 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Classifiers Avoid Shortcut Solutions
Dec 31, 2025Discriminative approaches to classification often learn shortcuts that hold in-distribution but fail even under minor distribution shift. This failure mode stems from an overreliance on features that are spuriously correlated with the label. We show that generative classifiers, which use class-conditional generative models, can avoid this issue by modeling all features, both core and spurious, instead of mainly spurious ones. These generative classifiers are simple to train, avoiding the need for specialized augmentations, strong regularization, extra hyperparameters, or knowledge of the specific spurious correlations to avoid. We find that diffusion-based and autoregressive generative classifiers achieve state-of-the-art performance on five standard image and text distribution shift benchmarks and reduce the impact of spurious correlations in realistic applications, such as medical or satellite datasets. Finally, we carefully analyze a Gaussian toy setting to understand the inductive biases of generative classifiers, as well as the data properties that determine when generative classifiers outperform discriminative ones.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Language Models Prefer What They Know: Relative Confidence Estimation via Confidence Preferences
Feb 03, 2025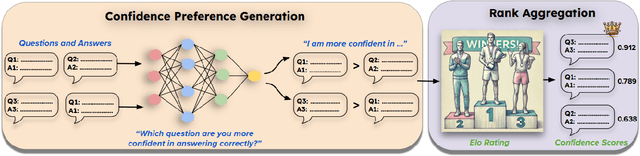
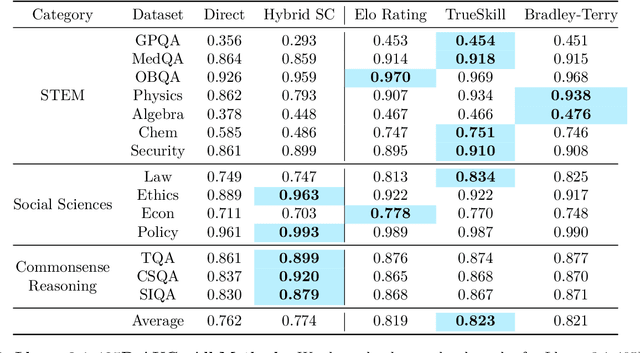


Language models (LMs) should provide reliable confidence estimates to help users detect mistakes in their outputs and defer to human experts when necessary. Asking a language model to assess its confidence ("Score your confidence from 0-1.") is a natural way of evaluating its uncertainty. However, models struggle to provide absolute assessments of confidence (i.e. judging confidence in answering a question independent of other questions) and the coarse-grained scores they produce are not useful for evaluating the correctness of their answers. We propose relative confidence estimation, where we match up questions against each other and ask the model to make relative judgments of confidence ("Which question are you more confident in answering correctly?"). Treating each question as a "player" in a series of matchups against other questions and the model's preferences as match outcomes, we can use rank aggregation methods like Elo rating and Bradley-Terry to translate the model's confidence preferences into confidence scores. We evaluate relative confidence estimation against absolute confidence estimation and self-consistency confidence methods on five state-of-the-art LMs -- GPT-4, GPT-4o, Gemini 1.5 Pro, Claude 3.5 Sonnet, and Llama 3.1 405B -- across 14 challenging STEM, social science, and commonsense reasoning question answering tasks. Our results demonstrate that relative confidence estimation consistently provides more reliable confidence scores than absolute confidence estimation, with average gains of 3.5% in selective classification AUC over direct absolute confidence estimation methods and 1.7% over self-consistency approaches across all models and datasets.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Evolving Domain Adaptation of Pretrained Language Models for Text Classification
Nov 16, 2023



