 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaDA2.0-Uni: Unifying Multimodal Understanding and Generation with Diffusion Large Language Model
Apr 22, 2026We present LLaDA2.0-Uni, a unified discrete diffusion large language model (dLLM) that supports multimodal understanding and generation within a natively integrated framework. Its architecture combines a fully semantic discrete tokenizer, a MoE-based dLLM backbone, and a diffusion decoder. By discretizing continuous visual inputs via SigLIP-VQ, the model enables block-level masked diffusion for both text and vision inputs within the backbone, while the decoder reconstructs visual tokens into high-fidelity images. Inference efficiency is enhanced beyond parallel decoding through prefix-aware optimizations in the backbone and few-step distillation in the decoder. Supported by carefully curated large-scale data and a tailored multi-stage training pipeline, LLaDA2.0-Uni matches specialized VLMs in multimodal understanding while delivering strong performance in image generation and editing. Its native support for interleaved generation and reasoning establishes a promising and scalable paradigm for next-generation unified foundation models. Codes and models are available at https://github.com/inclusionAI/LLaDA2.0-Uni.
Leum-VL Technical Report
Mar 20, 2026A short video succeeds not simply because of what it shows, but because of how it schedules attention -- yet current multimodal models lack the structural grammar to parse or produce this organization. Existing models can describe scenes, answer event-centric questions, and read on-screen text, but they are far less reliable at identifying timeline-grounded units such as hooks, cut rationales, shot-induced tension, and platform-facing packaging cues. We propose SV6D (Structured Video in Six Dimensions), inspired by professional storyboard practice in film and television production, a representation framework that decomposes internet-native video into six complementary structural dimensions -- subject, aesthetics, camera language, editing, narrative, and dissemination -- with each label tied to physically observable evidence on the timeline. We formalize a unified optimization objective over SV6D that combines Hungarian-matched temporal alignment, dimension-wise semantic label distance, and quality regularization. Building on this framework, we present Leum-VL-8B, an 8B video-language model that realizes the SV6D objective through an expert-driven post-training pipeline, further refined through verifiable reinforcement learning on perception-oriented tasks. Leum-VL-8B achieves 70.8 on VideoMME (w/o subtitles), 70.0 on MVBench, and 61.6 on MotionBench, while remaining competitive on general multimodal evaluations such as MMBench-EN. We also construct FeedBench, a benchmark for structure-sensitive short-video understanding. Our results indicate that the missing layer in video AI is not pixel generation but structural representation: grounded on the timeline, linked to visible evidence, and directly consumable by downstream workflows such as editing, retrieval, recommendation, and generation control, including text-heavy internet video formats with overlays and image-text layouts.
MHPO: Modulated Hazard-aware Policy Optimization for Stable Reinforcement Learning
Mar 14, 2026Regulating the importance ratio is critical for the training stability of Group Relative Policy Optimization (GRPO) based frameworks. However, prevailing ratio control methods, such as hard clipping, suffer from non-differentiable boundaries and vanishing gradient regions, failing to maintain gradient fidelity. Furthermore, these methods lack a hazard-aware mechanism to adaptively suppress extreme deviations, leaving the optimization process vulnerable to abrupt policy shifts. To address these challenges, we propose Modulated Hazard-aware Policy Optimization (MHPO), a novel framework designed for robust and stable reinforcement learning. The proposed MHPO introduces a Log-Fidelity Modulator (LFM) to map unbounded importance ratios into a bounded, differentiable domain. This mechanism effectively prevents high-variance outlier tokens from destabilizing the loss landscape while ensuring global gradient stability. Complementarily, a Decoupled Hazard Penalty (DHP) integrates cumulative hazard functions from survival analysis to independently regulate positive and negative policy shifts. By shaping the optimization landscape with hazard-aware penalties, the proposed MHPO achieves fine-grained regulation of asymmetric policy shifts simultaneously mitigating mode collapse from over-expansion and preventing policy erosion from catastrophic contraction within a stabilized trust region. Extensive evaluations on diverse reasoning benchmarks across both text-based and vision-language tasks demonstrate that MHPO consistently outperforms existing methods, achieving superior performance while significantly enhancing training stability.
