 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Safety Fails Before the Answer: Benchmarking Harmful Behavior Detection in Reasoning Chains
Apr 21, 2026Large reasoning models (LRMs) produce complex, multi-step reasoning traces, yet safety evaluation remains focused on final outputs, overlooking how harm emerges during reasoning. When jailbroken, harm does not appear instantaneously but unfolds through distinct behavioral steps such as suppressing refusal, rationalizing compliance, decomposing harmful tasks, and concealing risk. However, no existing benchmark captures this process at sentence-level granularity within reasoning traces -- a key step toward reliable safety monitoring, interventions, and systematic failure diagnosis. To address this gap, we introduce HarmThoughts, a benchmark for step-wise safety evaluation of reasoning traces. \ourdataset is built on our proposed harm taxonomy of 16 harmful reasoning behaviors across four functional groups that characterize how harm propagates rather than what harm is produced. The dataset consists of 56,931 sentences from 1,018 reasoning traces generated by four model families, each annotated with fine-grained sentence-level behavioral labels. Using HarmThoughts, we analyze harm propagation patterns across reasoning traces, identifying common behavioral trajectories and drift points where reasoning transitions from safe to unsafe. Finally, we systematically compare white-box and black-box detectors on the task of identifying harmful reasoning behaviours on HarmThoughts. Our results show that existing detectors struggle with fine-grained behavior detection in reasoning traces, particularly for nuanced categories within harm emergence and execution, highlighting a critical gap in process-level safety monitoring. HarmThoughts is available publicly at: https://huggingface.co/datasets/ishitakakkar-10/HarmThoughts
Shattered Compositionality: Counterintuitive Learning Dynamics of Transformers for Arithmetic
Jan 30, 2026Large language models (LLMs) often exhibit unexpected errors or unintended behavior, even at scale. While recent work reveals the discrepancy between LLMs and humans in skill compositions, the learning dynamics of skill compositions and the underlying cause of non-human behavior remain elusive. In this study, we investigate the mechanism of learning dynamics by training transformers on synthetic arithmetic tasks. Through extensive ablations and fine-grained diagnostic metrics, we discover that transformers do not reliably build skill compositions according to human-like sequential rules. Instead, they often acquire skills in reverse order or in parallel, which leads to unexpected mixing errors especially under distribution shifts--a phenomenon we refer to as shattered compositionality. To explain these behaviors, we provide evidence that correlational matching to the training data, rather than causal or procedural composition, shapes learning dynamics. We further show that shattered compositionality persists in modern LLMs and is not mitigated by pure model scaling or scratchpad-based reasoning. Our results reveal a fundamental mismatch between a model's learning behavior and desired skill compositions, with implications for reasoning reliability, out-of-distribution robustness, and alignment.
Journey Before Destination: On the importance of Visual Faithfulness in Slow Thinking
Dec 19, 2025Reasoning-augmented vision language models (VLMs) generate explicit chains of thought that promise greater capability and transparency but also introduce new failure modes: models may reach correct answers via visually unfaithful intermediate steps, or reason faithfully yet fail on the final prediction. Standard evaluations that only measure final-answer accuracy cannot distinguish these behaviors. We introduce the visual faithfulness of reasoning chains as a distinct evaluation dimension, focusing on whether the perception steps of a reasoning chain are grounded in the image. We propose a training- and reference-free framework that decomposes chains into perception versus reasoning steps and uses off-the-shelf VLM judges for step-level faithfulness, additionally verifying this approach through a human meta-evaluation. Building on this metric, we present a lightweight self-reflection procedure that detects and locally regenerates unfaithful perception steps without any training. Across multiple reasoning-trained VLMs and perception-heavy benchmarks, our method reduces Unfaithful Perception Rate while preserving final-answer accuracy, improving the reliability of multimodal reasoning.
