 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniPAR: A Unified Framework for Pedestrian Attribute Recognition
Mar 05, 2026Pedestrian Attribute Recognition is a foundational computer vision task that provides essential support for downstream applications, including person retrieval in video surveillance and intelligent retail analytics. However, existing research is frequently constrained by the ``one-model-per-dataset" paradigm and struggles to handle significant discrepancies across domains in terms of modalities, attribute definitions, and environmental scenarios. To address these challenges, we propose UniPAR, a unified Transformer-based framework for PAR. By incorporating a unified data scheduling strategy and a dynamic classification head, UniPAR enables a single model to simultaneously process diverse datasets from heterogeneous modalities, including RGB images, video sequences, and event streams. We also introduce an innovative phased fusion encoder that explicitly aligns visual features with textual attribute queries through a late deep fusion strategy. Experimental results on the widely used benchmark datasets, including MSP60K, DukeMTMC, and EventPAR, demonstrate that UniPAR achieves performance comparable to specialized SOTA methods. Furthermore, multi-dataset joint training significantly enhances the model's cross-domain generalization and recognition robustness in extreme environments characterized by low light and motion blur. The source code of this paper will be released on https://github.com/Event-AHU/OpenPAR
Decoupling Amplitude and Phase Attention in Frequency Domain for RGB-Event based Visual Object Tracking
Jan 03, 2026Existing RGB-Event visual object tracking approaches primarily rely on conventional feature-level fusion, failing to fully exploit the unique advantages of event cameras. In particular, the high dynamic range and motion-sensitive nature of event cameras are often overlooked, while low-information regions are processed uniformly, leading to unnecessary computational overhead for the backbone network. To address these issues, we propose a novel tracking framework that performs early fusion in the frequency domain, enabling effective aggregation of high-frequency information from the event modality. Specifically, RGB and event modalities are transformed from the spatial domain to the frequency domain via the Fast Fourier Transform, with their amplitude and phase components decoupled. High-frequency event information is selectively fused into RGB modality through amplitude and phase attention, enhancing feature representation while substantially reducing backbone computation. In addition, a motion-guided spatial sparsification module leverages the motion-sensitive nature of event cameras to capture the relationship between target motion cues and spatial probability distribution, filtering out low-information regions and enhancing target-relevant features. Finally, a sparse set of target-relevant features is fed into the backbone network for learning, and the tracking head predicts the final target position. Extensive experiments on three widely used RGB-Event tracking benchmark datasets, including FE108, FELT, and COESOT, demonstrate the high performance and efficiency of our method. The source code of this paper will be released on https://github.com/Event-AHU/OpenEvTracking
One-Minute Video Generation with Test-Time Training
Apr 07, 2025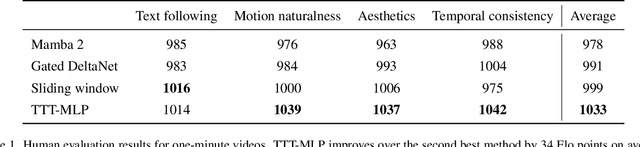
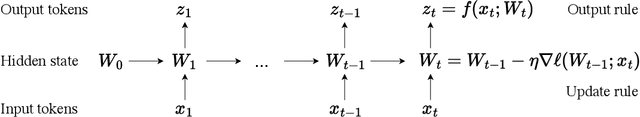
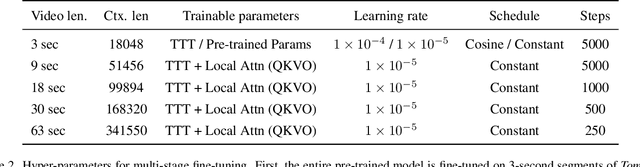
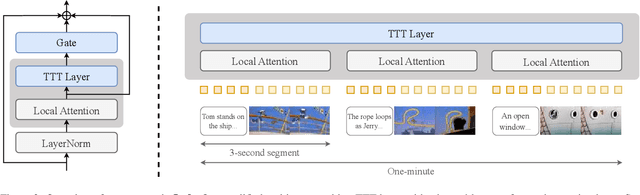
Transformers today still struggle to generate one-minute videos because self-attention layers are inefficient for long context. Alternatives such as Mamba layers struggle with complex multi-scene stories because their hidden states are less expressive. We experiment with Test-Time Training (TTT) layers, whose hidden states themselves can be neural networks, therefore more expressive. Adding TTT layers into a pre-trained Transformer enables it to generate one-minute videos from text storyboards. For proof of concept, we curate a dataset based on Tom and Jerry cartoons. Compared to baselines such as Mamba~2, Gated DeltaNet, and sliding-window attention layers, TTT layers generate much more coherent videos that tell complex stories, leading by 34 Elo points in a human evaluation of 100 videos per method. Although promising, results still contain artifacts, likely due to the limited capability of the pre-trained 5B model. The efficiency of our implementation can also be improved. We have only experimented with one-minute videos due to resource constraints, but the approach can be extended to longer videos and more complex stories. Sample videos, code and annotations are available at: https://test-time-training.github.io/video-dit
