 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Agent: Dynamic Discourse Trees for Non-Linear Dialogue
Apr 07, 2026Large Language Models demonstrate outstanding performance in many language tasks but still face fundamental challenges in managing the non-linear flow of human conversation. The prevalent approach of treating dialogue history as a flat, linear sequence is misaligned with the intrinsically hierarchical and branching structure of natural discourse, leading to inefficient context utilization and a loss of coherence during extended interactions involving topic shifts or instruction refinements. To address this limitation, we introduce Context-Agent, a novel framework that models multi-turn dialogue history as a dynamic tree structure. This approach mirrors the inherent non-linearity of conversation, enabling the model to maintain and navigate multiple dialogue branches corresponding to different topics. Furthermore, to facilitate robust evaluation, we introduce the Non-linear Task Multi-turn Dialogue (NTM) benchmark, specifically designed to assess model performance in long-horizon, non-linear scenarios. Our experiments demonstrate that Context-Agent enhances task completion rates and improves token efficiency across various LLMs, underscoring the value of structured context management for complex, dynamic dialogues. The dataset and code is available at GitHub.
Mitigating Hallucination Through Theory-Consistent Symmetric Multimodal Preference Optimization
Jun 13, 2025



Direct Preference Optimization (DPO) has emerged as an effective approach for mitigating hallucination in Multimodal Large Language Models (MLLMs). Although existing methods have achieved significant progress by utilizing vision-oriented contrastive objectives for enhancing MLLMs' attention to visual inputs and hence reducing hallucination, they suffer from non-rigorous optimization objective function and indirect preference supervision. To address these limitations, we propose a Symmetric Multimodal Preference Optimization (SymMPO), which conducts symmetric preference learning with direct preference supervision (i.e., response pairs) for visual understanding enhancement, while maintaining rigorous theoretical alignment with standard DPO. In addition to conventional ordinal preference learning, SymMPO introduces a preference margin consistency loss to quantitatively regulate the preference gap between symmetric preference pairs. Comprehensive evaluation across five benchmarks demonstrate SymMPO's superior performance, validating its effectiveness in hallucination mitigation of MLLMs.
Visual SLAM with 3D Gaussian Primitives and Depth Priors Enabling Novel View Synthesis
Aug 10, 2024


Conventional geometry-based SLAM systems lack dense 3D reconstruction capabilities since their data association usually relies on feature correspondences. Additionally, learning-based SLAM systems often fall short in terms of real-time performance and accuracy. Balancing real-time performance with dense 3D reconstruction capabilities is a challenging problem. In this paper, we propose a real-time RGB-D SLAM system that incorporates a novel view synthesis technique, 3D Gaussian Splatting, for 3D scene representation and pose estimation. This technique leverages the real-time rendering performance of 3D Gaussian Splatting with rasterization and allows for differentiable optimization in real time through CUDA implementation. We also enable mesh reconstruction from 3D Gaussians for explicit dense 3D reconstruction. To estimate accurate camera poses, we utilize a rotation-translation decoupled strategy with inverse optimization. This involves iteratively updating both in several iterations through gradient-based optimization. This process includes differentiably rendering RGB, depth, and silhouette maps and updating the camera parameters to minimize a combined loss of photometric loss, depth geometry loss, and visibility loss, given the existing 3D Gaussian map. However, 3D Gaussian Splatting (3DGS) struggles to accurately represent surfaces due to the multi-view inconsistency of 3D Gaussians, which can lead to reduced accuracy in both camera pose estimation and scene reconstruction. To address this, we utilize depth priors as additional regularization to enforce geometric constraints, thereby improving the accuracy of both pose estimation and 3D reconstruction. We also provide extensive experimental results on public benchmark datasets to demonstrate the effectiveness of our proposed methods in terms of pose accuracy, geometric accuracy, and rendering performance.
