 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Knowledge-Rich Sequential Model for Planar Homography Estimation in Aerial Video
Apr 05, 2023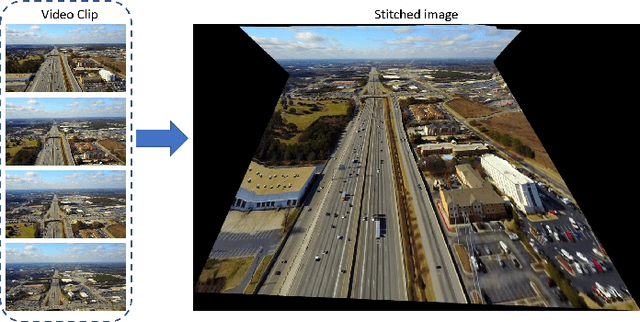
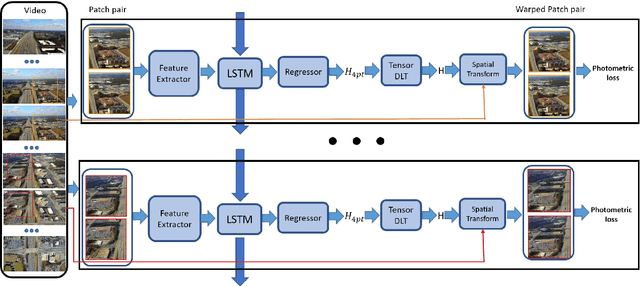

This paper presents an unsupervised approach that leverages raw aerial videos to learn to estimate planar homographic transformation between consecutive video frames. Previous learning-based estimators work on pairs of images to estimate their planar homographic transformations but suffer from severe over-fitting issues, especially when applying over aerial videos. To address this concern, we develop a sequential estimator that directly processes a sequence of video frames and estimates their pairwise planar homographic transformations in batches. We also incorporate a set of spatial-temporal knowledge to regularize the learning of such a sequence-to-sequence model. We collect a set of challenging aerial videos and compare the proposed method to the alternative algorithms. Empirical studies suggest that our sequential model achieves significant improvement over alternative image-based methods and the knowledge-rich regularization further boosts our system performance. Our codes and dataset could be found at https://github.com/Paul-LiPu/DeepVideoHomography
Learning Stage-wise GANs for Whistle Extraction in Time-Frequency Spectrograms
Apr 05, 2023



Whistle contour extraction aims to derive animal whistles from time-frequency spectrograms as polylines. For toothed whales, whistle extraction results can serve as the basis for analyzing animal abundance, species identity, and social activities. During the last few decades, as long-term recording systems have become affordable, automated whistle extraction algorithms were proposed to process large volumes of recording data. Recently, a deep learning-based method demonstrated superior performance in extracting whistles under varying noise conditions. However, training such networks requires a large amount of labor-intensive annotation, which is not available for many species. To overcome this limitation, we present a framework of stage-wise generative adversarial networks (GANs), which compile new whistle data suitable for deep model training via three stages: generation of background noise in the spectrogram, generation of whistle contours, and generation of whistle signals. By separating the generation of different components in the samples, our framework composes visually promising whistle data and labels even when few expert annotated data are available. Regardless of the amount of human-annotated data, the proposed data augmentation framework leads to a consistent improvement in performance of the whistle extraction model, with a maximum increase of 1.69 in the whistle extraction mean F1-score. Our stage-wise GAN also surpasses one single GAN in improving whistle extraction models with augmented data. The data and code will be available at https://github.com/Paul-LiPu/CompositeGAN\_WhistleAugment.
