 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Tensor Program: A streaming abstraction for dynamic parallelism
Nov 11, 2025
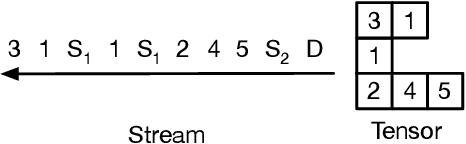
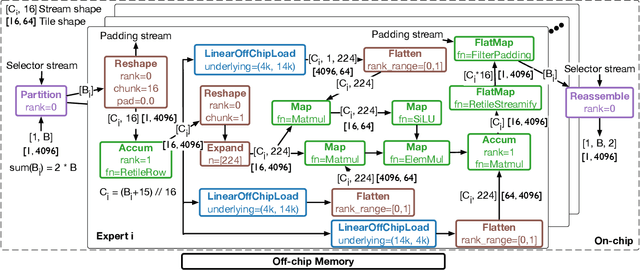

Dynamic behaviors are becoming prevalent in many tensor applications. In machine learning, for example, the input tensors are dynamically shaped or ragged, and data-dependent control flow is widely used in many models. However, the limited expressiveness of prior programming abstractions for spatial dataflow accelerators forces the dynamic behaviors to be implemented statically or lacks the visibility for performance-critical decisions. To address these challenges, we present the Streaming Tensor Program (STeP), a new streaming abstraction that enables dynamic tensor workloads to run efficiently on spatial dataflow accelerators. STeP introduces flexible routing operators, an explicit memory hierarchy, and symbolic shape semantics that expose dynamic data rates and tensor dimensions. These capabilities unlock new optimizations-dynamic tiling, dynamic parallelization, and configuration time-multiplexing-that adapt to dynamic behaviors while preserving dataflow efficiency. Using a cycle-approximate simulator on representative LLM layers with real-world traces, dynamic tiling reduces on-chip memory requirement by 2.18x, dynamic parallelization improves latency by 1.5x, and configuration time-multiplexing improves compute utilization by 2.57x over implementations available in prior abstractions.
Adaptive Self-improvement LLM Agentic System for ML Library Development
Feb 04, 2025ML libraries, often written in architecture-specific programming languages (ASPLs) that target domain-specific architectures, are key to efficient ML systems. However, writing these high-performance ML libraries is challenging because it requires expert knowledge of ML algorithms and the ASPL. Large language models (LLMs), on the other hand, have shown general coding capabilities. However, challenges remain when using LLMs for generating ML libraries using ASPLs because 1) this task is complicated even for experienced human programmers and 2) there are limited code examples because of the esoteric and evolving nature of ASPLs. Therefore, LLMs need complex reasoning with limited data in order to complete this task. To address these challenges, we introduce an adaptive self-improvement agentic system. In order to evaluate the effectiveness of our system, we construct a benchmark of a typical ML library and generate ASPL code with both open and closed-source LLMs on this benchmark. Our results show improvements of up to $3.9\times$ over a baseline single LLM.
