 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConservative Prediction via Data-Driven Confidence Minimization
Paper and Code
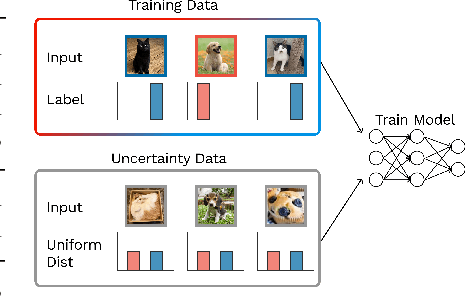
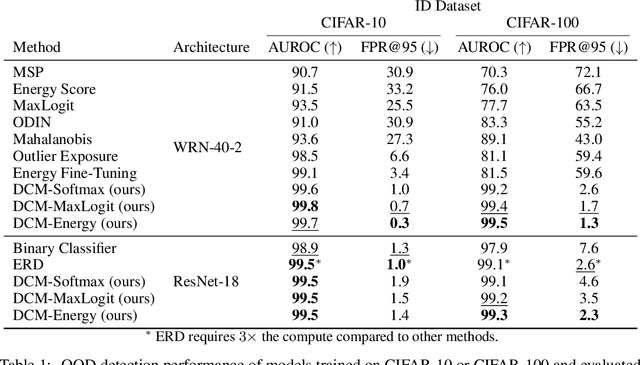
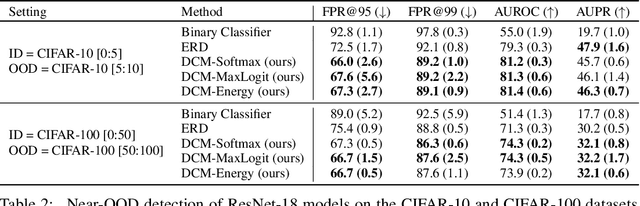
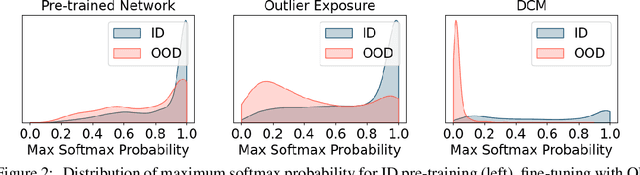
Errors of machine learning models are costly, especially in safety-critical domains such as healthcare, where such mistakes can prevent the deployment of machine learning altogether. In these settings, conservative models -- models which can defer to human judgment when they are likely to make an error -- may offer a solution. However, detecting unusual or difficult examples is notably challenging, as it is impossible to anticipate all potential inputs at test time. To address this issue, prior work has proposed to minimize the model's confidence on an auxiliary pseudo-OOD dataset. We theoretically analyze the effect of confidence minimization and show that the choice of auxiliary dataset is critical. Specifically, if the auxiliary dataset includes samples from the OOD region of interest, confidence minimization provably separates ID and OOD inputs by predictive confidence. Taking inspiration from this result, we present data-driven confidence minimization (DCM), which minimizes confidence on an uncertainty dataset containing examples that the model is likely to misclassify at test time. Our experiments show that DCM consistently outperforms state-of-the-art OOD detection methods on 8 ID-OOD dataset pairs, reducing FPR (at TPR 95%) by 6.3% and 58.1% on CIFAR-10 and CIFAR-100, and outperforms existing selective classification approaches on 4 datasets in conditions of distribution shift.