A Hamiltonian Monte Carlo Method for Probabilistic Adversarial Attack and Learning
Oct 15, 2020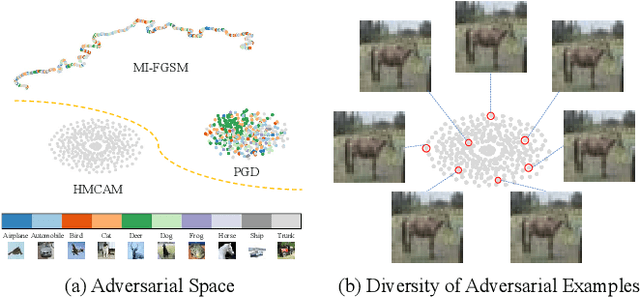

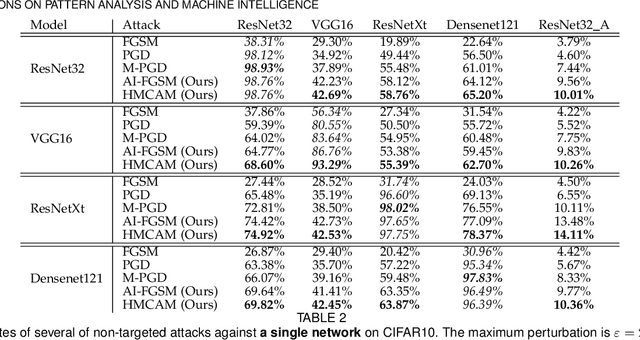
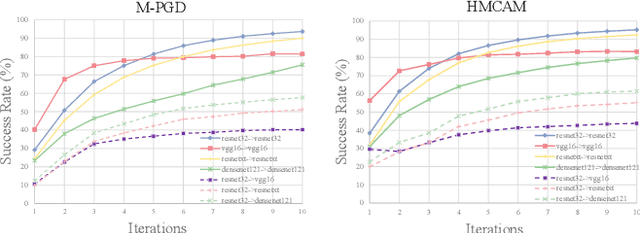
Although deep convolutional neural networks (CNNs) have demonstrated remarkable performance on multiple computer vision tasks, researches on adversarial learning have shown that deep models are vulnerable to adversarial examples, which are crafted by adding visually imperceptible perturbations to the input images. Most of the existing adversarial attack methods only create a single adversarial example for the input, which just gives a glimpse of the underlying data manifold of adversarial examples. An attractive solution is to explore the solution space of the adversarial examples and generate a diverse bunch of them, which could potentially improve the robustness of real-world systems and help prevent severe security threats and vulnerabilities. In this paper, we present an effective method, called Hamiltonian Monte Carlo with Accumulated Momentum (HMCAM), aiming to generate a sequence of adversarial examples. To improve the efficiency of HMC, we propose a new regime to automatically control the length of trajectories, which allows the algorithm to move with adaptive step sizes along the search direction at different positions. Moreover, we revisit the reason for high computational cost of adversarial training under the view of MCMC and design a new generative method called Contrastive Adversarial Training (CAT), which approaches equilibrium distribution of adversarial examples with only few iterations by building from small modifications of the standard Contrastive Divergence (CD) and achieve a trade-off between efficiency and accuracy. Both quantitative and qualitative analysis on several natural image datasets and practical systems have confirmed the superiority of the proposed algorithm.
Discrete Optimal Graph Clustering
Apr 25, 2019
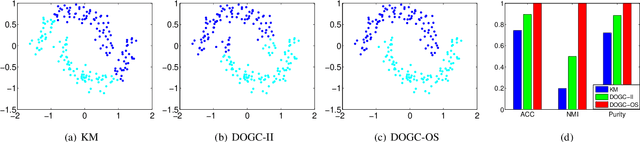


Graph based clustering is one of the major clustering methods. Most of it work in three separate steps: similarity graph construction, clustering label relaxing and label discretization with k-means. Such common practice has three disadvantages: 1) the predefined similarity graph is often fixed and may not be optimal for the subsequent clustering. 2) the relaxing process of cluster labels may cause significant information loss. 3) label discretization may deviate from the real clustering result since k-means is sensitive to the initialization of cluster centroids. To tackle these problems, in this paper, we propose an effective discrete optimal graph clustering (DOGC) framework. A structured similarity graph that is theoretically optimal for clustering performance is adaptively learned with a guidance of reasonable rank constraint. Besides, to avoid the information loss, we explicitly enforce a discrete transformation on the intermediate continuous label, which derives a tractable optimization problem with discrete solution. Further, to compensate the unreliability of the learned labels and enhance the clustering accuracy, we design an adaptive robust module that learns prediction function for the unseen data based on the learned discrete cluster labels. Finally, an iterative optimization strategy guaranteed with convergence is developed to directly solve the clustering results. Extensive experiments conducted on both real and synthetic datasets demonstrate the superiority of our proposed methods compared with several state-of-the-art clustering approaches.