Data-free Knowledge Distillation for Fine-grained Visual Categorization
Apr 18, 2024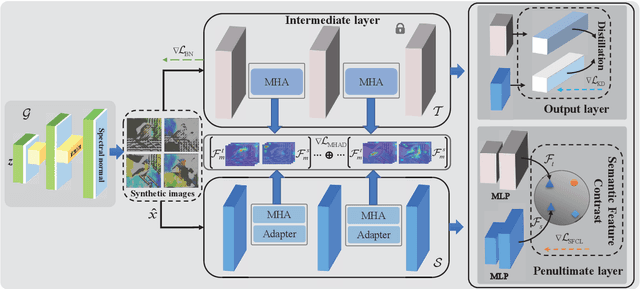
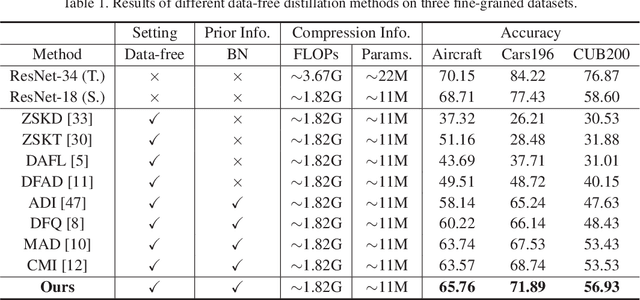
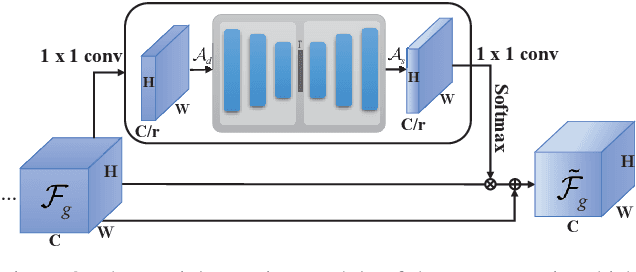
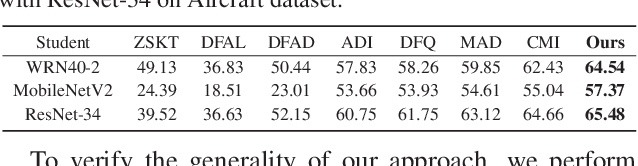
Data-free knowledge distillation (DFKD) is a promising approach for addressing issues related to model compression, security privacy, and transmission restrictions. Although the existing methods exploiting DFKD have achieved inspiring achievements in coarse-grained classification, in practical applications involving fine-grained classification tasks that require more detailed distinctions between similar categories, sub-optimal results are obtained. To address this issue, we propose an approach called DFKD-FGVC that extends DFKD to fine-grained visual categorization~(FGVC) tasks. Our approach utilizes an adversarial distillation framework with attention generator, mixed high-order attention distillation, and semantic feature contrast learning. Specifically, we introduce a spatial-wise attention mechanism to the generator to synthesize fine-grained images with more details of discriminative parts. We also utilize the mixed high-order attention mechanism to capture complex interactions among parts and the subtle differences among discriminative features of the fine-grained categories, paying attention to both local features and semantic context relationships. Moreover, we leverage the teacher and student models of the distillation framework to contrast high-level semantic feature maps in the hyperspace, comparing variances of different categories. We evaluate our approach on three widely-used FGVC benchmarks (Aircraft, Cars196, and CUB200) and demonstrate its superior performance.
HS-GCN: Hamming Spatial Graph Convolutional Networks for Recommendation
Jan 13, 2023



An efficient solution to the large-scale recommender system is to represent users and items as binary hash codes in the Hamming space. Towards this end, existing methods tend to code users by modeling their Hamming similarities with the items they historically interact with, which are termed as the first-order similarities in this work. Despite their efficiency, these methods suffer from the suboptimal representative capacity, since they forgo the correlation established by connecting multiple first-order similarities, i.e., the relation among the indirect instances, which could be defined as the high-order similarity. To tackle this drawback, we propose to model both the first- and the high-order similarities in the Hamming space through the user-item bipartite graph. Therefore, we develop a novel learning to hash framework, namely Hamming Spatial Graph Convolutional Networks (HS-GCN), which explicitly models the Hamming similarity and embeds it into the codes of users and items. Extensive experiments on three public benchmark datasets demonstrate that our proposed model significantly outperforms several state-of-the-art hashing models, and obtains performance comparable with the real-valued recommendation models.
