 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStateful Cross-layer Vision Modulation
Feb 28, 2026Recent multimodal large language models (MLLMs) widely adopt multi-layer visual feature fusion to enhance visual representation. However, existing approaches typically perform static concatenation or weighted aggregation after visual encoding, without intervening in the representation formation process itself. As a result, fine-grained details from early layers may be progressively suppressed during hierarchical abstraction. Moreover, directly introducing shallow-layer features into the language model often leads to semantic distribution mismatch with the visual feature space that the LLM's cross-attention layers were pretrained on, which typically requires additional adaptation or fine-tuning of the LLM. To address these limitations, we revisit visual representation learning from the perspective of representation evolution control and propose a cross-layer memory-modulated vision framework(SCVM). Specifically, we introduce a recursively updated cross-layer memory state inside the vision encoder to model long-range inter-layer dependencies. We further design a layer-wise feedback modulation mechanism that refreshes token representations at each layer based on the accumulated memory, thereby structurally regulating the representation evolution trajectory. In addition, we incorporate an auxiliary semantic alignment objective that explicitly supervises the final memory state, encouraging progressive compression and reinforcement of task-relevant information. Experimental results on multiple visual question answering and hallucination evaluation benchmarks demonstrate that SCVM achieves consistent performance improvements without expanding visual tokens, introducing additional vision encoders, or modifying or fine-tuning the language model.
WebSplatter: Enabling Cross-Device Efficient Gaussian Splatting in Web Browsers via WebGPU
Feb 03, 2026We present WebSplatter, an end-to-end GPU rendering pipeline for the heterogeneous web ecosystem. Unlike naive ports, WebSplatter introduces a wait-free hierarchical radix sort that circumvents the lack of global atomics in WebGPU, ensuring deterministic execution across diverse hardware. Furthermore, we propose an opacity-aware geometry culling stage that dynamically prunes splats before rasterization, significantly reducing overdraw and peak memory footprint. Evaluation demonstrates that WebSplatter consistently achieves 1.2$\times$ to 4.5$\times$ speedups over state-of-the-art web viewers.
Content-aware Balanced Spectrum Encoding in Masked Modeling for Time Series Classification
Dec 17, 2024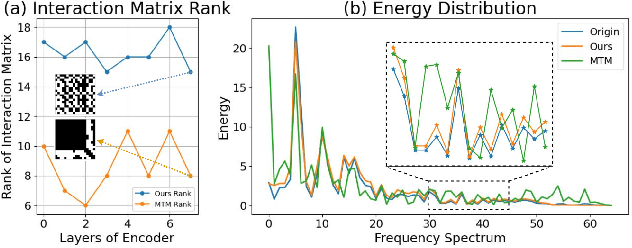
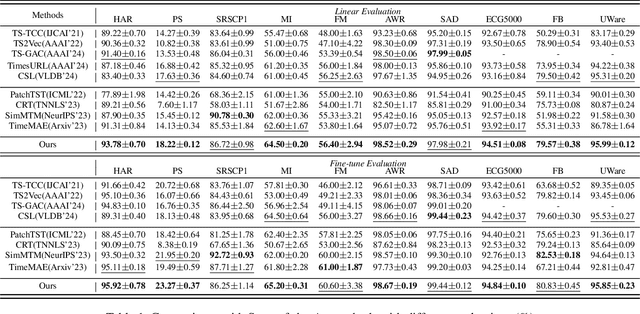
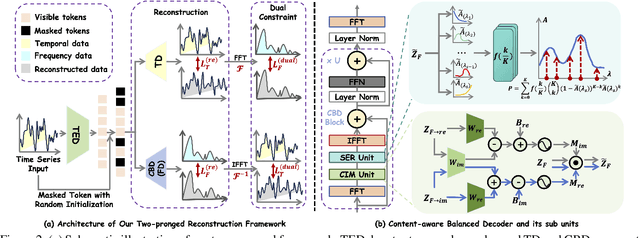
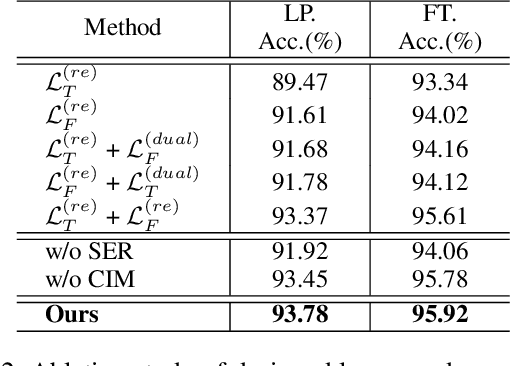
Due to the superior ability of global dependency, transformer and its variants have become the primary choice in Masked Time-series Modeling (MTM) towards time-series classification task. In this paper, we experimentally analyze that existing transformer-based MTM methods encounter with two under-explored issues when dealing with time series data: (1) they encode features by performing long-dependency ensemble averaging, which easily results in rank collapse and feature homogenization as the layer goes deeper; (2) they exhibit distinct priorities in fitting different frequency components