Neural Task Planning with And-Or Graph Representations
Aug 25, 2018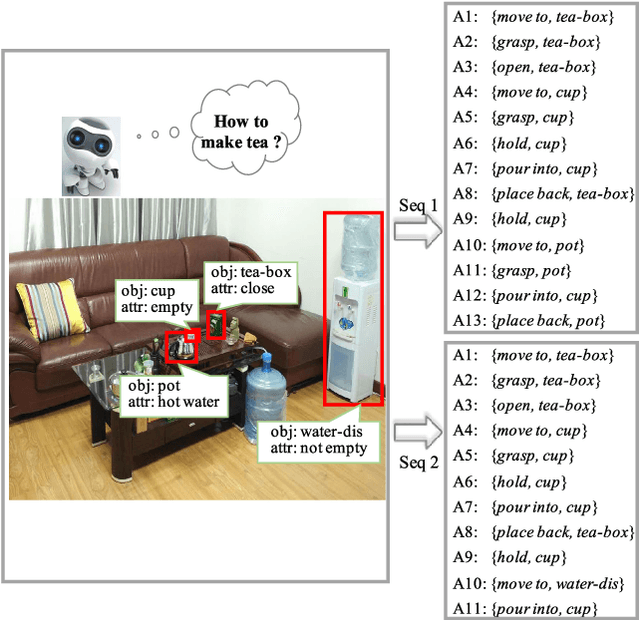
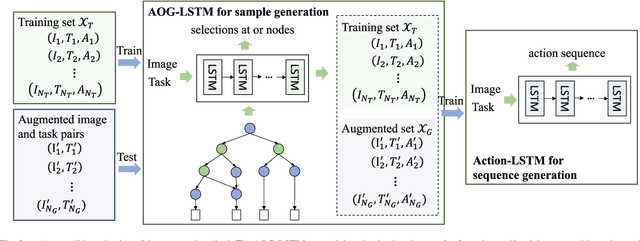
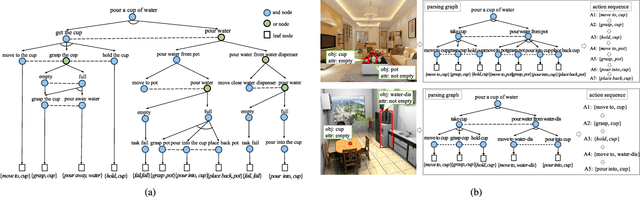
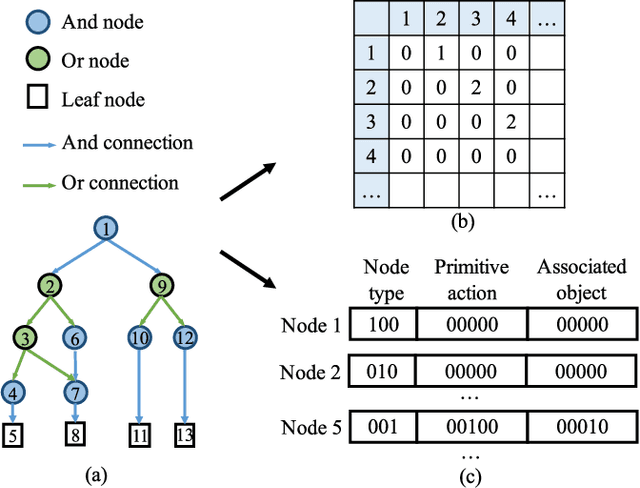
This paper focuses on semantic task planning, i.e., predicting a sequence of actions toward accomplishing a specific task under a certain scene, which is a new problem in computer vision research. The primary challenges are how to model task-specific knowledge and how to integrate this knowledge into the learning procedure. In this work, we propose training a recurrent long short-term memory (LSTM) network to address this problem, i.e., taking a scene image (including pre-located objects) and the specified task as input and recurrently predicting action sequences. However, training such a network generally requires large numbers of annotated samples to cover the semantic space (e.g., diverse action decomposition and ordering). To overcome this issue, we introduce a knowledge and-or graph (AOG) for task description, which hierarchically represents a task as atomic actions. With this AOG representation, we can produce many valid samples (i.e., action sequences according to common sense) by training another auxiliary LSTM network with a small set of annotated samples. Furthermore, these generated samples (i.e., task-oriented action sequences) effectively facilitate training of the model for semantic task planning. In our experiments, we create a new dataset that contains diverse daily tasks and extensively evaluate the effectiveness of our approach.