Visual Perturbation-aware Collaborative Learning for Overcoming the Language Prior Problem
Jul 24, 2022
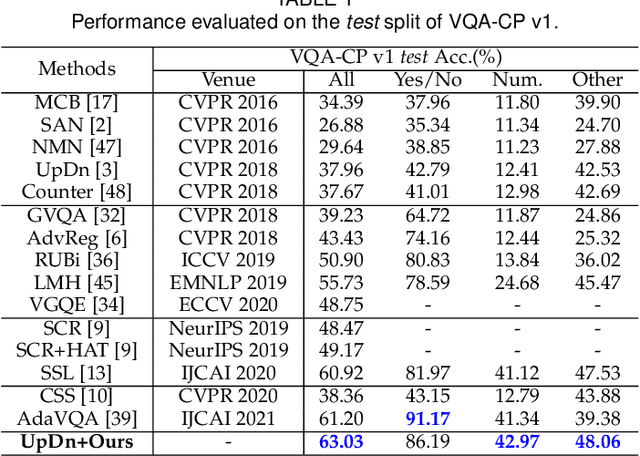
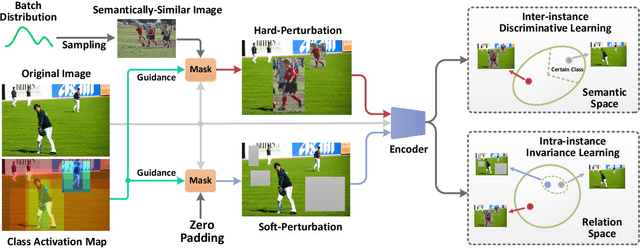
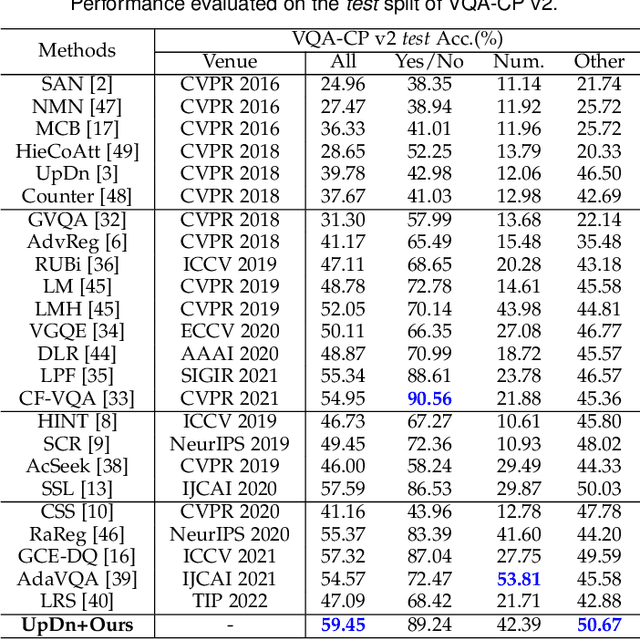
Several studies have recently pointed that existing Visual Question Answering (VQA) models heavily suffer from the language prior problem, which refers to capturing superficial statistical correlations between the question type and the answer whereas ignoring the image contents. Numerous efforts have been dedicated to strengthen the image dependency by creating the delicate models or introducing the extra visual annotations. However, these methods cannot sufficiently explore how the visual cues explicitly affect the learned answer representation, which is vital for language reliance alleviation. Moreover, they generally emphasize the class-level discrimination of the learned answer representation, which overlooks the more fine-grained instance-level patterns and demands further optimization. In this paper, we propose a novel collaborative learning scheme from the viewpoint of visual perturbation calibration, which can better investigate the fine-grained visual effects and mitigate the language prior problem by learning the instance-level characteristics. Specifically, we devise a visual controller to construct two sorts of curated images with different perturbation extents, based on which the collaborative learning of intra-instance invariance and inter-instance discrimination is implemented by two well-designed discriminators. Besides, we implement the information bottleneck modulator on latent space for further bias alleviation and representation calibration. We impose our visual perturbation-aware framework to three orthodox baselines and the experimental results on two diagnostic VQA-CP benchmark datasets evidently demonstrate its effectiveness. In addition, we also justify its robustness on the balanced VQA benchmark.
Semantic-aware Modular Capsule Routing for Visual Question Answering
Jul 21, 2022



Visual Question Answering (VQA) is fundamentally compositional in nature, and many questions are simply answered by decomposing them into modular sub-problems. The recent proposed Neural Module Network (NMN) employ this strategy to question answering, whereas heavily rest with off-the-shelf layout parser or additional expert policy regarding the network architecture design instead of learning from the data. These strategies result in the unsatisfactory adaptability to the semantically-complicated variance of the inputs, thereby hindering the representational capacity and generalizability of the model. To tackle this problem, we propose a Semantic-aware modUlar caPsulE Routing framework, termed as SUPER, to better capture the instance-specific vision-semantic characteristics and refine the discriminative representations for prediction. Particularly, five powerful specialized modules as well as dynamic routers are tailored in each layer of the SUPER network, and the compact routing spaces are constructed such that a variety of customizable routes can be sufficiently exploited and the vision-semantic representations can be explicitly calibrated. We comparatively justify the effectiveness and generalization ability of our proposed SUPER scheme over five benchmark datasets, as well as the parametric-efficient advantage. It is worth emphasizing that this work is not to pursue the state-of-the-art results in VQA. Instead, we expect that our model is responsible to provide a novel perspective towards architecture learning and representation calibration for VQA.