DeTox: Toxic Subspace Projection for Model Editing
May 22, 2024



Recent alignment algorithms such as direct preference optimization (DPO) have been developed to improve the safety of large language models (LLMs) by training these models to match human behaviors exemplified by preference data. However, these methods are both computationally intensive and lacking in controllability and transparency, making them prone to jailbreaking and inhibiting their widespread use. Furthermore, these tuning-based methods require large-scale preference data for training and are susceptible to noisy preference data. In this paper, we introduce a tuning-free alignment alternative (DeTox) and demonstrate its effectiveness under the use case of toxicity reduction. Grounded on theory from factor analysis, DeTox is a sample-efficient model editing approach that identifies a toxic subspace in the model parameter space and reduces model toxicity by projecting away the detected subspace. The toxic sub-space is identified by extracting preference data embeddings from the language model, and removing non-toxic information from these embeddings. We show that DeTox is more sample-efficient than DPO, further showcasing greater robustness to noisy data. Finally, we establish both theoretical and empirical connections between DeTox and DPO, showing that DeTox can be interpreted as a denoised version of a single DPO step.
FEUDA: Frustratingly Easy Prompt Based Unsupervised Domain Adaptation
Jan 31, 2024



A major thread of unsupervised domain adaptation (UDA) methods uses unlabeled data from both source and target domains to learn domain-invariant representations for adaptation. However, these methods showcase certain limitations, encouraging the use of self-supervised learning through continued pre-training. The necessity of continued pre-training or learning domain-invariant representations is still unclear in the prompt-based classification framework, where an input example is modified by a template and then fed into a language model (LM) to generate a label string. To examine this new paradigm of UDA in the prompt-based setup, we propose a frustratingly easy UDA method (FEUDA) that trains an autoregressive LM on both unlabeled and labeled examples using two different instruction-tuning tasks. Specifically, the first task trains the LM on unlabeled texts from both domains via masked language modeling (MLM), and the other uses supervised instruction-tuning on source-labeled data for classification. We conduct extensive experiments on 24 real-world domain pairs to show the effectiveness of our method over strong domain-invariant learning methods. Our analysis sheds light on why masked language modeling improves target-domain classification performance in prompt-based UDA. We discover that MLM helps the model learn both semantic and background knowledge of a domain, which are both beneficial for downstream classification.
Evolving Domain Adaptation of Pretrained Language Models for Text Classification
Nov 16, 2023



Adapting pre-trained language models (PLMs) for time-series text classification amidst evolving domain shifts (EDS) is critical for maintaining accuracy in applications like stance detection. This study benchmarks the effectiveness of evolving domain adaptation (EDA) strategies, notably self-training, domain-adversarial training, and domain-adaptive pretraining, with a focus on an incremental self-training method. Our analysis across various datasets reveals that this incremental method excels at adapting PLMs to EDS, outperforming traditional domain adaptation techniques. These findings highlight the importance of continually updating PLMs to ensure their effectiveness in real-world applications, paving the way for future research into PLM robustness against the natural temporal evolution of language.
Is Fine-tuning Needed? Pre-trained Language Models Are Near Perfect for Out-of-Domain Detection
May 22, 2023Out-of-distribution (OOD) detection is a critical task for reliable predictions over text. Fine-tuning with pre-trained language models has been a de facto procedure to derive OOD detectors with respect to in-distribution (ID) data. Despite its common use, the understanding of the role of fine-tuning and its necessity for OOD detection is largely unexplored. In this paper, we raise the question: is fine-tuning necessary for OOD detection? We present a study investigating the efficacy of directly leveraging pre-trained language models for OOD detection, without any model fine-tuning on the ID data. We compare the approach with several competitive fine-tuning objectives, and offer new insights under various types of distributional shifts. Extensive evaluations on 8 diverse ID-OOD dataset pairs demonstrate near-perfect OOD detection performance (with 0% FPR95 in many cases), strongly outperforming its fine-tuned counterparts. We show that using distance-based detection methods, pre-trained language models are near-perfect OOD detectors when the distribution shift involves a domain change. Furthermore, we study the effect of fine-tuning on OOD detection and identify how to balance ID accuracy with OOD detection performance. Our code is publically available at https://github.com/Uppaal/lm-ood.
