 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEARL: Prototype-Enhanced Alignment for Label-Efficient Representation Learning with Deployment-Driven Insights from Digital Governance Communication Systems
Jan 24, 2026In many deployed systems, new text inputs are handled by retrieving similar past cases, for example when routing and responding to citizen messages in digital governance platforms. When these systems fail, the problem is often not the language model itself, but that the nearest neighbors in the embedding space correspond to the wrong cases. Modern machine learning systems increasingly rely on fixed, high-dimensional embeddings produced by large pretrained models and sentence encoders. In real-world deployments, labels are scarce, domains shift over time, and retraining the base encoder is expensive or infeasible. As a result, downstream performance depends heavily on embedding geometry. Yet raw embeddings are often poorly aligned with the local neighborhood structure required by nearest-neighbor retrieval, similarity search, and lightweight classifiers that operate directly on embeddings. We propose PEARL (Prototype-Enhanced Aligned Representation Learning), a label-efficient approach that uses limited supervision to softly align embeddings toward class prototypes. The method reshapes local neighborhood geometry while preserving dimensionality and avoiding aggressive projection or collapse. Its aim is to bridge the gap between purely unsupervised post-processing, which offers limited and inconsistent gains, and fully supervised projections that require substantial labeled data. We evaluate PEARL under controlled label regimes ranging from extreme label scarcity to higher-label settings. In the label-scarce condition, PEARL substantially improves local neighborhood quality, yielding 25.7% gains over raw embeddings and more than 21.1% gains relative to strong unsupervised post-processing, precisely in the regime where similarity-based systems are most brittle.
Structural Equation-VAE: Disentangled Latent Representations for Tabular Data
Aug 08, 2025Learning interpretable latent representations from tabular data remains a challenge in deep generative modeling. We introduce SE-VAE (Structural Equation-Variational Autoencoder), a novel architecture that embeds measurement structure directly into the design of a variational autoencoder. Inspired by structural equation modeling, SE-VAE aligns latent subspaces with known indicator groupings and introduces a global nuisance latent to isolate construct-specific confounding variation. This modular architecture enables disentanglement through design rather than through statistical regularizers alone. We evaluate SE-VAE on a suite of simulated tabular datasets and benchmark its performance against a series of leading baselines using standard disentanglement metrics. SE-VAE consistently outperforms alternatives in factor recovery, interpretability, and robustness to nuisance variation. Ablation results reveal that architectural structure, rather than regularization strength, is the key driver of performance. SE-VAE offers a principled framework for white-box generative modeling in scientific and social domains where latent constructs are theory-driven and measurement validity is essential.
Achieving Semantic Consistency Using BERT: Application of Pre-training Semantic Representations Model in Social Sciences Research
Dec 03, 2024


Achieving consistent word interpretations across different time spans is crucial in social sciences research and text analysis tasks, as stable semantic representations form the foundation for research and task correctness, enhancing understanding of socio-political and cultural analysis. Traditional models like Word2Vec have provided significant insights into long-term semantic changes but often struggle to capture stable meanings in short-term contexts, which may be attributed to fluctuations in embeddings caused by unbalanced training data. Recent advancements, particularly BERT (Bidirectional Encoder Representations from Transformers), its pre-trained nature and transformer encoder architecture offer contextual embeddings that improve semantic consistency, making it a promising tool for short-term analysis. This study empirically compares the performance of Word2Vec and BERT in maintaining stable word meanings over time in text analysis tasks relevant to social sciences research. Using articles from the People's Daily spanning 20 years (2004-2023), we evaluated the semantic stability of each model across different timeframes. The results indicate that BERT consistently outperforms Word2Vec in maintaining semantic stability, offering greater stability in contextual embeddings. However, the study also acknowledges BERT's limitations in capturing gradual semantic shifts over longer periods due to its inherent stability. The findings suggest that while BERT is advantageous for short-term semantic analysis in social sciences, researchers should consider complementary approaches for long-term studies to fully capture semantic drift. This research underscores the importance of selecting appropriate word embedding models based on the specific temporal context of social science analyses.
