 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSigned Compression Progress on a Sealed Audit is Goodhart-Resistant
Jun 09, 2026Compression progress is a long-standing proposal for intrinsic motivation: reward an agent when its world model becomes better at predicting or compressing experience. The folk claim is that this reward is "credible" because it is paid only for learning. We make this precise and prove it. If intrinsic reward is the signed decrease of a fixed sealed-audit loss, r_t = E(theta_{t-1}) - E(theta_t), then cumulative reward telescopes exactly to endpoint audit improvement, so no policy can push reward up indefinitely while true audit performance stagnates or degrades. For finite audit panels the same result holds with a sharp false-positive budget: cumulative empirical reward is at most true audit improvement plus 2 Delta_n(F, delta), the uniform audit deviation of the model class. This is horizon-free: adaptivity over time costs nothing once the sealed panel uniformly controls the class. The theorem also identifies the failure modes: the guarantee disappears if progress is clipped, scored on the agent's own stream, exposed to a high-capacity model on a reusable panel, or applied to a neural class that makes Delta_n vacuous. We give a Lean 4 mechanization of the structural core (telescoping, the finite-audit bound, finite Gibbs, and the entropy floor) and an experiment suite on ARC-TGI grid-transformation generators with adaptive holdout attacks. Experiments confirm the theory: finite-audit deviation scales as n^{-0.527}; signed progress resists clip-farming, stream leakage, and noisy-TV curiosity; naive reusable audits are exploitable by black-box scalar feedback, while standard release defenses keep the attack below the 2 Delta_n threshold. Signed compression progress on a sealed audit is an accounting signal of genuine improvement.
Null Measurability at the Symmetrization Interface in VC Learning
Apr 27, 2026Recent work revisiting measurability in the fundamental theorem of statistical learning imposes Borel measurability of ghost-gap suprema. We show that, at the one-sided ghost-gap interface actually used by the standard symmetrization proof, this requirement is stronger than necessary. For any Borel-parameterized concept class on a Polish domain, the bad event "there exists a hypothesis whose ghost empirical error exceeds its training empirical error by at least ε/2" is analytic. By Choquet capacitability, it is therefore measurable in the completion of every finite Borel measure. We then construct a concept class whose bad event is null-measurable but not Borel, giving a strict separation from the Borel supremum condition. Finally, we prove closure under patching, fixed and countable interpolation, and fiber-product amalgamation, showing that the weaker regularity level is stable under natural concept-class constructors. In the realizable setting, where targets belong to the class and are measurable, these results weaken the measurability hypothesis needed by the symmetrization route from finite VC dimension to PAC learnability. The main results and the descriptive-set-theoretic infrastructure used by them are formalized in Lean 4.
Hybrid Deep Learning Framework for Classification of Kidney CT Images: Diagnosis of Stones, Cysts, and Tumors
Feb 05, 2025



Medical image classification is a vital research area that utilizes advanced computational techniques to improve disease diagnosis and treatment planning. Deep learning models, especially Convolutional Neural Networks (CNNs), have transformed this field by providing automated and precise analysis of complex medical images. This study introduces a hybrid deep learning model that integrates a pre-trained ResNet101 with a custom CNN to classify kidney CT images into four categories: normal, stone, cyst, and tumor. The proposed model leverages feature fusion to enhance classification accuracy, achieving 99.73% training accuracy and 100% testing accuracy. Using a dataset of 12,446 CT images and advanced feature mapping techniques, the hybrid CNN model outperforms standalone ResNet101. This architecture delivers a robust and efficient solution for automated kidney disease diagnosis, providing improved precision, recall, and reduced testing time, making it highly suitable for clinical applications.
TNNGen: Automated Design of Neuromorphic Sensory Processing Units for Time-Series Clustering
Dec 23, 2024



Temporal Neural Networks (TNNs), a special class of spiking neural networks, draw inspiration from the neocortex in utilizing spike-timings for information processing. Recent works proposed a microarchitecture framework and custom macro suite for designing highly energy-efficient application-specific TNNs. These recent works rely on manual hardware design, a labor-intensive and time-consuming process. Further, there is no open-source functional simulation framework for TNNs. This paper introduces TNNGen, a pioneering effort towards the automated design of TNNs from PyTorch software models to post-layout netlists. TNNGen comprises a novel PyTorch functional simulator (for TNN modeling and application exploration) coupled with a Python-based hardware generator (for PyTorch-to-RTL and RTL-to-Layout conversions). Seven representative TNN designs for time-series signal clustering across diverse sensory modalities are simulated and their post-layout hardware complexity and design runtimes are assessed to demonstrate the effectiveness of TNNGen. We also highlight TNNGen's ability to accurately forecast silicon metrics without running hardware process flow.
Evolving Domain Adaptation of Pretrained Language Models for Text Classification
Nov 16, 2023