Long Document Summarization in a Low Resource Setting using Pretrained Language Models
Mar 01, 2021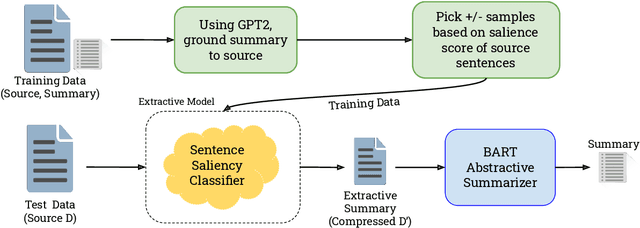
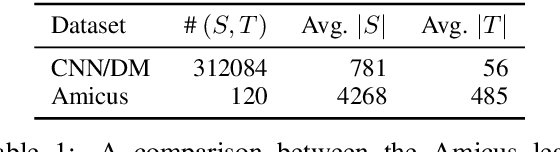


Abstractive summarization is the task of compressing a long document into a coherent short document while retaining salient information. Modern abstractive summarization methods are based on deep neural networks which often require large training datasets. Since collecting summarization datasets is an expensive and time-consuming task, practical industrial settings are usually low-resource. In this paper, we study a challenging low-resource setting of summarizing long legal briefs with an average source document length of 4268 words and only 120 available (document, summary) pairs. To account for data scarcity, we used a modern pretrained abstractive summarizer BART (Lewis et al., 2020), which only achieves 17.9 ROUGE-L as it struggles with long documents. We thus attempt to compress these long documents by identifying salient sentences in the source which best ground the summary, using a novel algorithm based on GPT-2 (Radford et al., 2019) language model perplexity scores, that operates within the low resource regime. On feeding the compressed documents to BART, we observe a 6.0 ROUGE-L improvement. Our method also beats several competitive salience detection baselines. Furthermore, the identified salient sentences tend to agree with an independent human labeling by domain experts.
Overcoming Practical Issues of Deep Active Learning and its Applications on Named Entity Recognition
Nov 17, 2019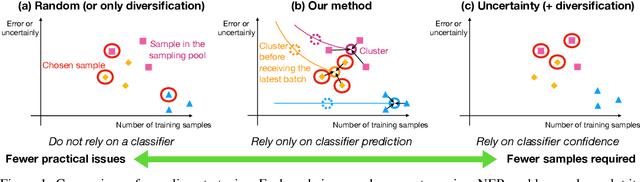
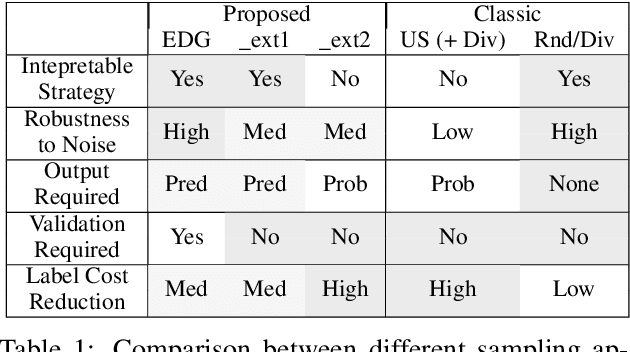
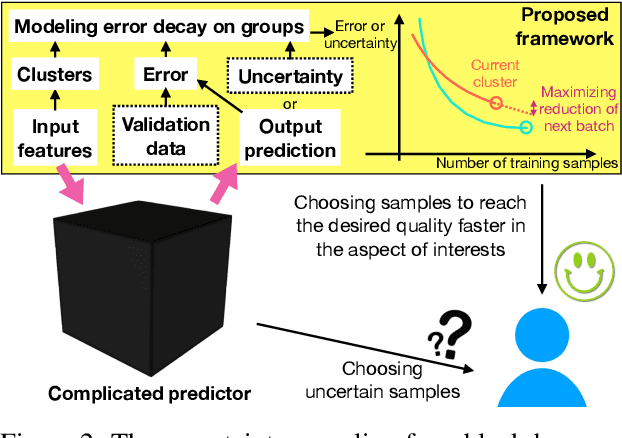
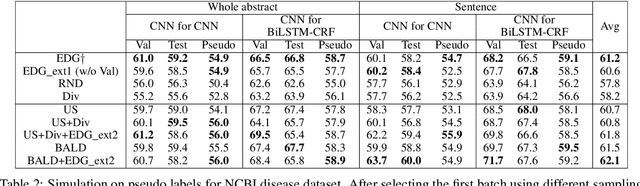
Existing deep active learning algorithms achieve impressive sampling efficiency on natural language processing tasks. However, they exhibit several weaknesses in practice, including (a) inability to use uncertainty sampling with black-box models, (b) lack of robustness to noise in labeling, (c) lack of transparency. In response, we propose a transparent batch active sampling framework by estimating the error decay curves of multiple feature-defined subsets of the data. Experiments on four named entity recognition (NER) tasks demonstrate that the proposed methods significantly outperform diversification-based methods for black-box NER taggers and can make the sampling process more robust to labeling noise when combined with uncertainty-based methods. Furthermore, the analysis of experimental results sheds light on the weaknesses of different active sampling strategies, and when traditional uncertainty-based or diversification-based methods can be expected to work well.
