 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Regularized Distributionally Robust Markov Decision Processes with Linear Function Approximation
Oct 16, 2025Decision-making under distribution shift is a central challenge in reinforcement learning (RL), where training and deployment environments differ. We study this problem through the lens of robust Markov decision processes (RMDPs), which optimize performance against adversarial transition dynamics. Our focus is the online setting, where the agent has only limited interaction with the environment, making sample efficiency and exploration especially critical. Policy optimization, despite its success in standard RL, remains theoretically and empirically underexplored in robust RL. To bridge this gap, we propose \textbf{D}istributionally \textbf{R}obust \textbf{R}egularized \textbf{P}olicy \textbf{O}ptimization algorithm (DR-RPO), a model-free online policy optimization method that learns robust policies with sublinear regret. To enable tractable optimization within the softmax policy class, DR-RPO incorporates reference-policy regularization, yielding RMDP variants that are doubly constrained in both transitions and policies. To scale to large state-action spaces, we adopt the $d$-rectangular linear MDP formulation and combine linear function approximation with an upper confidence bonus for optimistic exploration. We provide theoretical guarantees showing that policy optimization can achieve polynomial suboptimality bounds and sample efficiency in robust RL, matching the performance of value-based approaches. Finally, empirical results across diverse domains corroborate our theory and demonstrate the robustness of DR-RPO.
Scalable Signal Temporal Logic Guided Reinforcement Learning via Value Function Space Optimization
Aug 04, 2024



The integration of reinforcement learning (RL) and formal methods has emerged as a promising framework for solving long-horizon planning problems. Conventional approaches typically involve abstraction of the state and action spaces and manually created labeling functions or predicates. However, the efficiency of these approaches deteriorates as the tasks become increasingly complex, which results in exponential growth in the size of labeling functions or predicates. To address these issues, we propose a scalable model-based RL framework, called VFSTL, which schedules pre-trained skills to follow unseen STL specifications without using hand-crafted predicates. Given a set of value functions obtained by goal-conditioned RL, we formulate an optimization problem to maximize the robustness value of Signal Temporal Logic (STL) defined specifications, which is computed using value functions as predicates. To further reduce the computation burden, we abstract the environment state space into the value function space (VFS). Then the optimization problem is solved by Model-Based Reinforcement Learning. Simulation results show that STL with value functions as predicates approximates the ground truth robustness and the planning in VFS directly achieves unseen specifications using data from sensors.
DeTox: Toxic Subspace Projection for Model Editing
May 22, 2024



Recent alignment algorithms such as direct preference optimization (DPO) have been developed to improve the safety of large language models (LLMs) by training these models to match human behaviors exemplified by preference data. However, these methods are both computationally intensive and lacking in controllability and transparency, making them prone to jailbreaking and inhibiting their widespread use. Furthermore, these tuning-based methods require large-scale preference data for training and are susceptible to noisy preference data. In this paper, we introduce a tuning-free alignment alternative (DeTox) and demonstrate its effectiveness under the use case of toxicity reduction. Grounded on theory from factor analysis, DeTox is a sample-efficient model editing approach that identifies a toxic subspace in the model parameter space and reduces model toxicity by projecting away the detected subspace. The toxic sub-space is identified by extracting preference data embeddings from the language model, and removing non-toxic information from these embeddings. We show that DeTox is more sample-efficient than DPO, further showcasing greater robustness to noisy data. Finally, we establish both theoretical and empirical connections between DeTox and DPO, showing that DeTox can be interpreted as a denoised version of a single DPO step.
From perception to control: an autonomous driving system for a formula student driverless car
Aug 31, 2019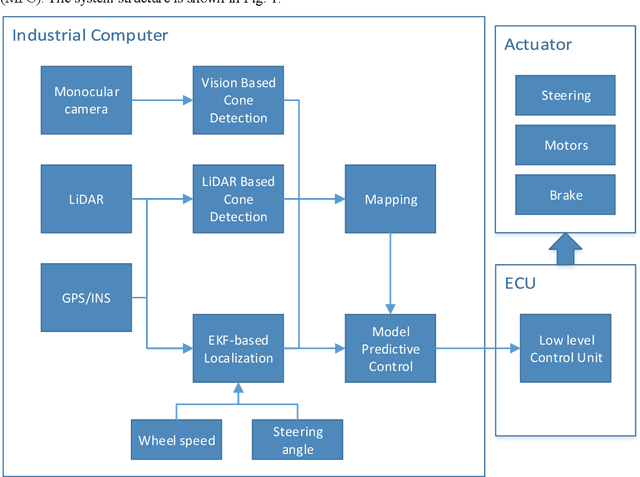
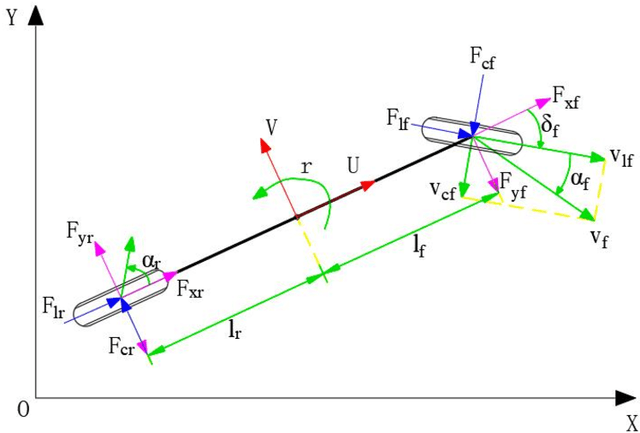
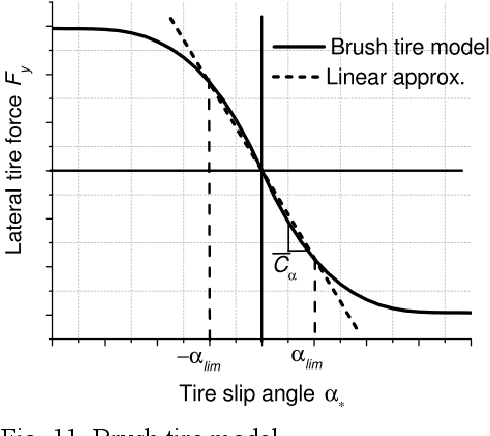

This paper introduces the autonomous system of the "Smart Shark II" which won the Formula Student Autonomous China (FSAC) Competition in 2018. In this competition, an autonomous racecar is required to complete autonomously two laps of unknown track. In this paper, the author presents the self-driving software structure of this racecar which ensure high vehicle speed and safety. The key components ensure a stable driving of the racecar, LiDAR-based and Vision-based cone detection provide a redundant perception; the EKF-based localization offers high accuracy and high frequency state estimation; perception results are accumulated in time and space by occupancy grid map. After getting the trajectory, a model predictive control algorithm is used to optimize in both longitudinal and lateral control of the racecar. Finally, the performance of an experiment based on real-world data is shown.