 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploration of Unary Arithmetic-Based Matrix Multiply Units for Low Precision DL Accelerators
Jan 31, 2026General matrix multiplication (GEMM) is a fundamental operation in deep learning (DL). With DL moving increasingly toward low precision, recent works have proposed novel unary GEMM designs as an alternative to conventional binary GEMM hardware. A rigorous evaluation of recent unary and binary GEMM designs is needed to assess the potential of unary hardware for future DL compute. This paper focuses on unary GEMM designs for integer-based DL inference and performs a detailed evaluation of three latest unary design proposals, namely, uGEMM, tuGEMM and tubGEMM, by comparing them to a conventional binary GEMM. Rigorous post-synthesis evaluations beyond prior works are performed across varying bit-widths and matrix sizes to assess the designs' tradeoffs and determine optimal sweetspots. Further, we perform weight sparsity analysis across eight pretrained convolutional neural networks (CNNs) and the LLaMA2 large language model (LLM). In this work, we demonstrate how unary GEMM can be effectively used for energy-efficient compute in future edge AI accelerators.
Mugi: Value Level Parallelism For Efficient LLMs
Jan 15, 2026Value level parallelism (VLP) has been proposed to improve the efficiency of large-batch, low-precision general matrix multiply (GEMM) between symmetric activations and weights. In transformer based large language models (LLMs), there exist more sophisticated operations beyond activation-weight GEMM. In this paper, we explore how VLP benefits LLMs. First, we generalize VLP for nonlinear approximations, outperforming existing nonlinear approximations in end-to-end LLM accuracy, performance, and efficiency. Our VLP approximation follows a value-centric approach, where important values are assigned with greater accuracy. Second, we optimize VLP for small-batch GEMMs with asymmetric inputs efficiently, which leverages timely LLM optimizations, including weight-only quantization, key-value (KV) cache quantization, and group query attention. Finally, we design a new VLP architecture, Mugi, to encapsulate the innovations above and support full LLM workloads, while providing better performance, efficiency and sustainability. Our experimental results show that Mugi can offer significant improvements on throughput and energy efficiency, up to $45\times$ and $668\times$ for nonlinear softmax operations, and $2.07\times$ and $3.11\times$ for LLMs, and also decrease operational carbon for LLM operation by $1.45\times$ and embodied carbon by $1.48\times$.
Characterizing and Optimizing LLM Inference Workloads on CPU-GPU Coupled Architectures
Apr 16, 2025Large language model (LLM)-based inference workloads increasingly dominate data center costs and resource utilization. Therefore, understanding the inference workload characteristics on evolving CPU-GPU coupled architectures is crucial for optimization. This paper presents an in-depth analysis of LLM inference behavior on loosely-coupled (PCIe A100/H100) and closely-coupled (GH200) systems. We analyze performance dynamics using fine-grained operator-to-kernel trace analysis, facilitated by our novel profiler SKIP and metrics like Total Kernel Launch and Queuing Time (TKLQT). Results show that closely-coupled (CC) GH200 significantly outperforms loosely-coupled (LC) systems at large batch sizes, achieving 1.9x-2.7x faster prefill latency for Llama 3.2-1B. However, our analysis also reveals that GH200 remains CPU-bound up to 4x larger batch sizes than LC systems. In this extended CPU-bound region, we identify the performance characteristics of the Grace CPU as a key factor contributing to higher inference latency at low batch sizes on GH200. We demonstrate that TKLQT accurately identifies this CPU/GPU-bound transition point. Based on this analysis, we further show that kernel fusion offers significant potential to mitigate GH200's low-batch latency bottleneck by reducing kernel launch overhead. This detailed kernel-level characterization provides critical insights for optimizing diverse CPU-GPU coupling strategies. This work is an initial effort, and we plan to explore other major AI/DL workloads that demand different degrees of CPU-GPU heterogeneous architectures.
Tempus Core: Area-Power Efficient Temporal-Unary Convolution Core for Low-Precision Edge DLAs
Dec 25, 2024



The increasing complexity of deep neural networks (DNNs) poses significant challenges for edge inference deployment due to resource and power constraints of edge devices. Recent works on unary-based matrix multiplication hardware aim to leverage data sparsity and low-precision values to enhance hardware efficiency. However, the adoption and integration of such unary hardware into commercial deep learning accelerators (DLA) remain limited due to processing element (PE) array dataflow differences. This work presents Tempus Core, a convolution core with highly scalable unary-based PE array comprising of tub (temporal-unary-binary) multipliers that seamlessly integrates with the NVDLA (NVIDIA's open-source DLA for accelerating CNNs) while maintaining dataflow compliance and boosting hardware efficiency. Analysis across various datapath granularities shows that for INT8 precision in 45nm CMOS, Tempus Core's PE cell unit (PCU) yields 59.3% and 15.3% reductions in area and power consumption, respectively, over NVDLA's CMAC unit. Considering a 16x16 PE array in Tempus Core, area and power improves by 75% and 62%, respectively, while delivering 5x and 4x iso-area throughput improvements for INT8 and INT4 precisions. Post-place and route analysis of Tempus Core's PCU shows that the 16x4 PE array for INT4 precision in 45nm CMOS requires only 0.017 mm^2 die area and consumes only 6.2mW of total power. We demonstrate that area-power efficient unary-based hardware can be seamlessly integrated into conventional DLAs, paving the path for efficient unary hardware for edge AI inference.