A Causal And-Or Graph Model for Visibility Fluent Reasoning in Tracking Interacting Objects
Mar 29, 2018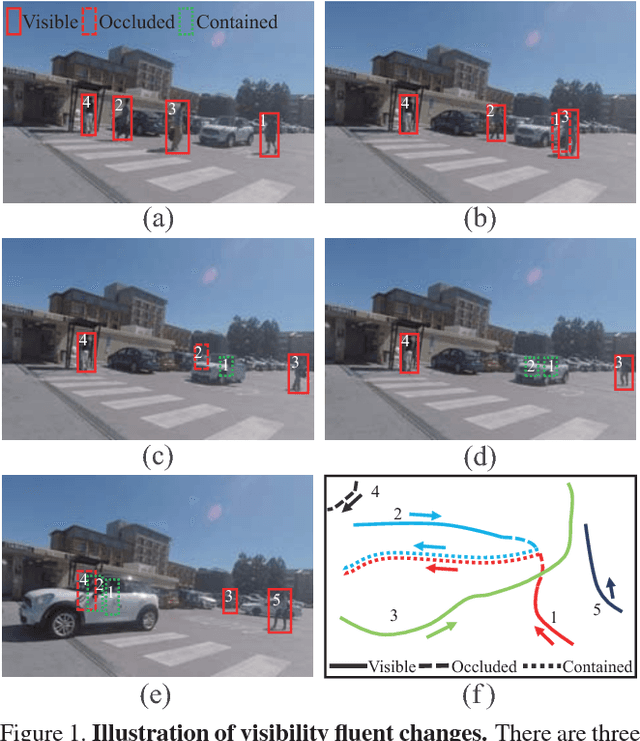
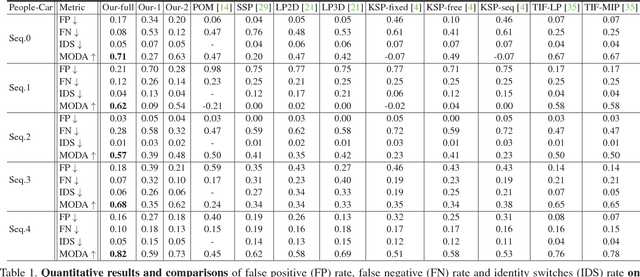
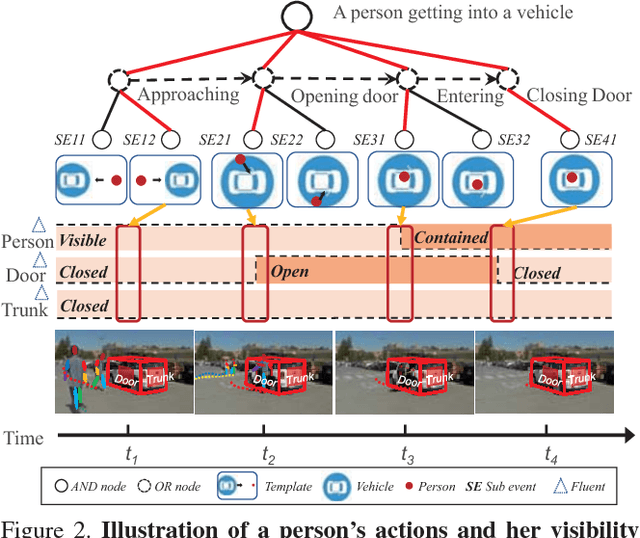
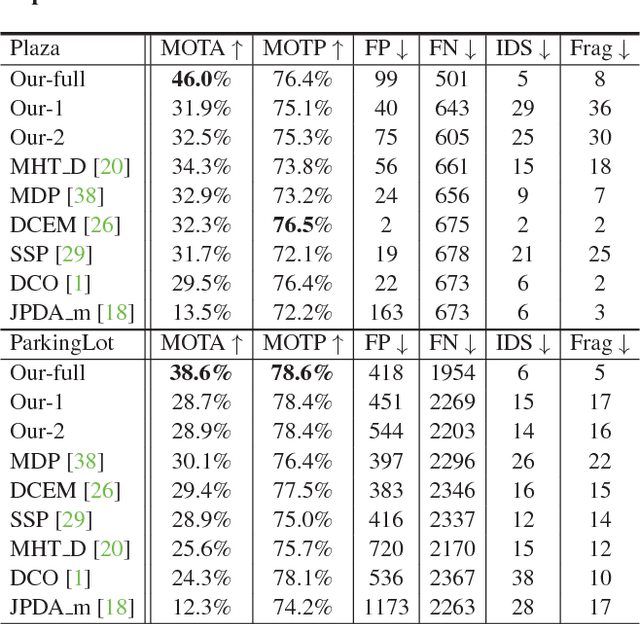
Tracking humans that are interacting with the other subjects or environment remains unsolved in visual tracking, because the visibility of the human of interests in videos is unknown and might vary over time. In particular, it is still difficult for state-of-the-art human trackers to recover complete human trajectories in crowded scenes with frequent human interactions. In this work, we consider the visibility status of a subject as a fluent variable, whose change is mostly attributed to the subject's interaction with the surrounding, e.g., crossing behind another object, entering a building, or getting into a vehicle, etc. We introduce a Causal And-Or Graph (C-AOG) to represent the causal-effect relations between an object's visibility fluent and its activities, and develop a probabilistic graph model to jointly reason the visibility fluent change (e.g., from visible to invisible) and track humans in videos. We formulate this joint task as an iterative search of a feasible causal graph structure that enables fast search algorithm, e.g., dynamic programming method. We apply the proposed method on challenging video sequences to evaluate its capabilities of estimating visibility fluent changes of subjects and tracking subjects of interests over time. Results with comparisons demonstrate that our method outperforms the alternative trackers and can recover complete trajectories of humans in complicated scenarios with frequent human interactions.