TrajGPT-R: Generating Urban Mobility Trajectory with Reinforcement Learning-Enhanced Generative Pre-trained Transformer
Feb 24, 2026Mobility trajectories are essential for understanding urban dynamics and enhancing urban planning, yet access to such data is frequently hindered by privacy concerns. This research introduces a transformative framework for generating large-scale urban mobility trajectories, employing a novel application of a transformer-based model pre-trained and fine-tuned through a two-phase process. Initially, trajectory generation is conceptualized as an offline reinforcement learning (RL) problem, with a significant reduction in vocabulary space achieved during tokenization. The integration of Inverse Reinforcement Learning (IRL) allows for the capture of trajectory-wise reward signals, leveraging historical data to infer individual mobility preferences. Subsequently, the pre-trained model is fine-tuned using the constructed reward model, effectively addressing the challenges inherent in traditional RL-based autoregressive methods, such as long-term credit assignment and handling of sparse reward environments. Comprehensive evaluations on multiple datasets illustrate that our framework markedly surpasses existing models in terms of reliability and diversity. Our findings not only advance the field of urban mobility modeling but also provide a robust methodology for simulating urban data, with significant implications for traffic management and urban development planning. The implementation is publicly available at https://github.com/Wangjw6/TrajGPT_R.
Motion Blur Robust Wheat Pest Damage Detection with Dynamic Fuzzy Feature Fusion
Jan 06, 2026Motion blur caused by camera shake produces ghosting artifacts that substantially degrade edge side object detection. Existing approaches either suppress blur as noise and lose discriminative structure, or apply full image restoration that increases latency and limits deployment on resource constrained devices. We propose DFRCP, a Dynamic Fuzzy Robust Convolutional Pyramid, as a plug in upgrade to YOLOv11 for blur robust detection. DFRCP enhances the YOLOv11 feature pyramid by combining large scale and medium scale features while preserving native representations, and by introducing Dynamic Robust Switch units that adaptively inject fuzzy features to strengthen global perception under jitter. Fuzzy features are synthesized by rotating and nonlinearly interpolating multiscale features, then merged through a transparency convolution that learns a content adaptive trade off between original and fuzzy cues. We further develop a CUDA parallel rotation and interpolation kernel that avoids boundary overflow and delivers more than 400 times speedup, making the design practical for edge deployment. We train with paired supervision on a private wheat pest damage dataset of about 3,500 images, augmented threefold using two blur regimes, uniform image wide motion blur and bounding box confined rotational blur. On blurred test sets, YOLOv11 with DFRCP achieves about 10.4 percent higher accuracy than the YOLOv11 baseline with only a modest training time overhead, reducing the need for manual filtering after data collection.
Towards Resilient Transportation: A Conditional Transformer for Accident-Informed Traffic Forecasting
Dec 10, 2025Traffic prediction remains a key challenge in spatio-temporal data mining, despite progress in deep learning. Accurate forecasting is hindered by the complex influence of external factors such as traffic accidents and regulations, often overlooked by existing models due to limited data integration. To address these limitations, we present two enriched traffic datasets from Tokyo and California, incorporating traffic accident and regulation data. Leveraging these datasets, we propose ConFormer (Conditional Transformer), a novel framework that integrates graph propagation with guided normalization layer. This design dynamically adjusts spatial and temporal node relationships based on historical patterns, enhancing predictive accuracy. Our model surpasses the state-of-the-art STAEFormer in both predictive performance and efficiency, achieving lower computational costs and reduced parameter demands. Extensive evaluations demonstrate that ConFormer consistently outperforms mainstream spatio-temporal baselines across multiple metrics, underscoring its potential to advance traffic prediction research.
