 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming Practical Issues of Deep Active Learning and its Applications on Named Entity Recognition
Paper and Code
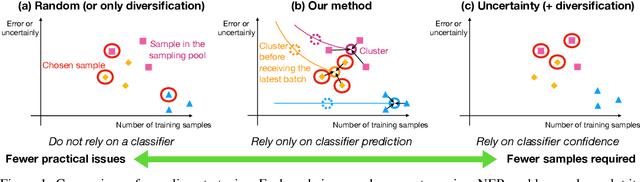
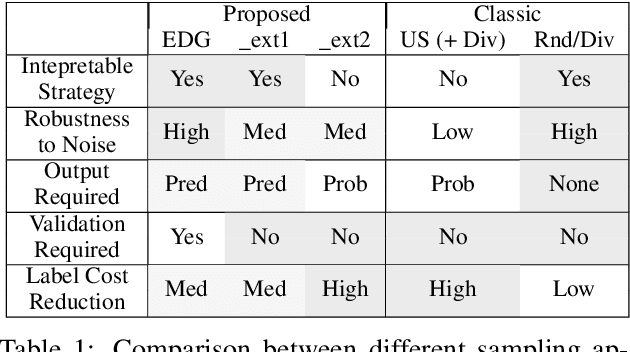
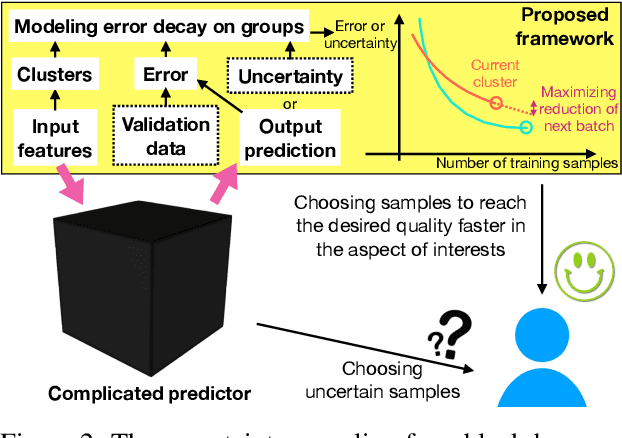
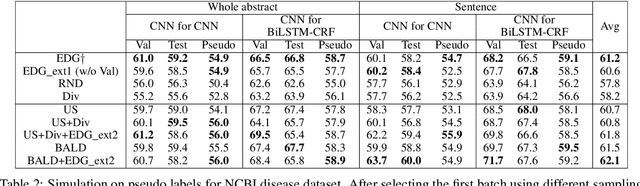
Existing deep active learning algorithms achieve impressive sampling efficiency on natural language processing tasks. However, they exhibit several weaknesses in practice, including (a) inability to use uncertainty sampling with black-box models, (b) lack of robustness to noise in labeling, (c) lack of transparency. In response, we propose a transparent batch active sampling framework by estimating the error decay curves of multiple feature-defined subsets of the data. Experiments on four named entity recognition (NER) tasks demonstrate that the proposed methods significantly outperform diversification-based methods for black-box NER taggers and can make the sampling process more robust to labeling noise when combined with uncertainty-based methods. Furthermore, the analysis of experimental results sheds light on the weaknesses of different active sampling strategies, and when traditional uncertainty-based or diversification-based methods can be expected to work well.