Learning Pose Grammar to Encode Human Body Configuration for 3D Pose Estimation
Jan 04, 2018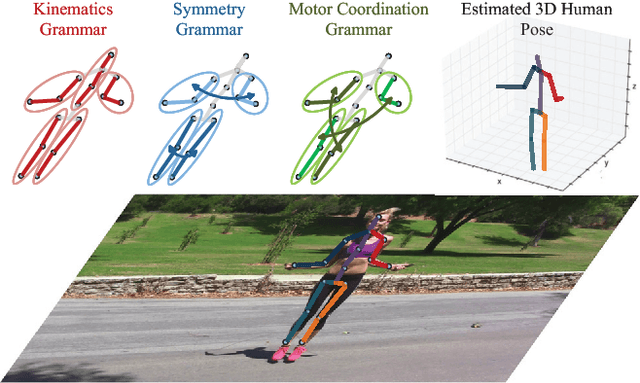
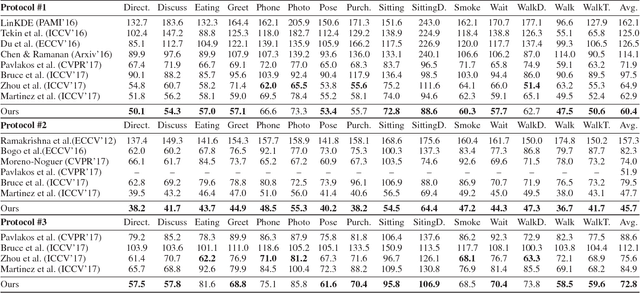
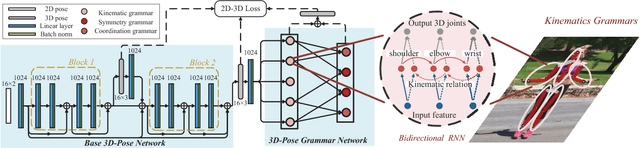
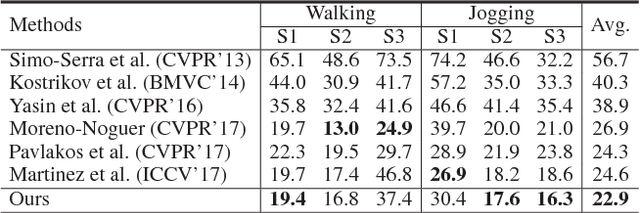
In this paper, we propose a pose grammar to tackle the problem of 3D human pose estimation. Our model directly takes 2D pose as input and learns a generalized 2D-3D mapping function. The proposed model consists of a base network which efficiently captures pose-aligned features and a hierarchy of Bi-directional RNNs (BRNN) on the top to explicitly incorporate a set of knowledge regarding human body configuration (i.e., kinematics, symmetry, motor coordination). The proposed model thus enforces high-level constraints over human poses. In learning, we develop a pose sample simulator to augment training samples in virtual camera views, which further improves our model generalizability. We validate our method on public 3D human pose benchmarks and propose a new evaluation protocol working on cross-view setting to verify the generalization capability of different methods. We empirically observe that most state-of-the-art methods encounter difficulty under such setting while our method can well handle such challenges.