contained in the time-series, inevitably leading to spectrum energy imbalance of encoded feature. To tackle these issues, we propose an auxiliary content-aware balanced decoder (CBD) to optimize the encoding quality in the spectrum space within masked modeling scheme. Specifically, the CBD iterates on a series of fundamental blocks, and thanks to two tailored units, each block could progressively refine the masked representation via adjusting the interaction pattern based on local content variations of time-series and learning to recalibrate the energy distribution across different frequency components. Moreover, a dual-constraint loss is devised to enhance the mutual optimization of vanilla decoder and our CBD. Extensive experimental results on ten time-series classification datasets show that our method nearly surpasses a bunch of baselines. Meanwhile, a series of explanatory results are showcased to sufficiently demystify the behaviors of our method.
DynFocus: Dynamic Cooperative Network Empowers LLMs with Video Understanding
Nov 19, 2024The challenge in LLM-based video understanding lies in preserving visual and semantic information in long videos while maintaining a memory-affordable token count. However, redundancy and correspondence in videos have hindered the performance potential of existing methods. Through statistical learning on current datasets, we observe that redundancy occurs in both repeated and answer-irrelevant frames, and the corresponding frames vary with different questions. This suggests the possibility of adopting dynamic encoding to balance detailed video information preservation with token budget reduction. To this end, we propose a dynamic cooperative network, DynFocus, for memory-efficient video encoding in this paper. Specifically, i) a Dynamic Event Prototype Estimation (DPE) module to dynamically select meaningful frames for question answering; (ii) a Compact Cooperative Encoding (CCE) module that encodes meaningful frames with detailed visual appearance and the remaining frames with sketchy perception separately. We evaluate our method on five publicly available benchmarks, and experimental results consistently demonstrate that our method achieves competitive performance.
LLM-Powered Test Case Generation for Detecting Tricky Bugs
Apr 16, 2024
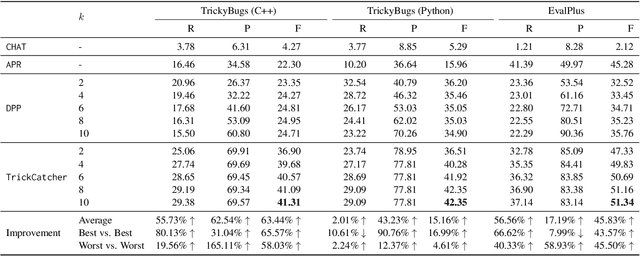

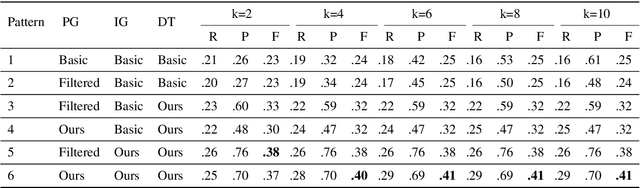
Conventional automated test generation tools struggle to generate test oracles and tricky bug-revealing test inputs. Large Language Models (LLMs) can be prompted to produce test inputs and oracles for a program directly, but the precision of the tests can be very low for complex scenarios (only 6.3% based on our experiments). To fill this gap, this paper proposes AID, which combines LLMs with differential testing to generate fault-revealing test inputs and oracles targeting plausibly correct programs (i.e., programs that have passed all the existing tests). In particular, AID selects test inputs that yield diverse outputs on a set of program variants generated by LLMs, then constructs the test oracle based on the outputs. We evaluate AID on two large-scale datasets with tricky bugs: TrickyBugs and EvalPlus, and compare it with three state-of-the-art baselines. The evaluation results show that the recall, precision, and F1 score of AID outperform the state-of-the-art by up to 1.80x, 2.65x, and 1.66x, respectively.
