 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensorBench: Benchmarking Coding Agents on a Compiler-Based Tensor Framework
Jun 04, 2026Repository-level coding benchmarks face a trade-off between task difficulty and evaluation reliability: tasks that challenge frontier models often involve large codebases with incomplete test coverage, while human review does not scale. We introduce TensorBench, a benchmark of 199 feature-addition and refactoring tasks on an open-source compiler-based tensor framework that extends PyTorch with first-class support for dense and sparse tensors. Tasks cover new sparse formats, dense optimization passes, IR transformations, scheduler changes, runtime components, and high-level numerical operators. TensorBench grades each run by applying the agent's patch and running the framework's test suite, which includes the pre-existing randomized regression tests and any tests the agent adds. For feature-addition tasks, a pass means that the patched repository preserves the tested pre-existing behavior and satisfies the agent-added checks for the requested feature. We evaluate seven coding agents spanning three frontier model families and one open-weight model. Pass rates under this criterion range from $64.8\%$ for the strongest agent to $22.1\%$ for the weakest. Agents pass different subsets of tasks: pairwise Cohen's $κ$ ranges from $-0.07$ to $0.43$, with $κ= 0.05$ for the two strongest agents.
Scorch: A Library for Sparse Deep Learning
May 27, 2024



The rapid growth in the size of deep learning models strains the capabilities of traditional dense computation paradigms. Leveraging sparse computation has become increasingly popular for training and deploying large-scale models, but existing deep learning frameworks lack extensive support for sparse operations. To bridge this gap, we introduce Scorch, a library that seamlessly integrates efficient sparse tensor computation into the PyTorch ecosystem, with an initial focus on inference workloads on CPUs. Scorch provides a flexible and intuitive interface for sparse tensors, supporting diverse sparse data structures. Scorch introduces a compiler stack that automates key optimizations, including automatic loop ordering, tiling, and format inference. Combined with a runtime that adapts its execution to both dense and sparse data, Scorch delivers substantial speedups over hand-written PyTorch Sparse (torch.sparse) operations without sacrificing usability. More importantly, Scorch enables efficient computation of complex sparse operations that lack hand-optimized PyTorch implementations. This flexibility is crucial for exploring novel sparse architectures. We demonstrate Scorch's ease of use and performance gains on diverse deep learning models across multiple domains. With only minimal code changes, Scorch achieves 1.05-5.78x speedups over PyTorch Sparse on end-to-end tasks. Scorch's seamless integration and performance gains make it a valuable addition to the PyTorch ecosystem. We believe Scorch will enable wider exploration of sparsity as a tool for scaling deep learning and inform the development of other sparse libraries.
Holistic Evaluation of Language Models
Nov 16, 2022



Language models (LMs) are becoming the foundation for almost all major language technologies, but their capabilities, limitations, and risks are not well understood. We present Holistic Evaluation of Language Models (HELM) to improve the transparency of language models. First, we taxonomize the vast space of potential scenarios (i.e. use cases) and metrics (i.e. desiderata) that are of interest for LMs. Then we select a broad subset based on coverage and feasibility, noting what's missing or underrepresented (e.g. question answering for neglected English dialects, metrics for trustworthiness). Second, we adopt a multi-metric approach: We measure 7 metrics (accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency) for each of 16 core scenarios when possible (87.5% of the time). This ensures metrics beyond accuracy don't fall to the wayside, and that trade-offs are clearly exposed. We also perform 7 targeted evaluations, based on 26 targeted scenarios, to analyze specific aspects (e.g. reasoning, disinformation). Third, we conduct a large-scale evaluation of 30 prominent language models (spanning open, limited-access, and closed models) on all 42 scenarios, 21 of which were not previously used in mainstream LM evaluation. Prior to HELM, models on average were evaluated on just 17.9% of the core HELM scenarios, with some prominent models not sharing a single scenario in common. We improve this to 96.0%: now all 30 models have been densely benchmarked on the same core scenarios and metrics under standardized conditions. Our evaluation surfaces 25 top-level findings. For full transparency, we release all raw model prompts and completions publicly for further analysis, as well as a general modular toolkit. We intend for HELM to be a living benchmark for the community, continuously updated with new scenarios, metrics, and models.
FORML: Learning to Reweight Data for Fairness
Feb 03, 2022

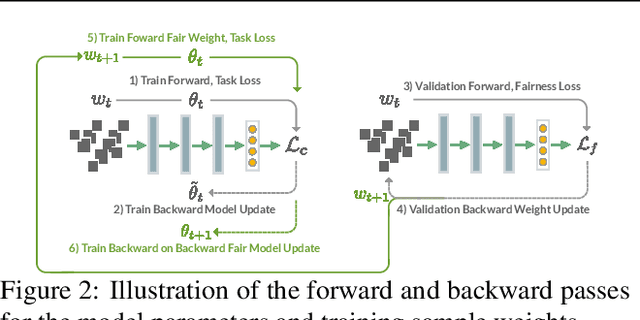
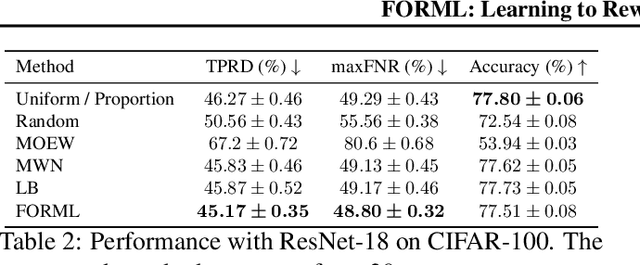
Deployed machine learning models are evaluated by multiple metrics beyond accuracy, such as fairness and robustness. However, such models are typically trained to minimize the average loss for a single metric, which is typically a proxy for accuracy. Training to optimize a single metric leaves these models prone to fairness violations, especially when the population of sub-groups in the training data are imbalanced. This work addresses the challenge of jointly optimizing fairness and predictive performance in the multi-class classification setting by introducing Fairness Optimized Reweighting via Meta-Learning (FORML), a training algorithm that balances fairness constraints and accuracy by jointly optimizing training sample weights and a neural network's parameters. The approach increases fairness by learning to weight each training datum's contribution to the loss according to its impact on reducing fairness violations, balancing the contributions from both over- and under-represented sub-groups. We empirically validate FORML on a range of benchmark and real-world classification datasets and show that our approach improves equality of opportunity fairness criteria over existing state-of-the-art reweighting methods by approximately 1% on image classification tasks and by approximately 5% on a face attribute prediction task. This improvement is achieved without pre-processing data or post-processing model outputs, without learning an additional weighting function, and while maintaining accuracy on the original predictive metric.