HarmoQ: Harmonized Post-Training Quantization for High-Fidelity Image
Nov 11, 2025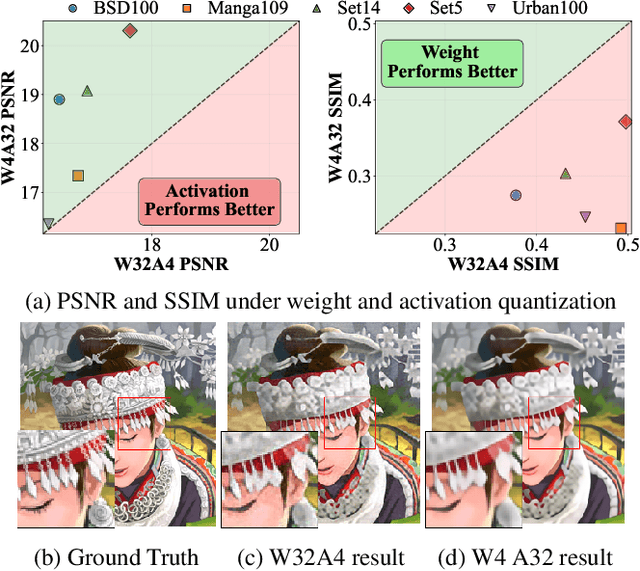
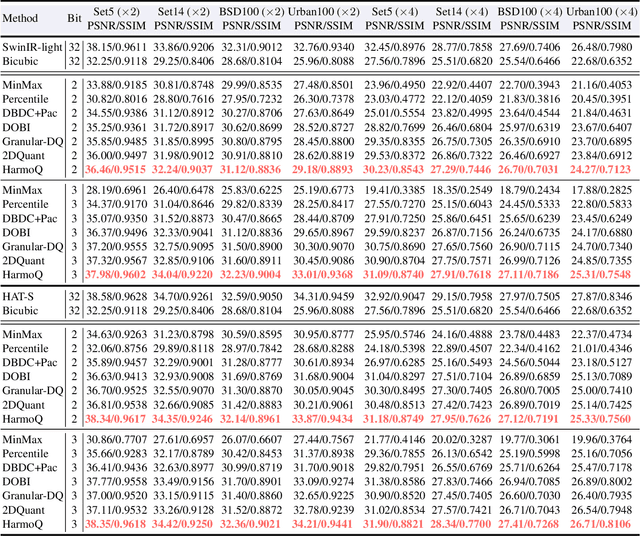
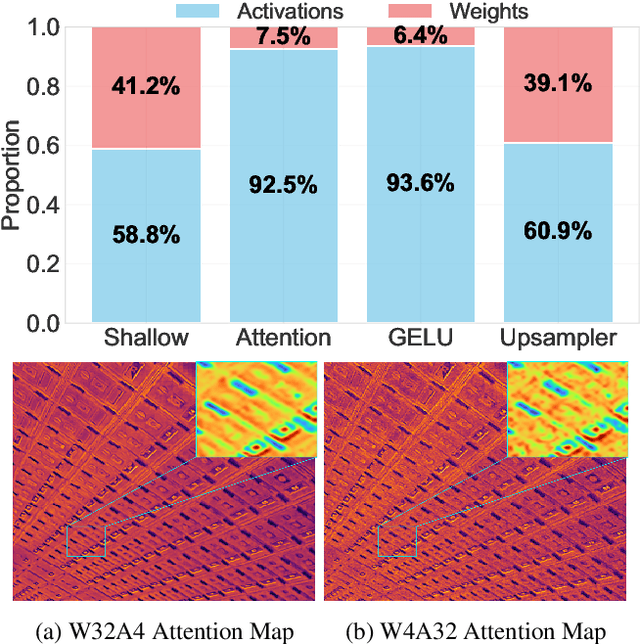
Post-training quantization offers an efficient pathway to deploy super-resolution models, yet existing methods treat weight and activation quantization independently, missing their critical interplay. Through controlled experiments on SwinIR, we uncover a striking asymmetry: weight quantization primarily degrades structural similarity, while activation quantization disproportionately affects pixel-level accuracy. This stems from their distinct roles--weights encode learned restoration priors for textures and edges, whereas activations carry input-specific intensity information. Building on this insight, we propose HarmoQ, a unified framework that harmonizes quantization across components through three synergistic steps: structural residual calibration proactively adjusts weights to compensate for activation-induced detail loss, harmonized scale optimization analytically balances quantization difficulty via closed-form solutions, and adaptive boundary refinement iteratively maintains this balance during optimization. Experiments show HarmoQ achieves substantial gains under aggressive compression, outperforming prior art by 0.46 dB on Set5 at 2-bit while delivering 3.2x speedup and 4x memory reduction on A100 GPUs. This work provides the first systematic analysis of weight-activation coupling in super-resolution quantization and establishes a principled solution for efficient high-quality image restoration.