DeFL: Decentralized Weight Aggregation for Cross-silo Federated Learning
Aug 01, 2022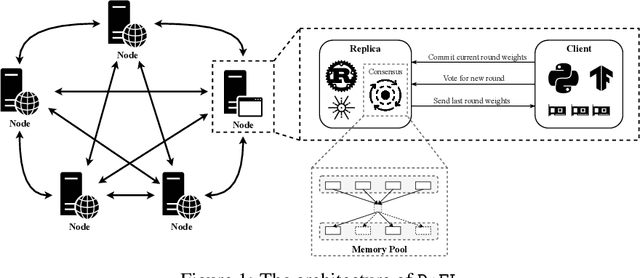
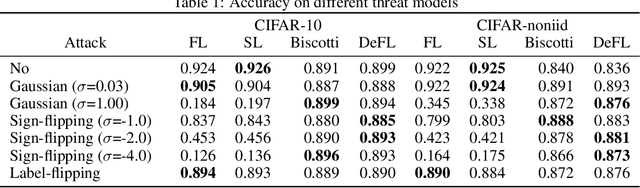
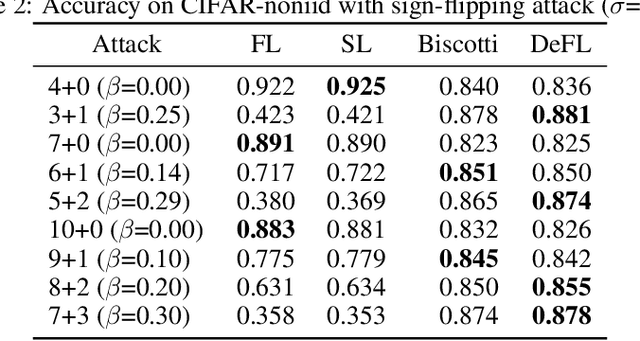
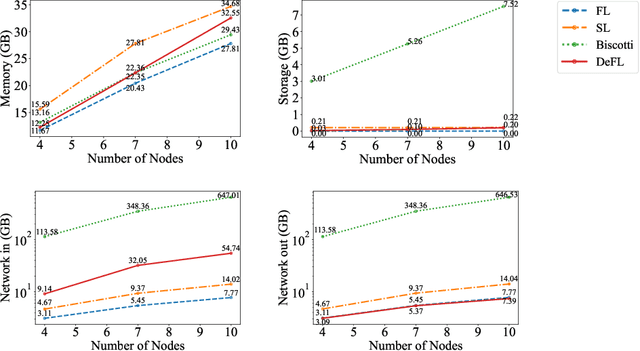
Federated learning (FL) is an emerging promising paradigm of privacy-preserving machine learning (ML). An important type of FL is cross-silo FL, which enables a small scale of organizations to cooperatively train a shared model by keeping confidential data locally and aggregating weights on a central parameter server. However, the central server may be vulnerable to malicious attacks or software failures in practice. To address this issue, in this paper, we propose DeFL, a novel decentralized weight aggregation framework for cross-silo FL. DeFL eliminates the central server by aggregating weights on each participating node and weights of only the current training round are maintained and synchronized among all nodes. We use Multi-Krum to enable aggregating correct weights from honest nodes and use HotStuff to ensure the consistency of the training round number and weights among all nodes. Besides, we theoretically analyze the Byzantine fault tolerance, convergence, and complexity of DeFL. We conduct extensive experiments over two widely-adopted public datasets, i.e. CIFAR-10 and Sentiment140, to evaluate the performance of DeFL. Results show that DeFL defends against common threat models with minimal accuracy loss, and achieves up to 100x reduction in storage overhead and up to 12x reduction in network overhead, compared to state-of-the-art decentralized FL approaches.