Polarized deep diffractive neural network for classification, generation, multiplexing and de-multiplexing of orbital angular momentum modes
Mar 30, 2022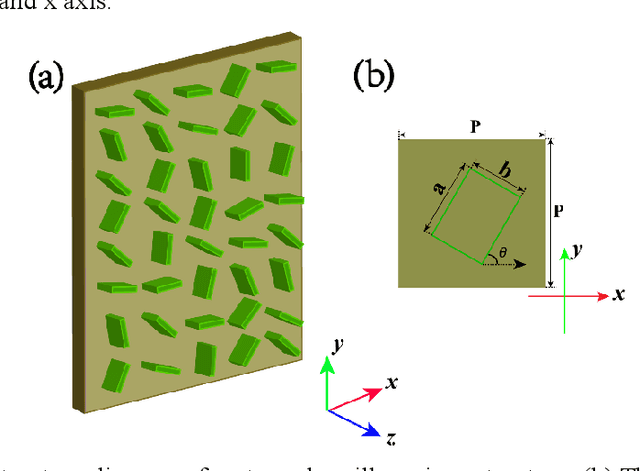
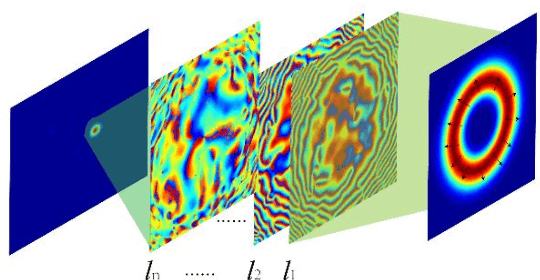
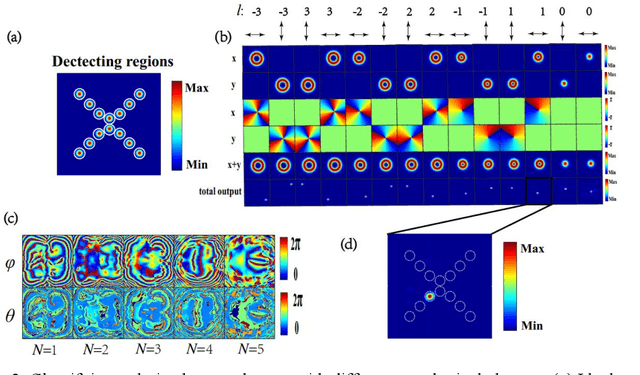
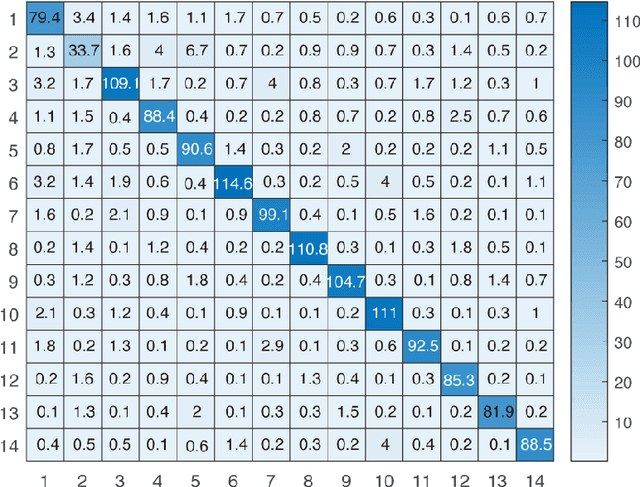
The multiplexing and de-multiplexing of orbital angular momentum (OAM) beams are critical issues in optical communication. Optical diffractive neural networks have been introduced to perform classification, generation, multiplexing and de-multiplexing of OAM beams. However, conventional diffractive neural networks cannot handle OAM modes with a varying spatial distribution of polarization directions. Herein, we propose a polarized optical deep diffractive neural network that is designed based on the concept of rectangular micro-structure meta-material. Our proposed polarized optical diffractive neural network is trained to classify, generate, multiplex and de-multiplex polarized OAM beams.The simulation results show that our network framework can successfully classify 14 kinds of orthogonally polarized vortex beams and de-multiplex the hybrid OAM beams into Gauss beams at two, three and four spatial positions respectively. 6 polarized OAM beams with identical total intensity and 8 cylinder vector beams with different topology charges also have been classified effectively. Additionally, results reveal that the network can generate hybrid OAM beams with high quality and multiplex two polarized linear beams into 8 kinds of cylinder vector beams.