Mixture-of-Mamba: Enhancing Multi-Modal State-Space Models with Modality-Aware Sparsity
Jan 27, 2025



State Space Models (SSMs) have emerged as efficient alternatives to Transformers for sequential modeling, but their inability to leverage modality-specific features limits their performance in multi-modal pretraining. Here, we propose Mixture-of-Mamba, a novel SSM architecture that introduces modality-aware sparsity through modality-specific parameterization of the Mamba block. Building on Mixture-of-Transformers (W. Liang et al. arXiv:2411.04996; 2024), we extend the benefits of modality-aware sparsity to SSMs while preserving their computational efficiency. We evaluate Mixture-of-Mamba across three multi-modal pretraining settings: Transfusion (interleaved text and continuous image tokens with diffusion loss), Chameleon (interleaved text and discrete image tokens), and an extended three-modality framework incorporating speech. Mixture-of-Mamba consistently reaches the same loss values at earlier training steps with significantly reduced computational costs. In the Transfusion setting, Mixture-of-Mamba achieves equivalent image loss using only 34.76% of the training FLOPs at the 1.4B scale. In the Chameleon setting, Mixture-of-Mamba reaches similar image loss with just 42.50% of the FLOPs at the 1.4B scale, and similar text loss with just 65.40% of the FLOPs. In the three-modality setting, MoM matches speech loss at 24.80% of the FLOPs at the 1.4B scale. Our ablation study highlights the synergistic effects of decoupling projection components, where joint decoupling yields greater gains than individual modifications. These results establish modality-aware sparsity as a versatile and effective design principle, extending its impact from Transformers to SSMs and setting new benchmarks in multi-modal pretraining. Our code can be accessed at https://github.com/Weixin-Liang/Mixture-of-Mamba
Learning to (Learn at Test Time): RNNs with Expressive Hidden States
Jul 05, 2024Self-attention performs well in long context but has quadratic complexity. Existing RNN layers have linear complexity, but their performance in long context is limited by the expressive power of their hidden state. We propose a new class of sequence modeling layers with linear complexity and an expressive hidden state. The key idea is to make the hidden state a machine learning model itself, and the update rule a step of self-supervised learning. Since the hidden state is updated by training even on test sequences, our layers are called Test-Time Training (TTT) layers. We consider two instantiations: TTT-Linear and TTT-MLP, whose hidden state is a linear model and a two-layer MLP respectively. We evaluate our instantiations at the scale of 125M to 1.3B parameters, comparing with a strong Transformer and Mamba, a modern RNN. Both TTT-Linear and TTT-MLP match or exceed the baselines. Similar to Transformer, they can keep reducing perplexity by conditioning on more tokens, while Mamba cannot after 16k context. With preliminary systems optimization, TTT-Linear is already faster than Transformer at 8k context and matches Mamba in wall-clock time. TTT-MLP still faces challenges in memory I/O, but shows larger potential in long context, pointing to a promising direction for future research.
MoA: Mixture of Sparse Attention for Automatic Large Language Model Compression
Jun 21, 2024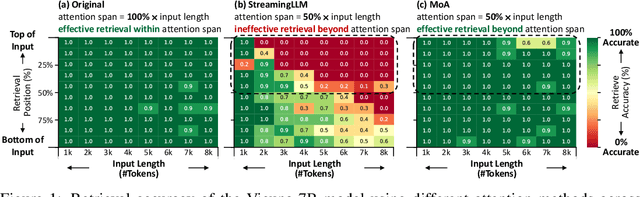
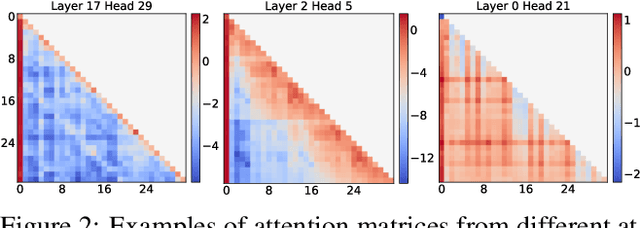

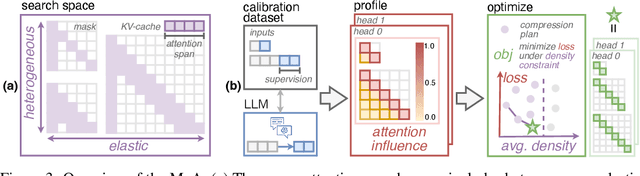
Sparse attention can effectively mitigate the significant memory and throughput demands of Large Language Models (LLMs) in long contexts. Existing methods typically employ a uniform sparse attention mask, applying the same sparse pattern across different attention heads and input lengths. However, this uniform approach fails to capture the diverse attention patterns inherent in LLMs, ignoring their distinct accuracy-latency trade-offs. To address this challenge, we propose the Mixture of Attention (MoA), which automatically tailors distinct sparse attention configurations to different heads and layers. MoA constructs and navigates a search space of various attention patterns and their scaling rules relative to input sequence lengths. It profiles the model, evaluates potential configurations, and pinpoints the optimal sparse attention compression plan. MoA adapts to varying input sizes, revealing that some attention heads expand their focus to accommodate longer sequences, while other heads consistently concentrate on fixed-length local contexts. Experiments show that MoA increases the effective context length by $3.9\times$ with the same average attention span, boosting retrieval accuracy by $1.5-7.1\times$ over the uniform-attention baseline across Vicuna-7B, Vicuna-13B, and Llama3-8B models. Moreover, MoA narrows the capability gaps between sparse and dense models, reducing the maximum relative performance drop from $9\%-36\%$ to within $5\%$ across two long-context understanding benchmarks. MoA achieves a $1.2-1.4\times$ GPU memory reduction and boosts decode throughput by $5.5-6.7 \times$ for 7B and 13B dense models on a single GPU, with minimal impact on performance.