Resilience Inference for Supply Chains with Hypergraph Neural Network
Nov 09, 2025Supply chains are integral to global economic stability, yet disruptions can swiftly propagate through interconnected networks, resulting in substantial economic impacts. Accurate and timely inference of supply chain resilience the capability to maintain core functions during disruptions is crucial for proactive risk mitigation and robust network design. However, existing approaches lack effective mechanisms to infer supply chain resilience without explicit system dynamics and struggle to represent the higher-order, multi-entity dependencies inherent in supply chain networks. These limitations motivate the definition of a novel problem and the development of targeted modeling solutions. To address these challenges, we formalize a novel problem: Supply Chain Resilience Inference (SCRI), defined as predicting supply chain resilience using hypergraph topology and observed inventory trajectories without explicit dynamic equations. To solve this problem, we propose the Supply Chain Resilience Inference Hypergraph Network (SC-RIHN), a novel hypergraph-based model leveraging set-based encoding and hypergraph message passing to capture multi-party firm-product interactions. Comprehensive experiments demonstrate that SC-RIHN significantly outperforms traditional MLP, representative graph neural network variants, and ResInf baselines across synthetic benchmarks, underscoring its potential for practical, early-warning risk assessment in complex supply chain systems.
Not All Degradations Are Equal: A Targeted Feature Denoising Framework for Generalizable Image Super-Resolution
Sep 18, 2025Generalizable Image Super-Resolution aims to enhance model generalization capabilities under unknown degradations. To achieve this goal, the models are expected to focus only on image content-related features instead of overfitting degradations. Recently, numerous approaches such as Dropout and Feature Alignment have been proposed to suppress models' natural tendency to overfit degradations and yield promising results. Nevertheless, these works have assumed that models overfit to all degradation types (e.g., blur, noise, JPEG), while through careful investigations in this paper, we discover that models predominantly overfit to noise, largely attributable to its distinct degradation pattern compared to other degradation types. In this paper, we propose a targeted feature denoising framework, comprising noise detection and denoising modules. Our approach presents a general solution that can be seamlessly integrated with existing super-resolution models without requiring architectural modifications. Our framework demonstrates superior performance compared to previous regularization-based methods across five traditional benchmarks and datasets, encompassing both synthetic and real-world scenarios.
