this limitation. However, these methods can be limited since (1) they require specific sensors such as depth and infrared cameras for data capture, which are rarely available on commodity mobile devices, and (2) they cannot work properly in practical scenarios when either modality is missing or of poor quality. In this paper, we devise an accurate and robust MultiModal Mobile Face Anti-Spoofing system named M3FAS to overcome the issues above. The innovation of this work mainly lies in the following aspects: (1) To achieve robust PAD, our system combines visual and auditory modalities using three pervasively available sensors: camera, speaker, and microphone; (2) We design a novel two-branch neural network with three hierarchical feature aggregation modules to perform cross-modal feature fusion; (3). We propose a multi-head training strategy. The model outputs three predictions from the vision, acoustic, and fusion heads, enabling a more flexible PAD. Extensive experiments have demonstrated the accuracy, robustness, and flexibility of M3FAS under various challenging experimental settings.