 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Software Pipelining and Warp Specialization for Tensor Core GPUs
Dec 19, 2025


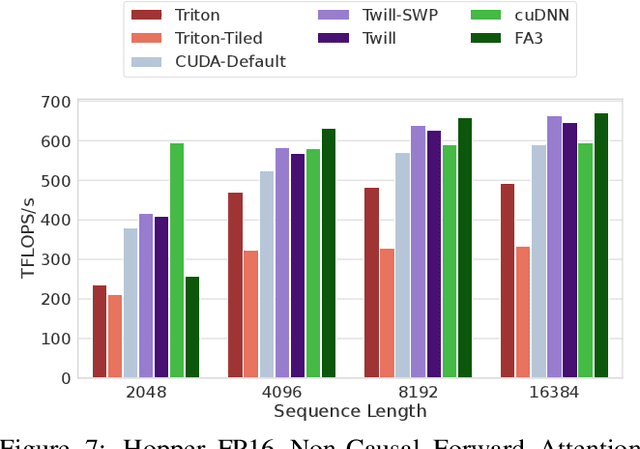
GPU architectures have continued to grow in complexity, with recent incarnations introducing increasingly powerful fixed-function units for matrix multiplication and data movement to accompany highly parallel general-purpose cores. To fully leverage these machines, software must use sophisticated schedules that maximally utilize all hardware resources. Since realizing such schedules is complex, both programmers and compilers routinely employ program transformations, such as software pipelining (SWP) and warp specialization (WS), to do so in practice. However, determining how best to use SWP and WS in combination is a challenging problem that is currently handled through a mix of brittle compilation heuristics and fallible human intuition, with little insight into the space of solutions. To remedy this situation, we introduce a novel formulation of SWP and WS as a joint optimization problem that can be solved holistically by off-the-shelf constraint solvers. We reify our approach in Twill, the first system that automatically derives optimal SWP and WS schedules for a large class of iterative programs. Twill is heuristic-free, easily extensible to new GPU architectures, and guaranteed to produce optimal schedules. We show that Twill can rediscover, and thereby prove optimal, the SWP and WS schedules manually developed by experts for Flash Attention on both the NVIDIA Hopper and Blackwell GPU architectures.
FuseFlow: A Fusion-Centric Compilation Framework for Sparse Deep Learning on Streaming Dataflow
Nov 06, 2025As deep learning models scale, sparse computation and specialized dataflow hardware have emerged as powerful solutions to address efficiency. We propose FuseFlow, a compiler that converts sparse machine learning models written in PyTorch to fused sparse dataflow graphs for reconfigurable dataflow architectures (RDAs). FuseFlow is the first compiler to support general cross-expression fusion of sparse operations. In addition to fusion across kernels (expressions), FuseFlow also supports optimizations like parallelization, dataflow ordering, and sparsity blocking. It targets a cycle-accurate dataflow simulator for microarchitectural analysis of fusion strategies. We use FuseFlow for design-space exploration across four real-world machine learning applications with sparsity, showing that full fusion (entire cross-expression fusion across all computation in an end-to-end model) is not always optimal for sparse models-fusion granularity depends on the model itself. FuseFlow also provides a heuristic to identify and prune suboptimal configurations. Using Fuseflow, we achieve performance improvements, including a ~2.7x speedup over an unfused baseline for GPT-3 with BigBird block-sparse attention.
Ember: A Compiler for Efficient Embedding Operations on Decoupled Access-Execute Architectures
Apr 14, 2025Irregular embedding lookups are a critical bottleneck in recommender models, sparse large language models, and graph learning models. In this paper, we first demonstrate that, by offloading these lookups to specialized access units, Decoupled Access-Execute (DAE) processors achieve 2.6$\times$ higher performance and 6.4$\times$ higher performance/watt than GPUs on end-to-end models. Then, we propose the Ember compiler for automatically generating optimized DAE code from PyTorch and TensorFlow. Conversely from other DAE compilers, Ember features multiple intermediate representations specifically designed for different optimization levels. In this way, Ember can implement all optimizations to match the performance of hand-written code, unlocking the full potential of DAE architectures at scale.
Scorch: A Library for Sparse Deep Learning
May 27, 2024