Unconstrained Face Sketch Synthesis via Perception-Adaptive Network and A New Benchmark
Dec 02, 2021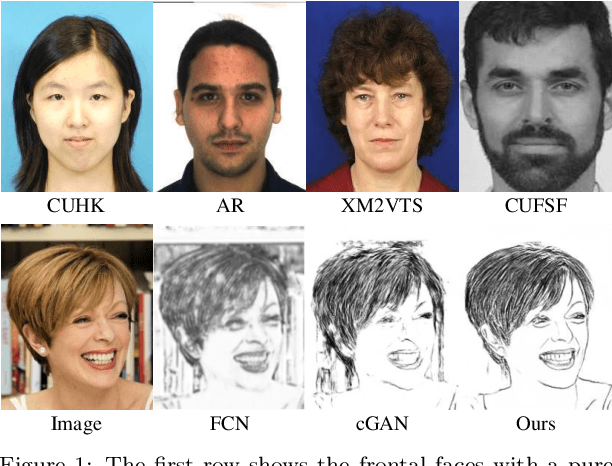
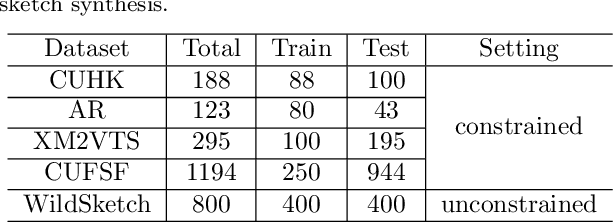

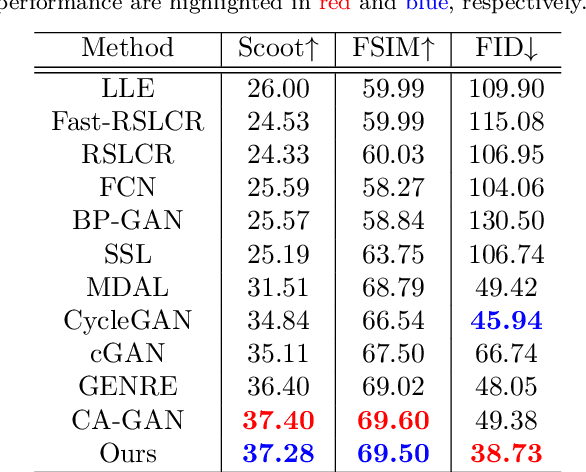
Face sketch generation has attracted much attention in the field of visual computing. However, existing methods either are limited to constrained conditions or heavily rely on various preprocessing steps to deal with in-the-wild cases. In this paper, we argue that accurately perceiving facial region and facial components is crucial for unconstrained sketch synthesis. To this end, we propose a novel Perception-Adaptive Network (PANet), which can generate high-quality face sketches under unconstrained conditions in an end-to-end scheme. Specifically, our PANet is composed of i) a Fully Convolutional Encoder for hierarchical feature extraction, ii) a Face-Adaptive Perceiving Decoder for extracting potential facial region and handling face variations, and iii) a Component-Adaptive Perceiving Module for facial component aware feature representation learning. To facilitate further researches of unconstrained face sketch synthesis, we introduce a new benchmark termed WildSketch, which contains 800 pairs of face photo-sketch with large variations in pose, expression, ethnic origin, background, and illumination. Extensive experiments demonstrate that the proposed method is capable of achieving state-of-the-art performance under both constrained and unconstrained conditions. Our source codes and the WildSketch benchmark are resealed on the project page http://lingboliu.com/unconstrained_face_sketch.html.
Instance-Aware Representation Learning and Association for Online Multi-Person Tracking
May 29, 2019
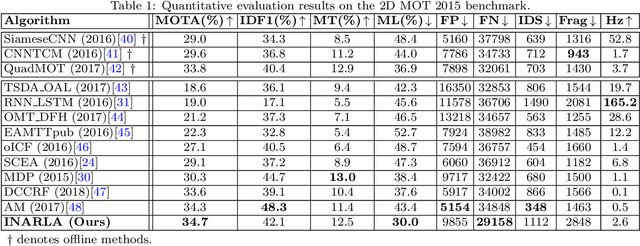
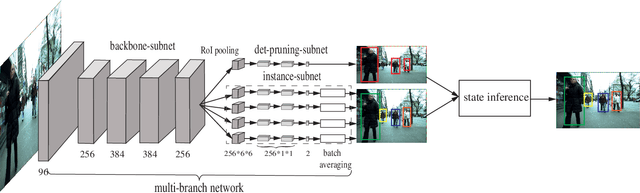
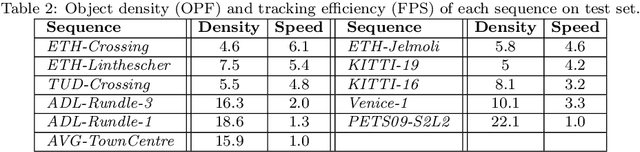
Multi-Person Tracking (MPT) is often addressed within the detection-to-association paradigm. In such approaches, human detections are first extracted in every frame and person trajectories are then recovered by a procedure of data association (usually offline). However, their performances usually degenerate in presence of detection errors, mutual interactions and occlusions. In this paper, we present a deep learning based MPT approach that learns instance-aware representations of tracked persons and robustly online infers states of the tracked persons. Specifically, we design a multi-branch neural network (MBN), which predicts the classification confidences and locations of all targets by taking a batch of candidate regions as input. In our MBN architecture, each branch (instance-subnet) corresponds to an individual to be tracked and new branches can be dynamically created for handling newly appearing persons. Then based on the output of MBN, we construct a joint association matrix that represents meaningful states of tracked persons (e.g., being tracked or disappearing from the scene) and solve it by using the efficient Hungarian algorithm. Moreover, we allow the instance-subnets to be updated during tracking by online mining hard examples, accounting to person appearance variations over time. We comprehensively evaluate our framework on a popular MPT benchmark, demonstrating its excellent performance in comparison with recent online MPT methods.