A Framework to Assess Multilingual Vulnerabilities of LLMs
Mar 17, 2025



Large Language Models (LLMs) are acquiring a wider range of capabilities, including understanding and responding in multiple languages. While they undergo safety training to prevent them from answering illegal questions, imbalances in training data and human evaluation resources can make these models more susceptible to attacks in low-resource languages (LRL). This paper proposes a framework to automatically assess the multilingual vulnerabilities of commonly used LLMs. Using our framework, we evaluated six LLMs across eight languages representing varying levels of resource availability. We validated the assessments generated by our automated framework through human evaluation in two languages, demonstrating that the framework's results align with human judgments in most cases. Our findings reveal vulnerabilities in LRL; however, these may pose minimal risk as they often stem from the model's poor performance, resulting in incoherent responses.
LoRA-TTT: Low-Rank Test-Time Training for Vision-Language Models
Feb 04, 2025The rapid advancements in vision-language models (VLMs), such as CLIP, have intensified the need to address distribution shifts between training and testing datasets. Although prior Test-Time Training (TTT) techniques for VLMs have demonstrated robust performance, they predominantly rely on tuning text prompts, a process that demands substantial computational resources and is heavily dependent on entropy-based loss. In this paper, we propose LoRA-TTT, a novel TTT method that leverages Low-Rank Adaptation (LoRA), applied exclusively to the image encoder of VLMs. By introducing LoRA and updating only its parameters during test time, our method offers a simple yet effective TTT approach, retaining the model's initial generalization capability while achieving substantial performance gains with minimal memory and runtime overhead. Additionally, we introduce a highly efficient reconstruction loss tailored for TTT. Our method can adapt to diverse domains by combining these two losses, without increasing memory consumption or runtime. Extensive experiments on two benchmarks, covering 15 datasets, demonstrate that our method improves the zero-shot top-1 accuracy of CLIP-ViT-B/16 by an average of 5.79% on the OOD benchmark and 1.36% on the fine-grained benchmark, efficiently surpassing test-time prompt tuning, without relying on any external models or cache.
Parallel Sequence Modeling via Generalized Spatial Propagation Network
Jan 21, 2025



We present the Generalized Spatial Propagation Network (GSPN), a new attention mechanism optimized for vision tasks that inherently captures 2D spatial structures. Existing attention models, including transformers, linear attention, and state-space models like Mamba, process multi-dimensional data as 1D sequences, compromising spatial coherence and efficiency. GSPN overcomes these limitations by directly operating on spatially coherent image data and forming dense pairwise connections through a line-scan approach. Central to GSPN is the Stability-Context Condition, which ensures stable, context-aware propagation across 2D sequences and reduces the effective sequence length to $\sqrt{N}$ for a square map with N elements, significantly enhancing computational efficiency. With learnable, input-dependent weights and no reliance on positional embeddings, GSPN achieves superior spatial fidelity and state-of-the-art performance in vision tasks, including ImageNet classification, class-guided image generation, and text-to-image generation. Notably, GSPN accelerates SD-XL with softmax-attention by over $84\times$ when generating 16K images.
