 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Perturbation-aware Collaborative Learning for Overcoming the Language Prior Problem
Paper and Code
Jul 24, 2022
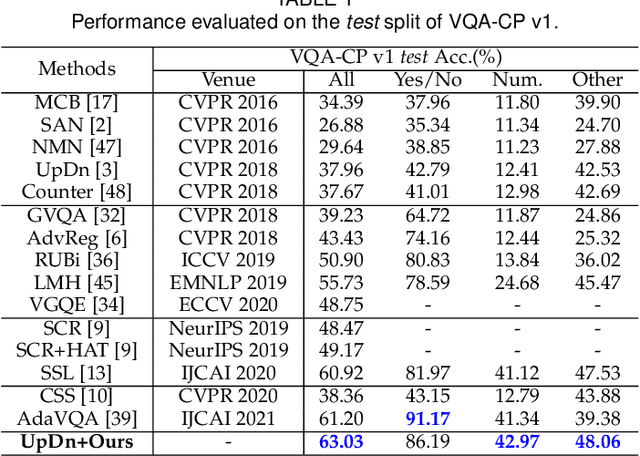
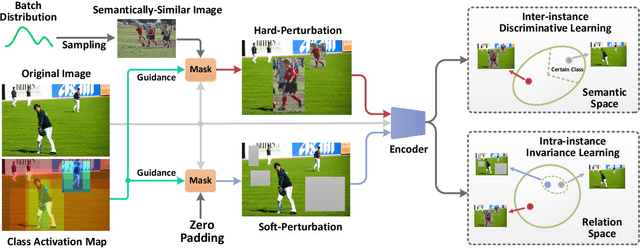
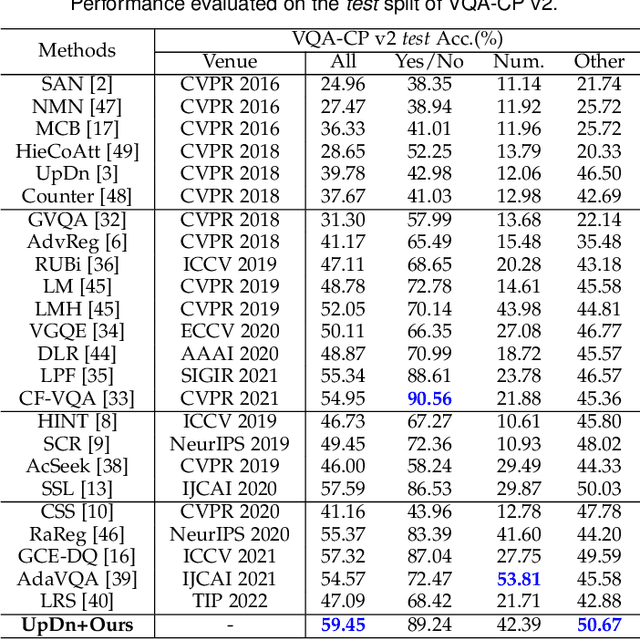
Several studies have recently pointed that existing Visual Question Answering (VQA) models heavily suffer from the language prior problem, which refers to capturing superficial statistical correlations between the question type and the answer whereas ignoring the image contents. Numerous efforts have been dedicated to strengthen the image dependency by creating the delicate models or introducing the extra visual annotations. However, these methods cannot sufficiently explore how the visual cues explicitly affect the learned answer representation, which is vital for language reliance alleviation. Moreover, they generally emphasize the class-level discrimination of the learned answer representation, which overlooks the more fine-grained instance-level patterns and demands further optimization. In this paper, we propose a novel collaborative learning scheme from the viewpoint of visual perturbation calibration, which can better investigate the fine-grained visual effects and mitigate the language prior problem by learning the instance-level characteristics. Specifically, we devise a visual controller to construct two sorts of curated images with different perturbation extents, based on which the collaborative learning of intra-instance invariance and inter-instance discrimination is implemented by two well-designed discriminators. Besides, we implement the information bottleneck modulator on latent space for further bias alleviation and representation calibration. We impose our visual perturbation-aware framework to three orthodox baselines and the experimental results on two diagnostic VQA-CP benchmark datasets evidently demonstrate its effectiveness. In addition, we also justify its robustness on the balanced VQA benchmark.