Neural Task Planning with And-Or Graph Representations
Aug 25, 2018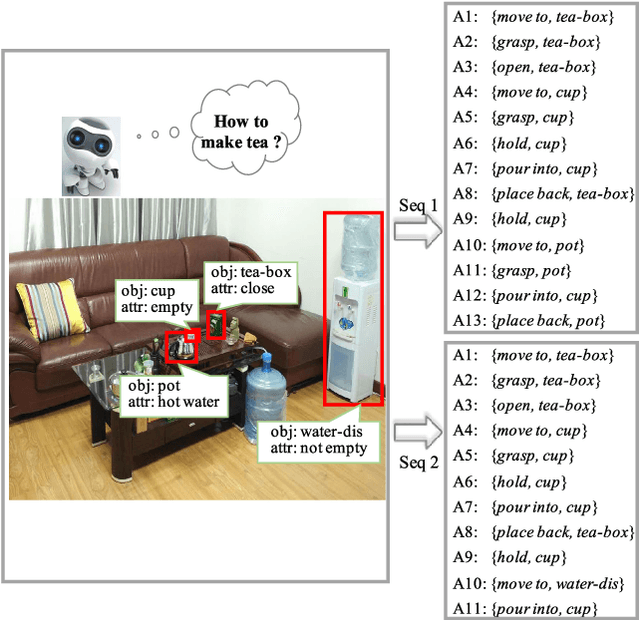
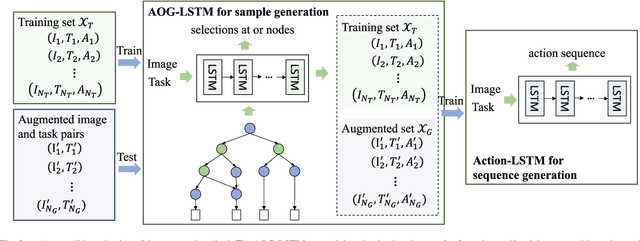
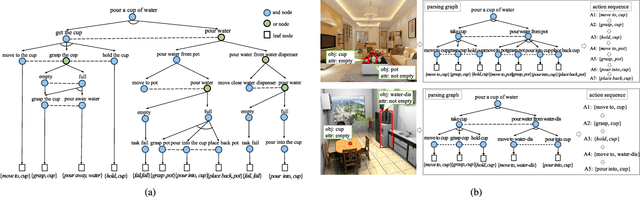
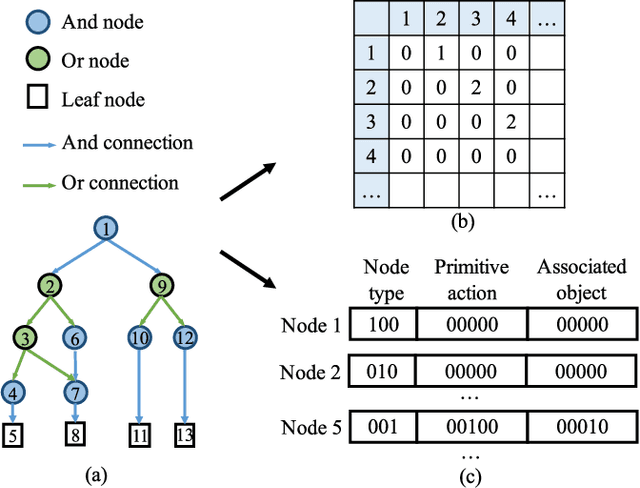
This paper focuses on semantic task planning, i.e., predicting a sequence of actions toward accomplishing a specific task under a certain scene, which is a new problem in computer vision research. The primary challenges are how to model task-specific knowledge and how to integrate this knowledge into the learning procedure. In this work, we propose training a recurrent long short-term memory (LSTM) network to address this problem, i.e., taking a scene image (including pre-located objects) and the specified task as input and recurrently predicting action sequences. However, training such a network generally requires large numbers of annotated samples to cover the semantic space (e.g., diverse action decomposition and ordering). To overcome this issue, we introduce a knowledge and-or graph (AOG) for task description, which hierarchically represents a task as atomic actions. With this AOG representation, we can produce many valid samples (i.e., action sequences according to common sense) by training another auxiliary LSTM network with a small set of annotated samples. Furthermore, these generated samples (i.e., task-oriented action sequences) effectively facilitate training of the model for semantic task planning. In our experiments, we create a new dataset that contains diverse daily tasks and extensively evaluate the effectiveness of our approach.