HandsOnVLM: Vision-Language Models for Hand-Object Interaction Prediction
Dec 17, 2024



How can we predict future interaction trajectories of human hands in a scene given high-level colloquial task specifications in the form of natural language? In this paper, we extend the classic hand trajectory prediction task to two tasks involving explicit or implicit language queries. Our proposed tasks require extensive understanding of human daily activities and reasoning abilities about what should be happening next given cues from the current scene. We also develop new benchmarks to evaluate the proposed two tasks, Vanilla Hand Prediction (VHP) and Reasoning-Based Hand Prediction (RBHP). We enable solving these tasks by integrating high-level world knowledge and reasoning capabilities of Vision-Language Models (VLMs) with the auto-regressive nature of low-level ego-centric hand trajectories. Our model, HandsOnVLM is a novel VLM that can generate textual responses and produce future hand trajectories through natural-language conversations. Our experiments show that HandsOnVLM outperforms existing task-specific methods and other VLM baselines on proposed tasks, and demonstrates its ability to effectively utilize world knowledge for reasoning about low-level human hand trajectories based on the provided context. Our website contains code and detailed video results \url{https://www.chenbao.tech/handsonvlm/}
Learning to (Learn at Test Time): RNNs with Expressive Hidden States
Jul 05, 2024Self-attention performs well in long context but has quadratic complexity. Existing RNN layers have linear complexity, but their performance in long context is limited by the expressive power of their hidden state. We propose a new class of sequence modeling layers with linear complexity and an expressive hidden state. The key idea is to make the hidden state a machine learning model itself, and the update rule a step of self-supervised learning. Since the hidden state is updated by training even on test sequences, our layers are called Test-Time Training (TTT) layers. We consider two instantiations: TTT-Linear and TTT-MLP, whose hidden state is a linear model and a two-layer MLP respectively. We evaluate our instantiations at the scale of 125M to 1.3B parameters, comparing with a strong Transformer and Mamba, a modern RNN. Both TTT-Linear and TTT-MLP match or exceed the baselines. Similar to Transformer, they can keep reducing perplexity by conditioning on more tokens, while Mamba cannot after 16k context. With preliminary systems optimization, TTT-Linear is already faster than Transformer at 8k context and matches Mamba in wall-clock time. TTT-MLP still faces challenges in memory I/O, but shows larger potential in long context, pointing to a promising direction for future research.
Learning at the Speed of Wireless: Online Real-Time Learning for AI-Enabled MIMO in NextG
Mar 05, 2024



Integration of artificial intelligence (AI) and machine learning (ML) into the air interface has been envisioned as a key technology for next-generation (NextG) cellular networks. At the air interface, multiple-input multiple-output (MIMO) and its variants such as multi-user MIMO (MU-MIMO) and massive/full-dimension MIMO have been key enablers across successive generations of cellular networks with evolving complexity and design challenges. Initiating active investigation into leveraging AI/ML tools to address these challenges for MIMO becomes a critical step towards an AI-enabled NextG air interface. At the NextG air interface, the underlying wireless environment will be extremely dynamic with operation adaptations performed on a sub-millisecond basis by MIMO operations such as MU-MIMO scheduling and rank/link adaptation. Given the enormously large number of operation adaptation possibilities, we contend that online real-time AI/ML-based approaches constitute a promising paradigm. To this end, we outline the inherent challenges and offer insights into the design of such online real-time AI/ML-based solutions for MIMO operations. An online real-time AI/ML-based method for MIMO-OFDM channel estimation is then presented, serving as a potential roadmap for developing similar techniques across various MIMO operations in NextG.
Pixel Aligned Language Models
Dec 14, 2023Large language models have achieved great success in recent years, so as their variants in vision. Existing vision-language models can describe images in natural languages, answer visual-related questions, or perform complex reasoning about the image. However, it is yet unclear how localization tasks, such as word grounding or referring localization, can be performed using large language models. In this work, we aim to develop a vision-language model that can take locations, for example, a set of points or boxes, as either inputs or outputs. When taking locations as inputs, the model performs location-conditioned captioning, which generates captions for the indicated object or region. When generating locations as outputs, our model regresses pixel coordinates for each output word generated by the language model, and thus performs dense word grounding. Our model is pre-trained on the Localized Narrative dataset, which contains pixel-word-aligned captioning from human attention. We show our model can be applied to various location-aware vision-language tasks, including referring localization, location-conditioned captioning, and dense object captioning, archiving state-of-the-art performance on RefCOCO and Visual Genome. Project page: https://jerryxu.net/PixelLLM .