Discrete Multi-modal Hashing with Canonical Views for Robust Mobile Landmark Search
Jul 13, 2017
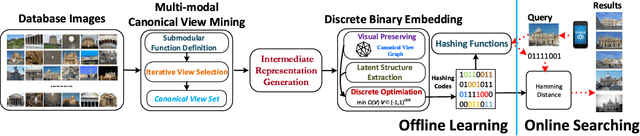


Mobile landmark search (MLS) recently receives increasing attention for its great practical values. However, it still remains unsolved due to two important challenges. One is high bandwidth consumption of query transmission, and the other is the huge visual variations of query images sent from mobile devices. In this paper, we propose a novel hashing scheme, named as canonical view based discrete multi-modal hashing (CV-DMH), to handle these problems via a novel three-stage learning procedure. First, a submodular function is designed to measure visual representativeness and redundancy of a view set. With it, canonical views, which capture key visual appearances of landmark with limited redundancy, are efficiently discovered with an iterative mining strategy. Second, multi-modal sparse coding is applied to transform visual features from multiple modalities into an intermediate representation. It can robustly and adaptively characterize visual contents of varied landmark images with certain canonical views. Finally, compact binary codes are learned on intermediate representation within a tailored discrete binary embedding model which preserves visual relations of images measured with canonical views and removes the involved noises. In this part, we develop a new augmented Lagrangian multiplier (ALM) based optimization method to directly solve the discrete binary codes. We can not only explicitly deal with the discrete constraint, but also consider the bit-uncorrelated constraint and balance constraint together. Experiments on real world landmark datasets demonstrate the superior performance of CV-DMH over several state-of-the-art methods.
Geometric Scene Parsing with Hierarchical LSTM
Apr 08, 2016


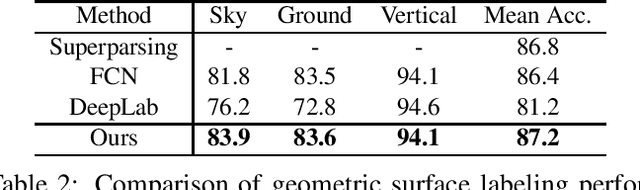
This paper addresses the problem of geometric scene parsing, i.e. simultaneously labeling geometric surfaces (e.g. sky, ground and vertical plane) and determining the interaction relations (e.g. layering, supporting, siding and affinity) between main regions. This problem is more challenging than the traditional semantic scene labeling, as recovering geometric structures necessarily requires the rich and diverse contextual information. To achieve these goals, we propose a novel recurrent neural network model, named Hierarchical Long Short-Term Memory (H-LSTM). It contains two coupled sub-networks: the Pixel LSTM (P-LSTM) and the Multi-scale Super-pixel LSTM (MS-LSTM) for handling the surface labeling and relation prediction, respectively. The two sub-networks provide complementary information to each other to exploit hierarchical scene contexts, and they are jointly optimized for boosting the performance. Our extensive experiments show that our model is capable of parsing scene geometric structures and outperforming several state-of-the-art methods by large margins. In addition, we show promising 3D reconstruction results from the still images based on the geometric parsing.