Adapting pre-trained language models (PLMs) for time-series text classification amidst evolving domain shifts (EDS) is critical for maintaining accuracy in applications like stance detection. This study benchmarks the effectiveness of evolving domain adaptation (EDA) strategies, notably self-training, domain-adversarial training, and domain-adaptive pretraining, with a focus on an incremental self-training method. Our analysis across various datasets reveals that this incremental method excels at adapting PLMs to EDS, outperforming traditional domain adaptation techniques. These findings highlight the importance of continually updating PLMs to ensure their effectiveness in real-world applications, paving the way for future research into PLM robustness against the natural temporal evolution of language.
Generating Fact Checking Summaries for Web Claims
Oct 16, 2020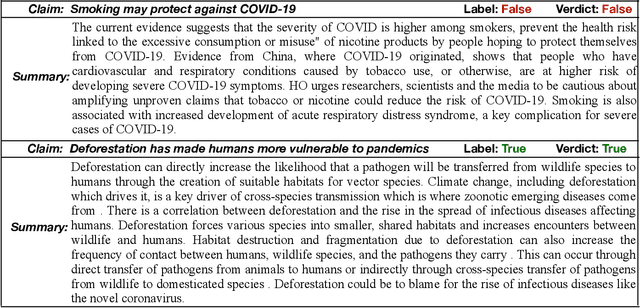
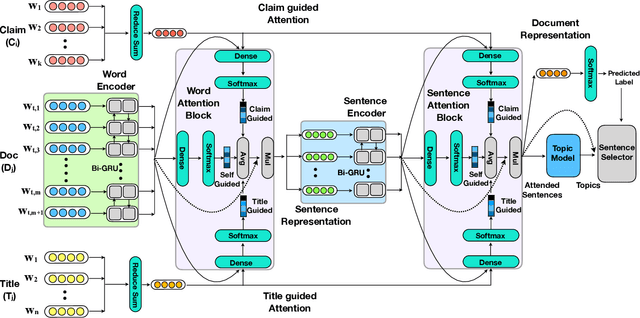
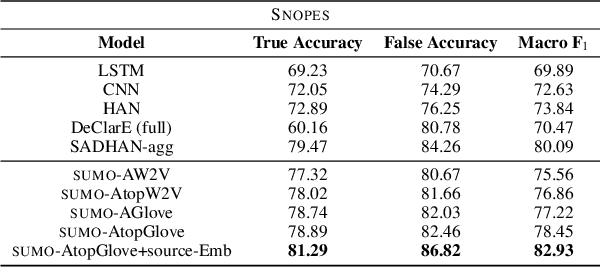
We present SUMO, a neural attention-based approach that learns to establish the correctness of textual claims based on evidence in the form of text documents (e.g., news articles or Web documents). SUMO further generates an extractive summary by presenting a diversified set of sentences from the documents that explain its decision on the correctness of the textual claim. Prior approaches to address the problem of fact checking and evidence extraction have relied on simple concatenation of claim and document word embeddings as an input to claim driven attention weight computation. This is done so as to extract salient words and sentences from the documents that help establish the correctness of the claim. However, this design of claim-driven attention does not capture the contextual information in documents properly. We improve on the prior art by using improved claim and title guided hierarchical attention to model effective contextual cues. We show the efficacy of our approach on datasets concerning political, healthcare, and environmental issues.
Event Search and Analytics: Detecting Events in Semantically Annotated Corpora for Search and Analytics
Mar 01, 2016
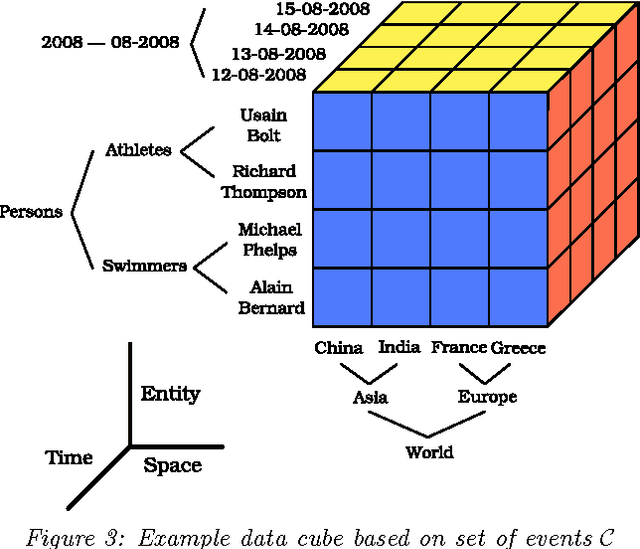
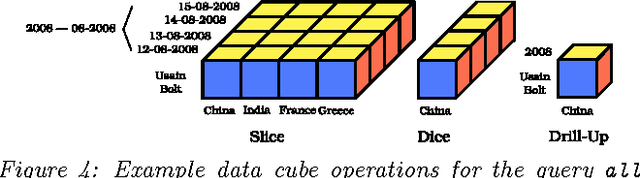
In this article, I present the questions that I seek to answer in my PhD research. I posit to analyze natural language text with the help of semantic annotations and mine important events for navigating large text corpora. Semantic annotations such as named entities, geographic locations, and temporal expressions can help us mine events from the given corpora. These events thus provide us with useful means to discover the locked knowledge in them. I pose three problems that can help unlock this knowledge vault in semantically annotated text corpora: i. identifying important events; ii. semantic search; and iii. event analytics.