Visual Perturbation-aware Collaborative Learning for Overcoming the Language Prior Problem
Jul 24, 2022
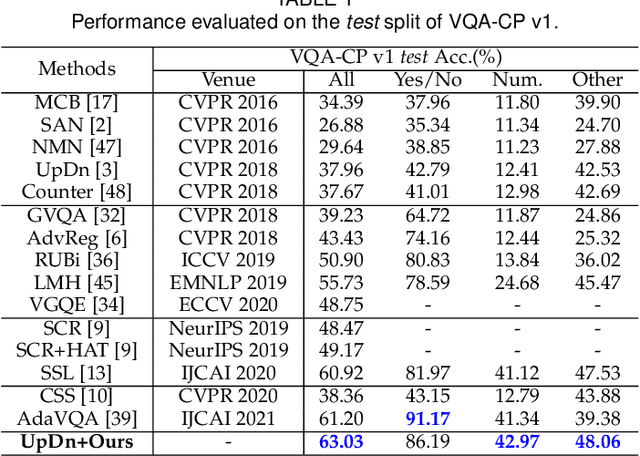
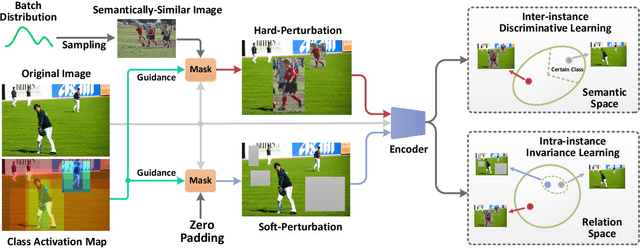
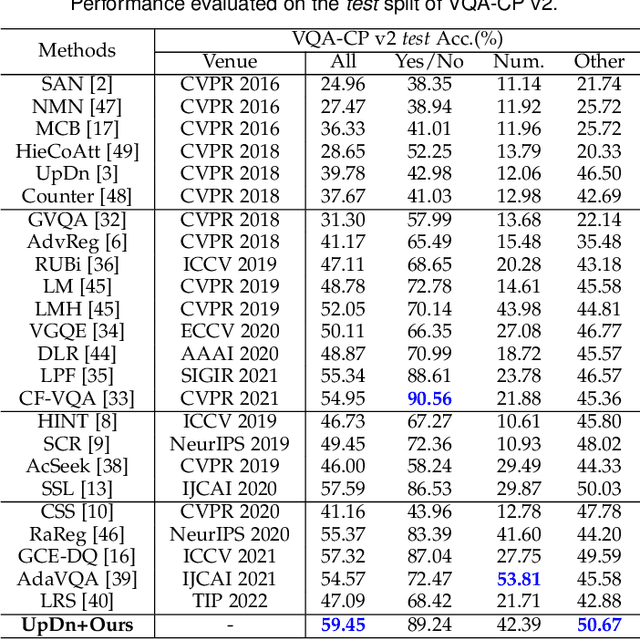
Several studies have recently pointed that existing Visual Question Answering (VQA) models heavily suffer from the language prior problem, which refers to capturing superficial statistical correlations between the question type and the answer whereas ignoring the image contents. Numerous efforts have been dedicated to strengthen the image dependency by creating the delicate models or introducing the extra visual annotations. However, these methods cannot sufficiently explore how the visual cues explicitly affect the learned answer representation, which is vital for language reliance alleviation. Moreover, they generally emphasize the class-level discrimination of the learned answer representation, which overlooks the more fine-grained instance-level patterns and demands further optimization. In this paper, we propose a novel collaborative learning scheme from the viewpoint of visual perturbation calibration, which can better investigate the fine-grained visual effects and mitigate the language prior problem by learning the instance-level characteristics. Specifically, we devise a visual controller to construct two sorts of curated images with different perturbation extents, based on which the collaborative learning of intra-instance invariance and inter-instance discrimination is implemented by two well-designed discriminators. Besides, we implement the information bottleneck modulator on latent space for further bias alleviation and representation calibration. We impose our visual perturbation-aware framework to three orthodox baselines and the experimental results on two diagnostic VQA-CP benchmark datasets evidently demonstrate its effectiveness. In addition, we also justify its robustness on the balanced VQA benchmark.