Human Re-identification by Matching Compositional Template with Cluster Sampling
Feb 01, 2015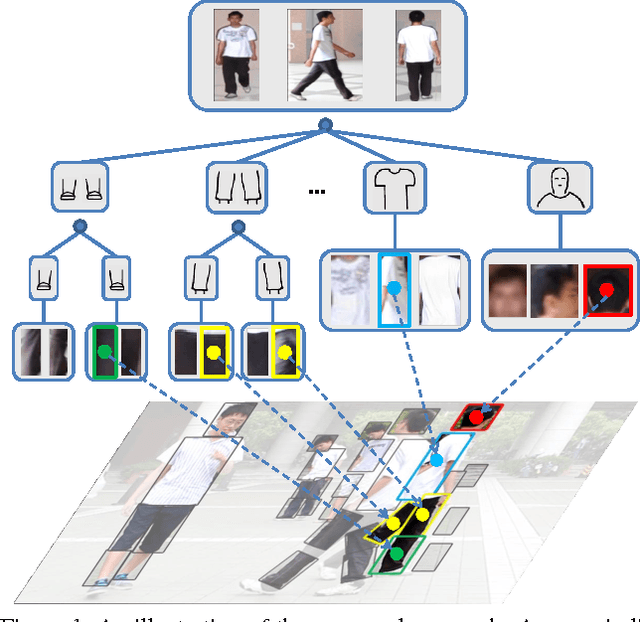
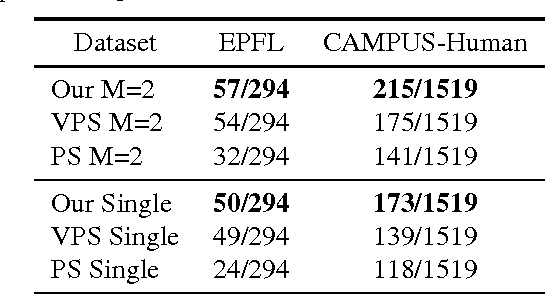
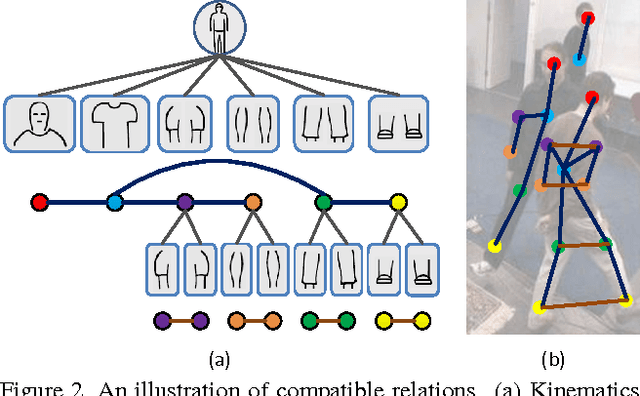
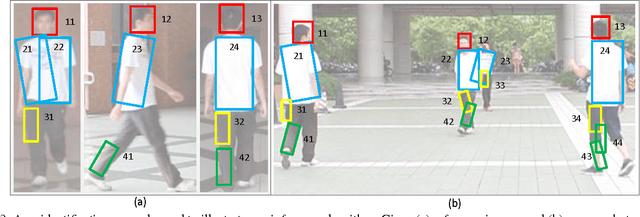
This paper aims at a newly raising task in visual surveillance: re-identifying people at a distance by matching body information, given several reference examples. Most of existing works solve this task by matching a reference template with the target individual, but often suffer from large human appearance variability (e.g. different poses/views, illumination) and high false positives in matching caused by conjunctions, occlusions or surrounding clutters. Addressing these problems, we construct a simple yet expressive template from a few reference images of a certain individual, which represents the body as an articulated assembly of compositional and alternative parts, and propose an effective matching algorithm with cluster sampling. This algorithm is designed within a candidacy graph whose vertices are matching candidates (i.e. a pair of source and target body parts), and iterates in two steps for convergence. (i) It generates possible partial matches based on compatible and competitive relations among body parts. (ii) It confirms the partial matches to generate a new matching solution, which is accepted by the Markov Chain Monte Carlo (MCMC) mechanism. In the experiments, we demonstrate the superior performance of our approach on three public databases compared to existing methods.