Adapting pre-trained language models (PLMs) for time-series text classification amidst evolving domain shifts (EDS) is critical for maintaining accuracy in applications like stance detection. This study benchmarks the effectiveness of evolving domain adaptation (EDA) strategies, notably self-training, domain-adversarial training, and domain-adaptive pretraining, with a focus on an incremental self-training method. Our analysis across various datasets reveals that this incremental method excels at adapting PLMs to EDS, outperforming traditional domain adaptation techniques. These findings highlight the importance of continually updating PLMs to ensure their effectiveness in real-world applications, paving the way for future research into PLM robustness against the natural temporal evolution of language.
Llamas Know What GPTs Don't Show: Surrogate Models for Confidence Estimation
Nov 15, 2023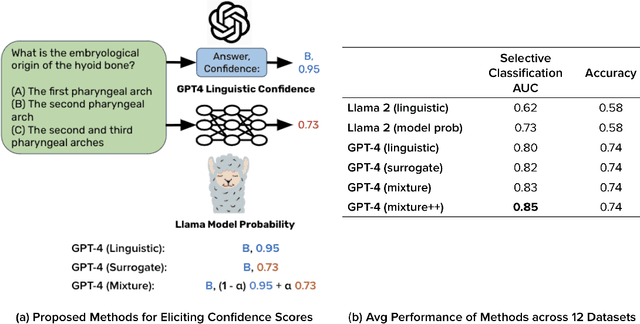
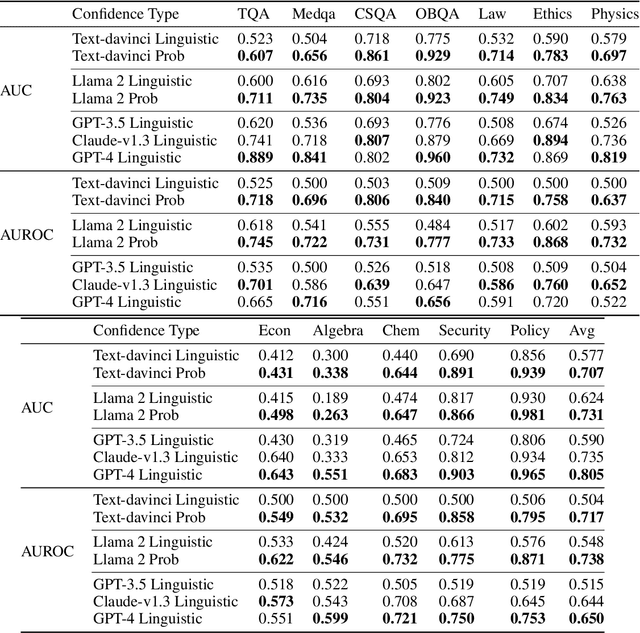

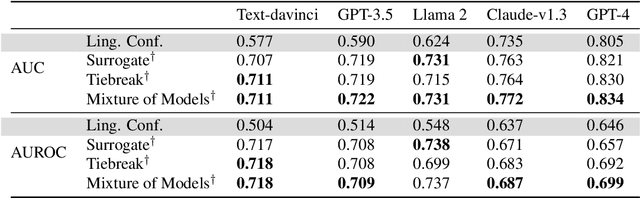
To maintain user trust, large language models (LLMs) should signal low confidence on examples where they are incorrect, instead of misleading the user. The standard approach of estimating confidence is to use the softmax probabilities of these models, but as of November 2023, state-of-the-art LLMs such as GPT-4 and Claude-v1.3 do not provide access to these probabilities. We first study eliciting confidence linguistically -- asking an LLM for its confidence in its answer -- which performs reasonably (80.5% AUC on GPT-4 averaged across 12 question-answering datasets -- 7% above a random baseline) but leaves room for improvement. We then explore using a surrogate confidence model -- using a model where we do have probabilities to evaluate the original model's confidence in a given question. Surprisingly, even though these probabilities come from a different and often weaker model, this method leads to higher AUC than linguistic confidences on 9 out of 12 datasets. Our best method composing linguistic confidences and surrogate model probabilities gives state-of-the-art confidence estimates on all 12 datasets (84.6% average AUC on GPT-4).
Conservative Prediction via Data-Driven Confidence Minimization
Jun 08, 2023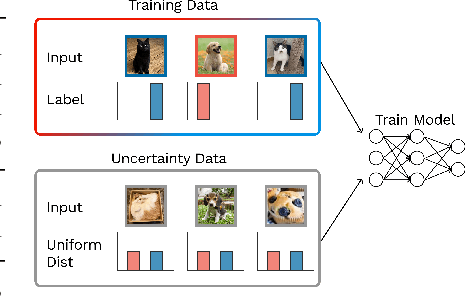
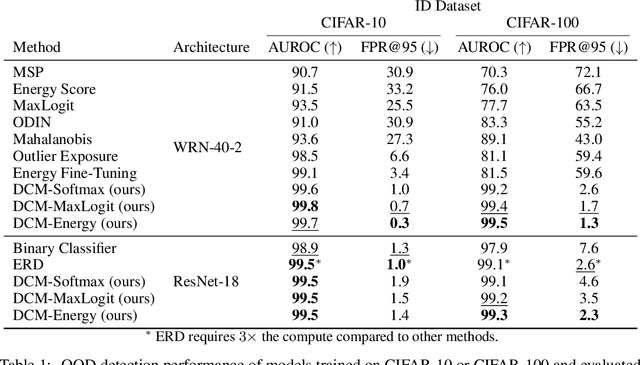
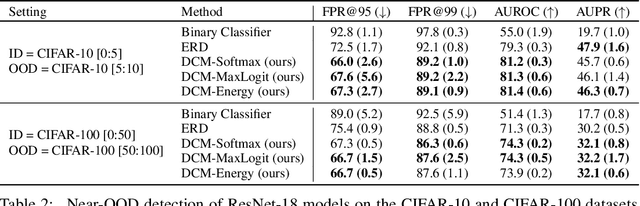
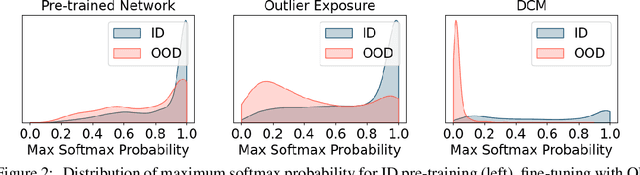
Errors of machine learning models are costly, especially in safety-critical domains such as healthcare, where such mistakes can prevent the deployment of machine learning altogether. In these settings, conservative models -- models which can defer to human judgment when they are likely to make an error -- may offer a solution. However, detecting unusual or difficult examples is notably challenging, as it is impossible to anticipate all potential inputs at test time. To address this issue, prior work has proposed to minimize the model's confidence on an auxiliary pseudo-OOD dataset. We theoretically analyze the effect of confidence minimization and show that the choice of auxiliary dataset is critical. Specifically, if the auxiliary dataset includes samples from the OOD region of interest, confidence minimization provably separates ID and OOD inputs by predictive confidence. Taking inspiration from this result, we present data-driven confidence minimization (DCM), which minimizes confidence on an uncertainty dataset containing examples that the model is likely to misclassify at test time. Our experiments show that DCM consistently outperforms state-of-the-art OOD detection methods on 8 ID-OOD dataset pairs, reducing FPR (at TPR 95%) by 6.3% and 58.1% on CIFAR-10 and CIFAR-100, and outperforms existing selective classification approaches on 4 datasets in conditions of distribution shift.
Improving Representational Continuity via Continued Pretraining
Feb 26, 2023