TNNGen: Automated Design of Neuromorphic Sensory Processing Units for Time-Series Clustering
Dec 23, 2024



Temporal Neural Networks (TNNs), a special class of spiking neural networks, draw inspiration from the neocortex in utilizing spike-timings for information processing. Recent works proposed a microarchitecture framework and custom macro suite for designing highly energy-efficient application-specific TNNs. These recent works rely on manual hardware design, a labor-intensive and time-consuming process. Further, there is no open-source functional simulation framework for TNNs. This paper introduces TNNGen, a pioneering effort towards the automated design of TNNs from PyTorch software models to post-layout netlists. TNNGen comprises a novel PyTorch functional simulator (for TNN modeling and application exploration) coupled with a Python-based hardware generator (for PyTorch-to-RTL and RTL-to-Layout conversions). Seven representative TNN designs for time-series signal clustering across diverse sensory modalities are simulated and their post-layout hardware complexity and design runtimes are assessed to demonstrate the effectiveness of TNNGen. We also highlight TNNGen's ability to accurately forecast silicon metrics without running hardware process flow.
tuGEMM: Area-Power-Efficient Temporal Unary GEMM Architecture for Low-Precision Edge AI
Dec 23, 2024General matrix multiplication (GEMM) is a ubiquitous computing kernel/algorithm for data processing in diverse applications, including artificial intelligence (AI) and deep learning (DL). Recent shift towards edge computing has inspired GEMM architectures based on unary computing, which are predominantly stochastic and rate-coded systems. This paper proposes a novel GEMM architecture based on temporal-coding, called tuGEMM, that performs exact computation. We introduce two variants of tuGEMM, serial and parallel, with distinct area/power-latency trade-offs. Post-synthesis Power-Performance-Area (PPA) in 45 nm CMOS are reported for 2-bit, 4-bit, and 8-bit computations. The designs illustrate significant advantages in area-power efficiency over state-of-the-art stochastic unary systems especially at low precisions, e.g. incurring just 0.03 mm^2 and 9 mW for 4 bits, and 0.01 mm^2 and 4 mW for 2 bits. This makes tuGEMM ideal for power constrained mobile and edge devices performing always-on real-time sensory processing.
Towards a Design Framework for TNN-Based Neuromorphic Sensory Processing Units
May 27, 2022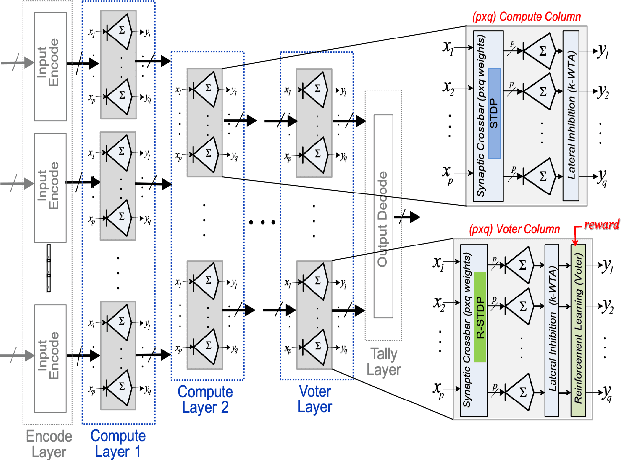

Temporal Neural Networks (TNNs) are spiking neural networks that exhibit brain-like sensory processing with high energy efficiency. This work presents the ongoing research towards developing a custom design framework for designing efficient application-specific TNN-based Neuromorphic Sensory Processing Units (NSPUs). This paper examines previous works on NSPU designs for UCR time-series clustering and MNIST image classification applications. Current ideas for a custom design framework and tools that enable efficient software-to-hardware design flow for rapid design space exploration of application-specific NSPUs while leveraging EDA tools to obtain post-layout netlist and power-performance-area (PPA) metrics are described. Future research directions are also outlined.
