 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM*: A Modular, Extensible, Serving System for Multimodal Models
Jun 10, 2026We are entering a new era of composite model architectures that integrate diverse components such as vision encoders, language backbones, diffusion and flow heads, audio codecs, action generators, and world-model predictors. Such architectures underpin a broad class of multimodal models, including unified multimodal models, omni models, speech-language models, vision-language-action policies, and world models. However, existing model serving frameworks were built on narrow assumptions about model structure, making them ill-suited to accommodate this new architectural diversity. Here we present M*, a universal serving system for efficient serving of composite AI models. M* represents models as dataflow graphs, processing requests spanning diverse modalities and tasks as traversals over these graphs. The core insight is a modular abstraction that supports arbitrary composition of model components, flexible placement onto a physical cluster, and model-agnostic optimizations within a distributed runtime. We call this abstraction the Walk Graph and show how it can concisely capture composite models from a broad range of families. We instantiate M* on representative models and find that it achieves, on average, 20% lower end-to-end latency than vLLM-Omni for text-to-image workloads on BAGEL, while delivering up to 2.9x lower real-time factor and 2.7x higher throughput for text-to-speech workloads on Qwen3-Omni. M* also outperforms the V-JEPA 2-AC rollout baseline for robotic planning by up to 12.5x. Thus, our work paves the road towards more efficient serving of complex models with minimal developer effort.
Streaming Tensor Program: A streaming abstraction for dynamic parallelism
Nov 11, 2025
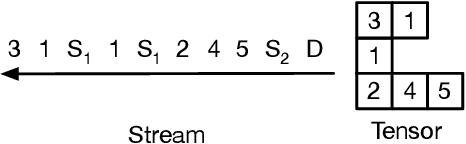

Dynamic behaviors are becoming prevalent in many tensor applications. In machine learning, for example, the input tensors are dynamically shaped or ragged, and data-dependent control flow is widely used in many models. However, the limited expressiveness of prior programming abstractions for spatial dataflow accelerators forces the dynamic behaviors to be implemented statically or lacks the visibility for performance-critical decisions. To address these challenges, we present the Streaming Tensor Program (STeP), a new streaming abstraction that enables dynamic tensor workloads to run efficiently on spatial dataflow accelerators. STeP introduces flexible routing operators, an explicit memory hierarchy, and symbolic shape semantics that expose dynamic data rates and tensor dimensions. These capabilities unlock new optimizations-dynamic tiling, dynamic parallelization, and configuration time-multiplexing-that adapt to dynamic behaviors while preserving dataflow efficiency. Using a cycle-approximate simulator on representative LLM layers with real-world traces, dynamic tiling reduces on-chip memory requirement by 2.18x, dynamic parallelization improves latency by 1.5x, and configuration time-multiplexing improves compute utilization by 2.57x over implementations available in prior abstractions.
FuseFlow: A Fusion-Centric Compilation Framework for Sparse Deep Learning on Streaming Dataflow
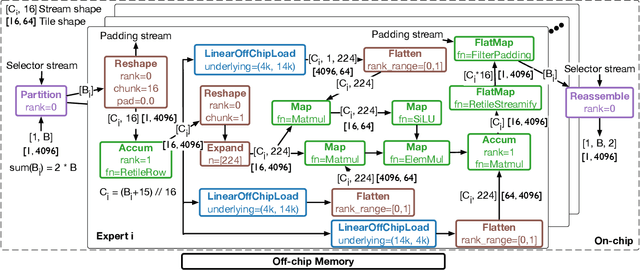
Nov 06, 2025As deep learning models scale, sparse computation and specialized dataflow hardware have emerged as powerful solutions to address efficiency. We propose FuseFlow, a compiler that converts sparse machine learning models written in PyTorch to fused sparse dataflow graphs for reconfigurable dataflow architectures (RDAs). FuseFlow is the first compiler to support general cross-expression fusion of sparse operations. In addition to fusion across kernels (expressions), FuseFlow also supports optimizations like parallelization, dataflow ordering, and sparsity blocking. It targets a cycle-accurate dataflow simulator for microarchitectural analysis of fusion strategies. We use FuseFlow for design-space exploration across four real-world machine learning applications with sparsity, showing that full fusion (entire cross-expression fusion across all computation in an end-to-end model) is not always optimal for sparse models-fusion granularity depends on the model itself. FuseFlow also provides a heuristic to identify and prune suboptimal configurations. Using Fuseflow, we achieve performance improvements, including a ~2.7x speedup over an unfused baseline for GPT-3 with BigBird block-sparse attention.