We consider the continual representation learning setting: sequentially pretrain a model $M'$ on tasks $T_1, \ldots, T_T$, and then adapt $M'$ on a small amount of data from each task $T_i$ to check if it has forgotten information from old tasks. Under a kNN adaptation protocol, prior work shows that continual learning methods improve forgetting over naive training (SGD). In reality, practitioners do not use kNN classifiers -- they use the adaptation method that works best (e.g., fine-tuning) -- here, we find that strong continual learning baselines do worse than naive training. Interestingly, we find that a method from the transfer learning community (LP-FT) outperforms naive training and the other continual learning methods. Even with standard kNN evaluation protocols, LP-FT performs comparably with strong continual learning methods (while being simpler and requiring less memory) on three standard benchmarks: sequential CIFAR-10, CIFAR-100, and TinyImageNet. LP-FT also reduces forgetting in a real world satellite remote sensing dataset (FMoW), and a variant of LP-FT gets state-of-the-art accuracies on an NLP continual learning benchmark.
Finetune like you pretrain: Improved finetuning of zero-shot vision models
Dec 01, 2022


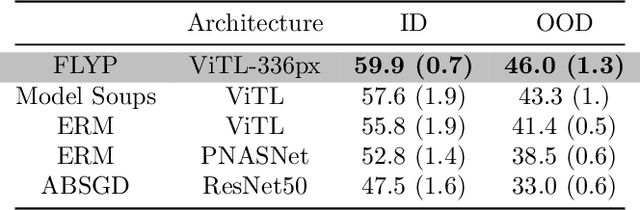
Finetuning image-text models such as CLIP achieves state-of-the-art accuracies on a variety of benchmarks. However, recent works like WiseFT (Wortsman et al., 2021) and LP-FT (Kumar et al., 2022) have shown that even subtle differences in the finetuning process can lead to surprisingly large differences in the final performance, both for in-distribution (ID) and out-of-distribution (OOD) data. In this work, we show that a natural and simple approach of mimicking contrastive pretraining consistently outperforms alternative finetuning approaches. Specifically, we cast downstream class labels as text prompts and continue optimizing the contrastive loss between image embeddings and class-descriptive prompt embeddings (contrastive finetuning). Our method consistently outperforms baselines across 7 distribution shifts, 6 transfer learning, and 3 few-shot learning benchmarks. On WILDS-iWILDCam, our proposed approach FLYP outperforms the top of the leaderboard by $2.3\%$ ID and $2.7\%$ OOD, giving the highest reported accuracy. Averaged across 7 OOD datasets (2 WILDS and 5 ImageNet associated shifts), FLYP gives gains of $4.2\%$ OOD over standard finetuning and outperforms the current state of the art (LP-FT) by more than $1\%$ both ID and OOD. Similarly, on 3 few-shot learning benchmarks, our approach gives gains up to $4.6\%$ over standard finetuning and $4.4\%$ over the state of the art. In total, these benchmarks establish contrastive finetuning as a simple, intuitive, and state-of-the-art approach for supervised finetuning of image-text models like CLIP. Code is available at https://github.com/locuslab/FLYP.