Semantic-aware Modular Capsule Routing for Visual Question Answering
Jul 21, 2022



Visual Question Answering (VQA) is fundamentally compositional in nature, and many questions are simply answered by decomposing them into modular sub-problems. The recent proposed Neural Module Network (NMN) employ this strategy to question answering, whereas heavily rest with off-the-shelf layout parser or additional expert policy regarding the network architecture design instead of learning from the data. These strategies result in the unsatisfactory adaptability to the semantically-complicated variance of the inputs, thereby hindering the representational capacity and generalizability of the model. To tackle this problem, we propose a Semantic-aware modUlar caPsulE Routing framework, termed as SUPER, to better capture the instance-specific vision-semantic characteristics and refine the discriminative representations for prediction. Particularly, five powerful specialized modules as well as dynamic routers are tailored in each layer of the SUPER network, and the compact routing spaces are constructed such that a variety of customizable routes can be sufficiently exploited and the vision-semantic representations can be explicitly calibrated. We comparatively justify the effectiveness and generalization ability of our proposed SUPER scheme over five benchmark datasets, as well as the parametric-efficient advantage. It is worth emphasizing that this work is not to pursue the state-of-the-art results in VQA. Instead, we expect that our model is responsible to provide a novel perspective towards architecture learning and representation calibration for VQA.
Demystifying Swarm Learning: A New Paradigm of Blockchain-based Decentralized Federated Learning
Jan 17, 2022
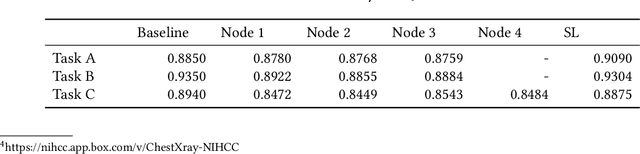


Federated learning (FL) is an emerging promising privacy-preserving machine learning paradigm and has raised more and more attention from researchers and developers. FL keeps users' private data on devices and exchanges the gradients of local models to cooperatively train a shared Deep Learning (DL) model on central custodians. However, the security and fault tolerance of FL have been increasingly discussed, because its central custodian mechanism or star-shaped architecture can be vulnerable to malicious attacks or software failures. To address these problems, Swarm Learning (SL) introduces a permissioned blockchain to securely onboard members and dynamically elect the leader, which allows performing DL in an extremely decentralized manner. Compared with tremendous attention to SL, there are few empirical studies on SL or blockchain-based decentralized FL, which provide comprehensive knowledge of best practices and precautions of deploying SL in real-world scenarios. Therefore, we conduct the first comprehensive study of SL to date, to fill the knowledge gap between SL deployment and developers, as far as we are concerned. In this paper, we conduct various experiments on 3 public datasets of 5 research questions, present interesting findings, quantitatively analyze the reasons behind these findings, and provide developers and researchers with practical suggestions. The findings have evidenced that SL is supposed to be suitable for most application scenarios, no matter whether the dataset is balanced, polluted, or biased over irrelevant features.
Discrete Optimal Graph Clustering
Apr 25, 2019
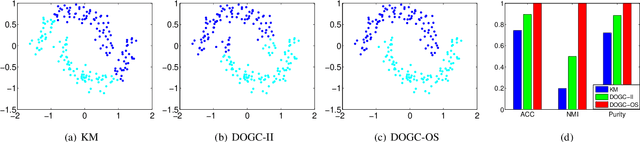


Graph based clustering is one of the major clustering methods. Most of it work in three separate steps: similarity graph construction, clustering label relaxing and label discretization with k-means. Such common practice has three disadvantages: 1) the predefined similarity graph is often fixed and may not be optimal for the subsequent clustering. 2) the relaxing process of cluster labels may cause significant information loss. 3) label discretization may deviate from the real clustering result since k-means is sensitive to the initialization of cluster centroids. To tackle these problems, in this paper, we propose an effective discrete optimal graph clustering (DOGC) framework. A structured similarity graph that is theoretically optimal for clustering performance is adaptively learned with a guidance of reasonable rank constraint. Besides, to avoid the information loss, we explicitly enforce a discrete transformation on the intermediate continuous label, which derives a tractable optimization problem with discrete solution. Further, to compensate the unreliability of the learned labels and enhance the clustering accuracy, we design an adaptive robust module that learns prediction function for the unseen data based on the learned discrete cluster labels. Finally, an iterative optimization strategy guaranteed with convergence is developed to directly solve the clustering results. Extensive experiments conducted on both real and synthetic datasets demonstrate the superiority of our proposed methods compared with several state-of-the-art clustering approaches.