The rapid growth in the size of deep learning models strains the capabilities of traditional dense computation paradigms. Leveraging sparse computation has become increasingly popular for training and deploying large-scale models, but existing deep learning frameworks lack extensive support for sparse operations. To bridge this gap, we introduce Scorch, a library that seamlessly integrates efficient sparse tensor computation into the PyTorch ecosystem, with an initial focus on inference workloads on CPUs. Scorch provides a flexible and intuitive interface for sparse tensors, supporting diverse sparse data structures. Scorch introduces a compiler stack that automates key optimizations, including automatic loop ordering, tiling, and format inference. Combined with a runtime that adapts its execution to both dense and sparse data, Scorch delivers substantial speedups over hand-written PyTorch Sparse (torch.sparse) operations without sacrificing usability. More importantly, Scorch enables efficient computation of complex sparse operations that lack hand-optimized PyTorch implementations. This flexibility is crucial for exploring novel sparse architectures. We demonstrate Scorch's ease of use and performance gains on diverse deep learning models across multiple domains. With only minimal code changes, Scorch achieves 1.05-5.78x speedups over PyTorch Sparse on end-to-end tasks. Scorch's seamless integration and performance gains make it a valuable addition to the PyTorch ecosystem. We believe Scorch will enable wider exploration of sparsity as a tool for scaling deep learning and inform the development of other sparse libraries.
BaCO: A Fast and Portable Bayesian Compiler Optimization Framework
Dec 01, 2022

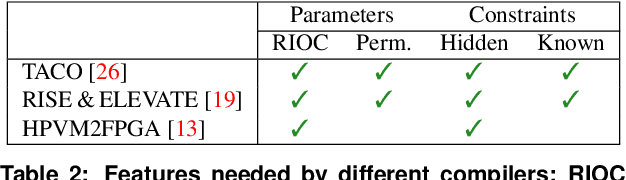
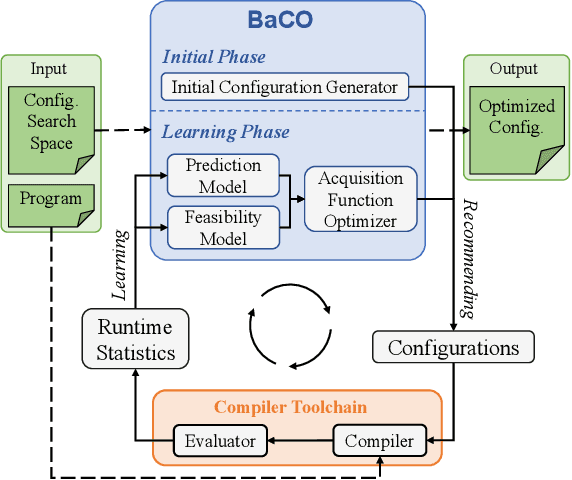
We introduce the Bayesian Compiler Optimization framework (BaCO), a general purpose autotuner for modern compilers targeting CPUs, GPUs, and FPGAs. BaCO provides the flexibility needed to handle the requirements of modern autotuning tasks. Particularly, it deals with permutation, ordered, and continuous parameter types along with both known and unknown parameter constraints. To reason about these parameter types and efficiently deliver high-quality code, BaCO uses Bayesian optimization algorithms specialized towards the autotuning domain. We demonstrate BaCO's effectiveness on three modern compiler systems: TACO, RISE & ELEVATE, and HPVM2FPGA for CPUs, GPUs, and FPGAs respectively. For these domains, BaCO outperforms current state-of-the-art autotuners by delivering on average 1.39x-1.89x faster code with a tiny search budget, and BaCO is able to reach expert-level performance 2.89x-8.77x faster.