MultiEdit: Advancing Instruction-based Image Editing on Diverse and Challenging Tasks
Sep 18, 2025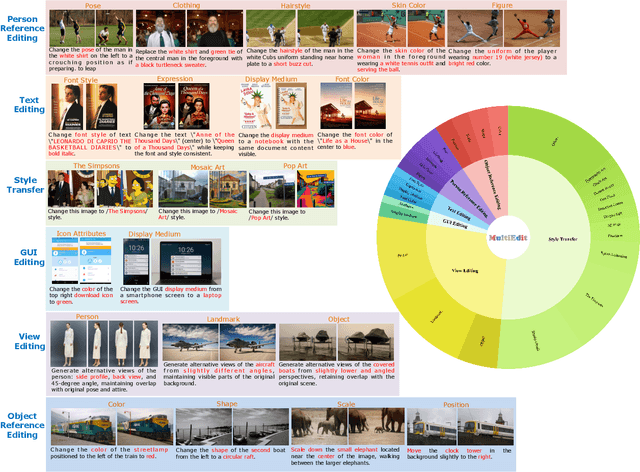
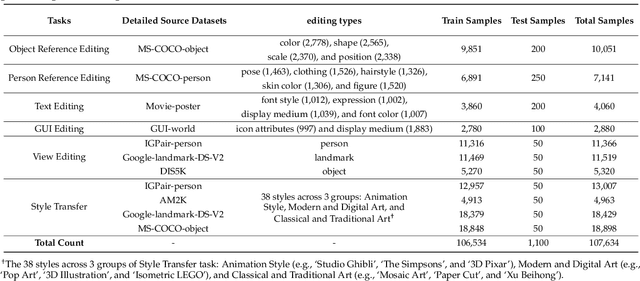
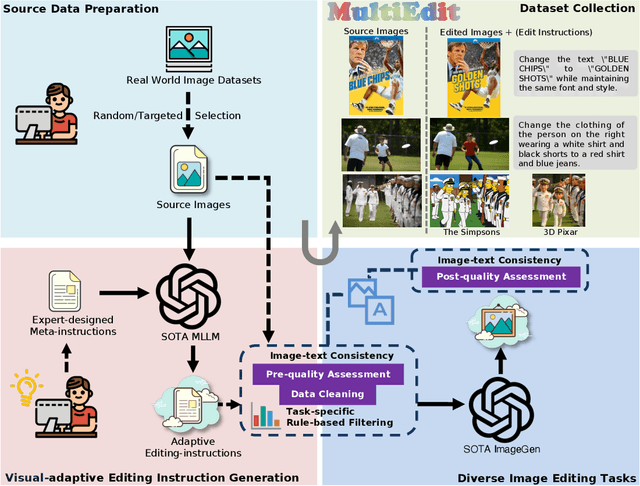
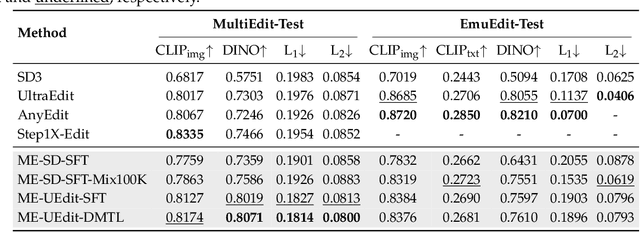
Current instruction-based image editing (IBIE) methods struggle with challenging editing tasks, as both editing types and sample counts of existing datasets are limited. Moreover, traditional dataset construction often contains noisy image-caption pairs, which may introduce biases and limit model capabilities in complex editing scenarios. To address these limitations, we introduce MultiEdit, a comprehensive dataset featuring over 107K high-quality image editing samples. It encompasses 6 challenging editing tasks through a diverse collection of 18 non-style-transfer editing types and 38 style transfer operations, covering a spectrum from sophisticated style transfer to complex semantic operations like person reference editing and in-image text editing. We employ a novel dataset construction pipeline that utilizes two multi-modal large language models (MLLMs) to generate visual-adaptive editing instructions and produce high-fidelity edited images, respectively. Extensive experiments demonstrate that fine-tuning foundational open-source models with our MultiEdit-Train set substantially improves models' performance on sophisticated editing tasks in our proposed MultiEdit-Test benchmark, while effectively preserving their capabilities on the standard editing benchmark. We believe MultiEdit provides a valuable resource for advancing research into more diverse and challenging IBIE capabilities. Our dataset is available at https://huggingface.co/datasets/inclusionAI/MultiEdit.