LRS-DAG: Low Resource Supervised Domain Adaptation with Generalization Across Domains
Sep 15, 2019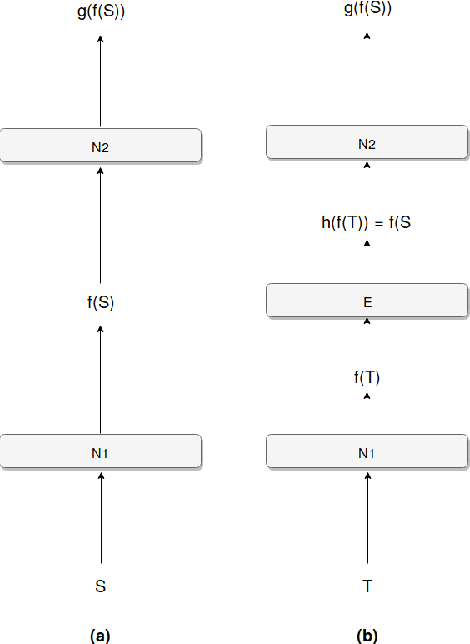
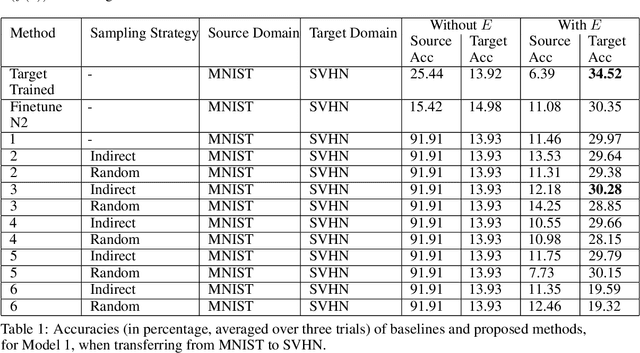

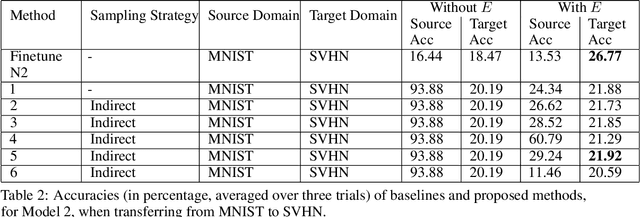
Current state of the art methods in Domain Adaptation follow adversarial approaches, making training a challenge. Other non-adversarial methods learn mappings between source and target domains, to achieve reasonable performance. However, even these methods do not focus a key aspect of maintaining performance on the source domain, even after optimizing over the target domain. Additionally, there exist very few methods in low resource supervised domain adaptation. This work proposes a method, LRS-DAG, that aims to solve these current issues in the field. By adding a set of "encoder layers" which map the target domain to the source, and can be removed when dealing directly with the source data, the model learns to perform optimally on both domains. LRS-DAG is unique in the sense that a new algorithm for low resource domain adaptation, which maintains performance over the source, with a new metric for learning mappings has been introduced.