Ember: A Compiler for Efficient Embedding Operations on Decoupled Access-Execute Architectures
Apr 14, 2025Irregular embedding lookups are a critical bottleneck in recommender models, sparse large language models, and graph learning models. In this paper, we first demonstrate that, by offloading these lookups to specialized access units, Decoupled Access-Execute (DAE) processors achieve 2.6$\times$ higher performance and 6.4$\times$ higher performance/watt than GPUs on end-to-end models. Then, we propose the Ember compiler for automatically generating optimized DAE code from PyTorch and TensorFlow. Conversely from other DAE compilers, Ember features multiple intermediate representations specifically designed for different optimization levels. In this way, Ember can implement all optimizations to match the performance of hand-written code, unlocking the full potential of DAE architectures at scale.
Adaptive Self-improvement LLM Agentic System for ML Library Development
Feb 04, 2025ML libraries, often written in architecture-specific programming languages (ASPLs) that target domain-specific architectures, are key to efficient ML systems. However, writing these high-performance ML libraries is challenging because it requires expert knowledge of ML algorithms and the ASPL. Large language models (LLMs), on the other hand, have shown general coding capabilities. However, challenges remain when using LLMs for generating ML libraries using ASPLs because 1) this task is complicated even for experienced human programmers and 2) there are limited code examples because of the esoteric and evolving nature of ASPLs. Therefore, LLMs need complex reasoning with limited data in order to complete this task. To address these challenges, we introduce an adaptive self-improvement agentic system. In order to evaluate the effectiveness of our system, we construct a benchmark of a typical ML library and generate ASPL code with both open and closed-source LLMs on this benchmark. Our results show improvements of up to $3.9\times$ over a baseline single LLM.
BaCO: A Fast and Portable Bayesian Compiler Optimization Framework
Dec 01, 2022

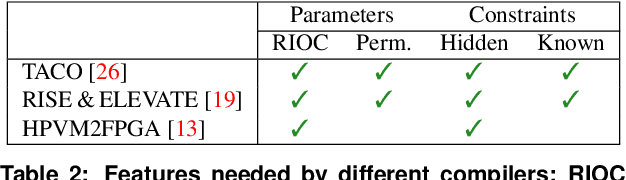
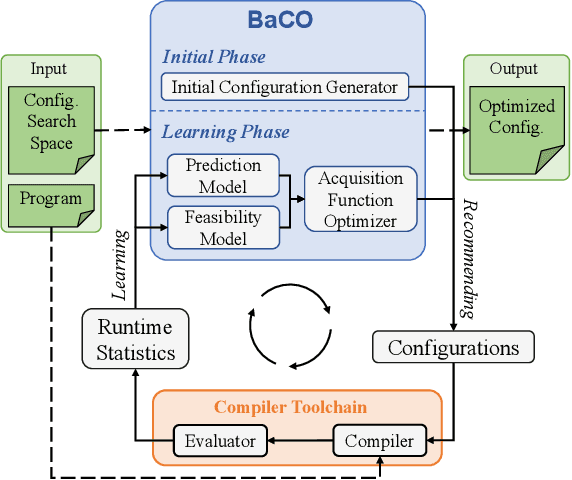
We introduce the Bayesian Compiler Optimization framework (BaCO), a general purpose autotuner for modern compilers targeting CPUs, GPUs, and FPGAs. BaCO provides the flexibility needed to handle the requirements of modern autotuning tasks. Particularly, it deals with permutation, ordered, and continuous parameter types along with both known and unknown parameter constraints. To reason about these parameter types and efficiently deliver high-quality code, BaCO uses Bayesian optimization algorithms specialized towards the autotuning domain. We demonstrate BaCO's effectiveness on three modern compiler systems: TACO, RISE & ELEVATE, and HPVM2FPGA for CPUs, GPUs, and FPGAs respectively. For these domains, BaCO outperforms current state-of-the-art autotuners by delivering on average 1.39x-1.89x faster code with a tiny search budget, and BaCO is able to reach expert-level performance 2.89x-8.77x faster.