 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models Prefer What They Know: Relative Confidence Estimation via Confidence Preferences
Paper and Code
Feb 03, 2025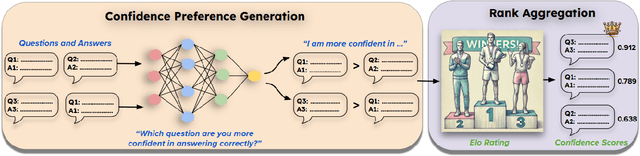
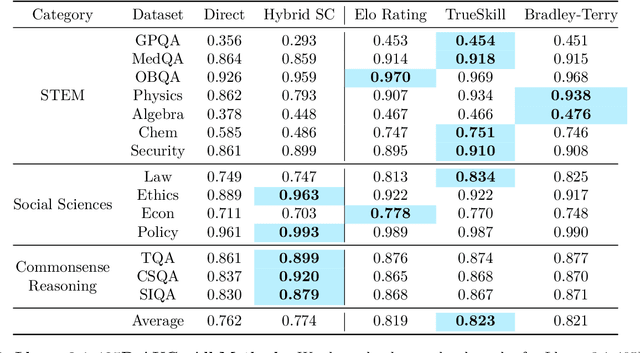


Language models (LMs) should provide reliable confidence estimates to help users detect mistakes in their outputs and defer to human experts when necessary. Asking a language model to assess its confidence ("Score your confidence from 0-1.") is a natural way of evaluating its uncertainty. However, models struggle to provide absolute assessments of confidence (i.e. judging confidence in answering a question independent of other questions) and the coarse-grained scores they produce are not useful for evaluating the correctness of their answers. We propose relative confidence estimation, where we match up questions against each other and ask the model to make relative judgments of confidence ("Which question are you more confident in answering correctly?"). Treating each question as a "player" in a series of matchups against other questions and the model's preferences as match outcomes, we can use rank aggregation methods like Elo rating and Bradley-Terry to translate the model's confidence preferences into confidence scores. We evaluate relative confidence estimation against absolute confidence estimation and self-consistency confidence methods on five state-of-the-art LMs -- GPT-4, GPT-4o, Gemini 1.5 Pro, Claude 3.5 Sonnet, and Llama 3.1 405B -- across 14 challenging STEM, social science, and commonsense reasoning question answering tasks. Our results demonstrate that relative confidence estimation consistently provides more reliable confidence scores than absolute confidence estimation, with average gains of 3.5% in selective classification AUC over direct absolute confidence estimation methods and 1.7% over self-consistency approaches across all models and datasets.