Review Polarity-wise Recommender
Jun 08, 2021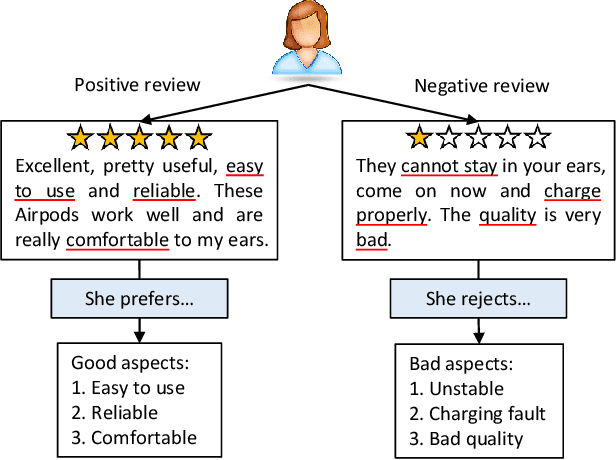
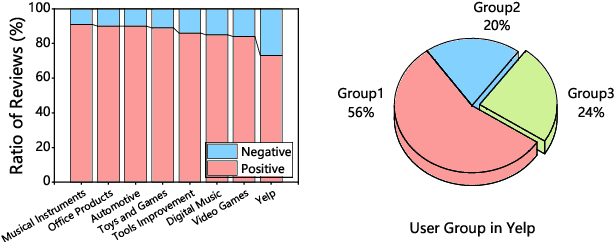
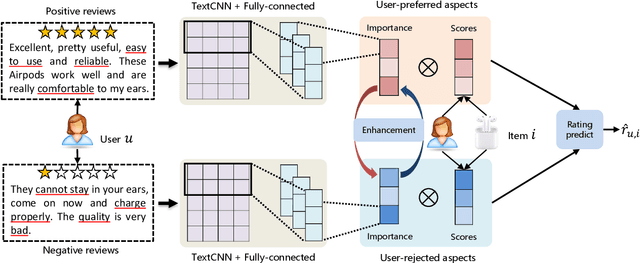
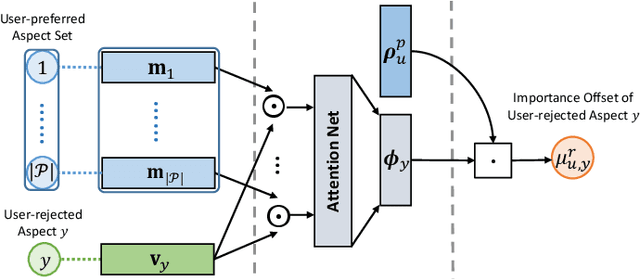
Utilizing review information to enhance recommendation, the de facto review-involved recommender systems, have received increasing interests over the past few years. Thereinto, one advanced branch is to extract salient aspects from textual reviews (i.e., the item attributes that users express) and combine them with the matrix factorization technique. However, existing approaches all ignore the fact that semantically different reviews often include opposite aspect information. In particular, positive reviews usually express aspects that users prefer, while negative ones describe aspects that users reject. As a result, it may mislead the recommender systems into making incorrect decisions pertaining to user preference modeling. Towards this end, in this paper, we propose a Review Polarity-wise Recommender model, dubbed as RPR, to discriminately treat reviews with different polarities. To be specific, in this model, positive and negative reviews are separately gathered and utilized to model the user-preferred and user-rejected aspects, respectively. Besides, in order to overcome the imbalance problem of semantically different reviews, we also develop an aspect-aware importance weighting approach to align the aspect importance for these two kinds of reviews. Extensive experiments conducted on eight benchmark datasets have demonstrated the superiority of our model as compared to a series of state-of-the-art review-involved baselines. Moreover, our method can provide certain explanations to the real-world rating prediction scenarios.
