 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Test-Time Training for Long Context
Dec 31, 2025We formulate long-context language modeling as a problem in continual learning rather than architecture design. Under this formulation, we only use a standard architecture -- a Transformer with sliding-window attention. However, our model continues learning at test time via next-token prediction on the given context, compressing the context it reads into its weights. In addition, we improve the model's initialization for learning at test time via meta-learning at training time. Overall, our method, a form of Test-Time Training (TTT), is End-to-End (E2E) both at test time (via next-token prediction) and training time (via meta-learning), in contrast to previous forms. We conduct extensive experiments with a focus on scaling properties. In particular, for 3B models trained with 164B tokens, our method (TTT-E2E) scales with context length in the same way as Transformer with full attention, while others, such as Mamba 2 and Gated DeltaNet, do not. However, similar to RNNs, TTT-E2E has constant inference latency regardless of context length, making it 2.7 times faster than full attention for 128K context. Our code is publicly available.
One-Minute Video Generation with Test-Time Training
Apr 07, 2025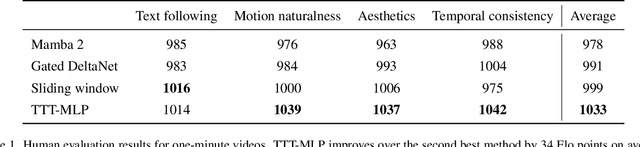
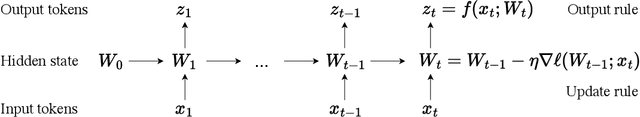
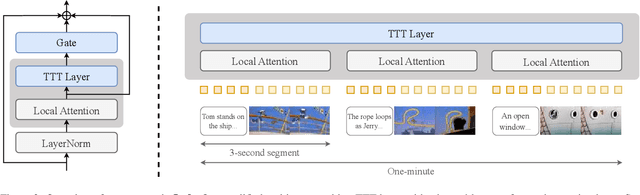
Transformers today still struggle to generate one-minute videos because self-attention layers are inefficient for long context. Alternatives such as Mamba layers struggle with complex multi-scene stories because their hidden states are less expressive. We experiment with Test-Time Training (TTT) layers, whose hidden states themselves can be neural networks, therefore more expressive. Adding TTT layers into a pre-trained Transformer enables it to generate one-minute videos from text storyboards. For proof of concept, we curate a dataset based on Tom and Jerry cartoons. Compared to baselines such as Mamba~2, Gated DeltaNet, and sliding-window attention layers, TTT layers generate much more coherent videos that tell complex stories, leading by 34 Elo points in a human evaluation of 100 videos per method. Although promising, results still contain artifacts, likely due to the limited capability of the pre-trained 5B model. The efficiency of our implementation can also be improved. We have only experimented with one-minute videos due to resource constraints, but the approach can be extended to longer videos and more complex stories. Sample videos, code and annotations are available at: https://test-time-training.github.io/video-dit
Learning to (Learn at Test Time): RNNs with Expressive Hidden States
Jul 05, 2024Self-attention performs well in long context but has quadratic complexity. Existing RNN layers have linear complexity, but their performance in long context is limited by the expressive power of their hidden state. We propose a new class of sequence modeling layers with linear complexity and an expressive hidden state. The key idea is to make the hidden state a machine learning model itself, and the update rule a step of self-supervised learning. Since the hidden state is updated by training even on test sequences, our layers are called Test-Time Training (TTT) layers. We consider two instantiations: TTT-Linear and TTT-MLP, whose hidden state is a linear model and a two-layer MLP respectively. We evaluate our instantiations at the scale of 125M to 1.3B parameters, comparing with a strong Transformer and Mamba, a modern RNN. Both TTT-Linear and TTT-MLP match or exceed the baselines. Similar to Transformer, they can keep reducing perplexity by conditioning on more tokens, while Mamba cannot after 16k context. With preliminary systems optimization, TTT-Linear is already faster than Transformer at 8k context and matches Mamba in wall-clock time. TTT-MLP still faces challenges in memory I/O, but shows larger potential in long context, pointing to a promising direction for future research.
Learning to (Learn at Test Time)
Oct 20, 2023



We reformulate the problem of supervised learning as learning to learn with two nested loops (i.e. learning problems). The inner loop learns on each individual instance with self-supervision before final prediction. The outer loop learns the self-supervised task used by the inner loop, such that its final prediction improves. Our inner loop turns out to be equivalent to linear attention when the inner-loop learner is only a linear model, and to self-attention when it is a kernel estimator. For practical comparison with linear or self-attention layers, we replace each of them in a transformer with an inner loop, so our outer loop is equivalent to training the architecture. When each inner-loop learner is a neural network, our approach vastly outperforms transformers with linear attention on ImageNet from 224 x 224 raw pixels in both accuracy and FLOPs, while (regular) transformers cannot run.