CATS: Contextually-Aware Thresholding for Sparsity in Large Language Models
Apr 12, 2024Large Language Models (LLMs) have dramatically advanced AI applications, yet their deployment remains challenging due to their immense inference costs. Recent studies ameliorate the computational costs of LLMs by increasing their activation sparsity but suffer from significant performance degradation on downstream tasks. In this work, we introduce a new framework for sparsifying the activations of base LLMs and reducing inference costs, dubbed Contextually Aware Thresholding for Sparsity (CATS). CATS is relatively simple, easy to implement, and highly effective. At the heart of our framework is a new non-linear activation function. We demonstrate that CATS can be applied to various base models, including Mistral-7B and Llama2-7B, and outperforms existing sparsification techniques in downstream task performance. More precisely, CATS-based models often achieve downstream task performance within 1-2% of their base models without any fine-tuning and even at activation sparsity levels of 50%. Furthermore, CATS-based models converge faster and display better task performance than competing techniques when fine-tuning is applied. Finally, we develop a custom GPU kernel for efficient implementation of CATS that translates the activation of sparsity of CATS to real wall-clock time speedups. Our custom kernel implementation of CATS results in a ~15% improvement in wall-clock inference latency of token generation on both Llama-7B and Mistral-7B.
GeoT: Tensor Centric Library for Graph Neural Network via Efficient Segment Reduction on GPU
Apr 08, 2024In recent years, Graph Neural Networks (GNNs) have ignited a surge of innovation, significantly enhancing the processing of geometric data structures such as graphs, point clouds, and meshes. As the domain continues to evolve, a series of frameworks and libraries are being developed to push GNN efficiency to new heights. While graph-centric libraries have achieved success in the past, the advent of efficient tensor compilers has highlighted the urgent need for tensor-centric libraries. Yet, efficient tensor-centric frameworks for GNNs remain scarce due to unique challenges and limitations encountered when implementing segment reduction in GNN contexts. We introduce GeoT, a cutting-edge tensor-centric library designed specifically for GNNs via efficient segment reduction. GeoT debuts innovative parallel algorithms that not only introduce new design principles but also expand the available design space. Importantly, GeoT is engineered for straightforward fusion within a computation graph, ensuring compatibility with contemporary tensor-centric machine learning frameworks and compilers. Setting a new performance benchmark, GeoT marks a considerable advancement by showcasing an average operator speedup of 1.80x and an end-to-end speedup of 1.68x.
Canvas: End-to-End Kernel Architecture Search in Neural Networks
Apr 18, 2023The demands for higher performance and accuracy in neural networks (NNs) never end. Existing tensor compilation and Neural Architecture Search (NAS) techniques orthogonally optimize the two goals but actually share many similarities in their concrete strategies. We exploit such opportunities by combining the two into one and make a case for Kernel Architecture Search (KAS). KAS reviews NAS from a system perspective and zooms into a more fine-grained level to generate neural kernels with both high performance and good accuracy. To demonstrate the potential of KAS, we build an end-to-end framework, Canvas, to find high-quality kernels as convolution replacements. Canvas samples from a rich set of fine-grained primitives to stochastically and iteratively construct new kernels and evaluate them according to user-specified constraints. Canvas supports freely adjustable tensor dimension sizes inside the kernel and uses two levels of solvers to satisfy structural legality and fully utilize model budgets. The evaluation shows that by replacing standard convolutions with generated new kernels in common NNs, Canvas achieves average 1.5x speedups compared to the previous state-of-the-art with acceptable accuracy loss and search efficiency. Canvas verifies the practicability of KAS by rediscovering many manually designed kernels in the past and producing new structures that may inspire future machine learning innovations. For source code and implementation, we open-sourced Canvas at https://github.com/tsinghua-ideal/Canvas.