Answer Questions with Right Image Regions: A Visual Attention Regularization Approach
Feb 03, 2021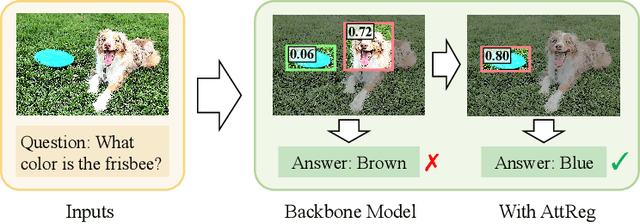
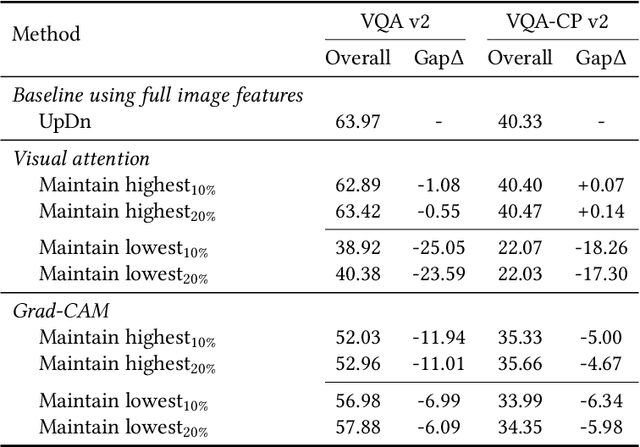
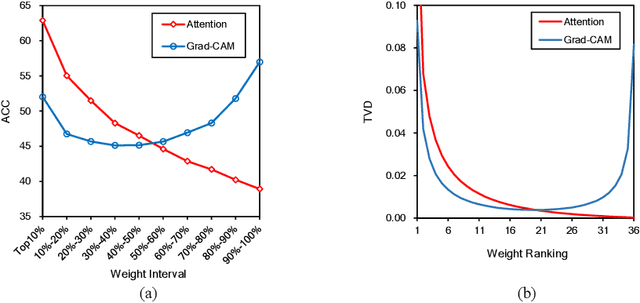
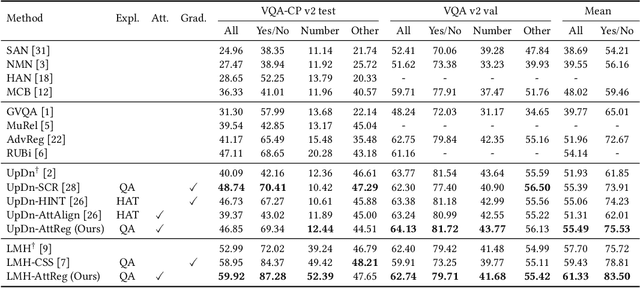
Visual attention in Visual Question Answering (VQA) targets at locating the right image regions regarding the answer prediction. However, recent studies have pointed out that the highlighted image regions from the visual attention are often irrelevant to the given question and answer, leading to model confusion for correct visual reasoning. To tackle this problem, existing methods mostly resort to aligning the visual attention weights with human attentions. Nevertheless, gathering such human data is laborious and expensive, making it burdensome to adapt well-developed models across datasets. To address this issue, in this paper, we devise a novel visual attention regularization approach, namely AttReg, for better visual grounding in VQA. Specifically, AttReg firstly identifies the image regions which are essential for question answering yet unexpectedly ignored (i.e., assigned with low attention weights) by the backbone model. And then a mask-guided learning scheme is leveraged to regularize the visual attention to focus more on these ignored key regions. The proposed method is very flexible and model-agnostic, which can be integrated into most visual attention-based VQA models and require no human attention supervision. Extensive experiments over three benchmark datasets, i.e., VQA-CP v2, VQA-CP v1, and VQA v2, have been conducted to evaluate the effectiveness of AttReg. As a by-product, when incorporating AttReg into the strong baseline LMH, our approach can achieve a new state-of-the-art accuracy of 59.92% with an absolute performance gain of 6.93% on the VQA-CP v2 benchmark dataset. In addition to the effectiveness validation, we recognize that the faithfulness of the visual attention in VQA has not been well explored in literature. In the light of this, we propose to empirically validate such property of visual attention and compare it with the prevalent gradient-based approaches.