TNN7: A Custom Macro Suite for Implementing Highly Optimized Designs of Neuromorphic TNNs
May 16, 2022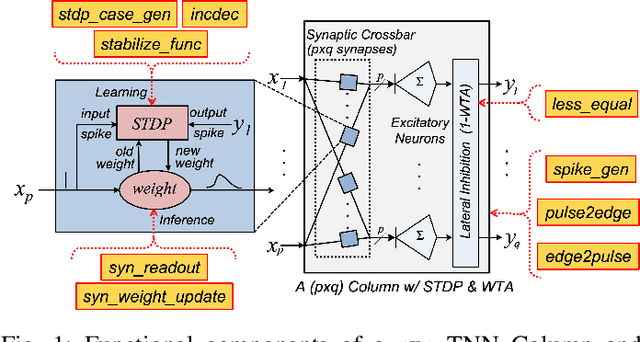
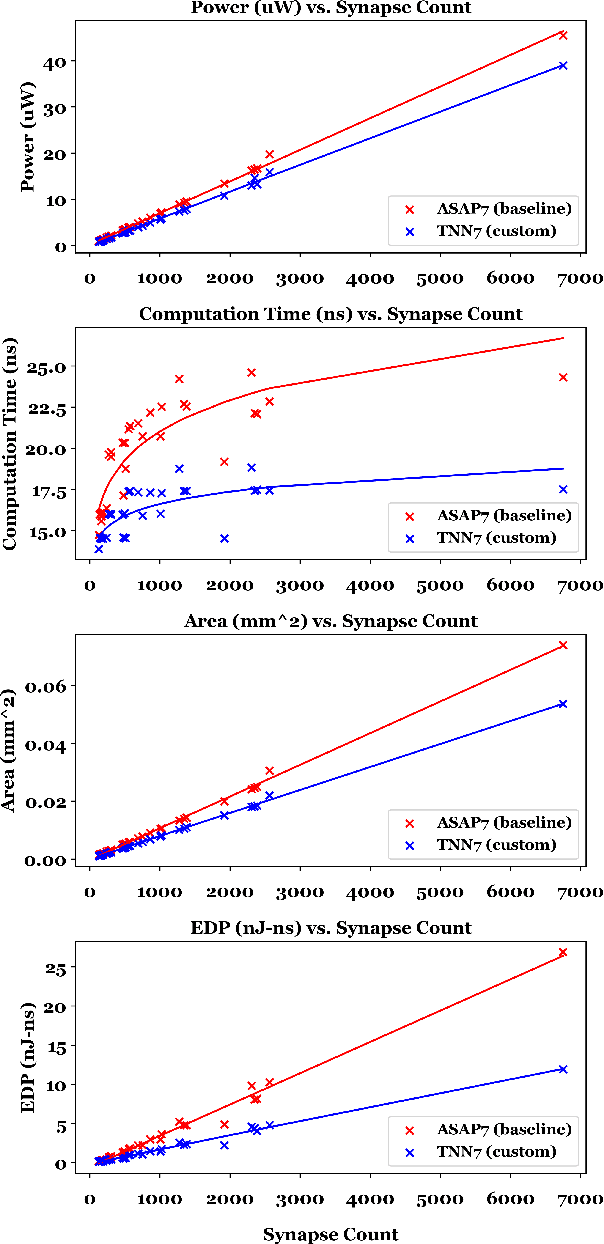
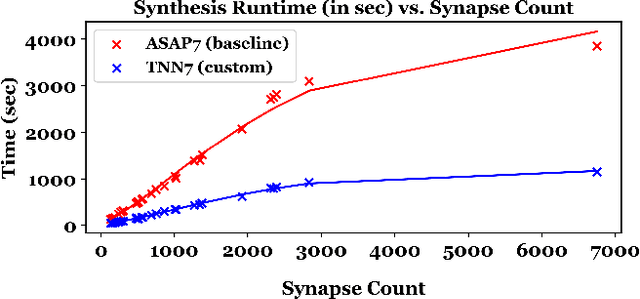
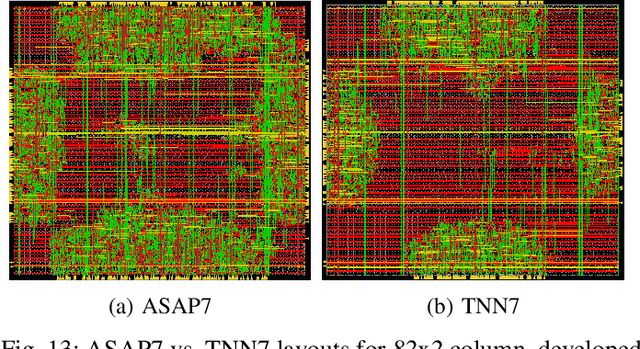
Temporal Neural Networks (TNNs), inspired from the mammalian neocortex, exhibit energy-efficient online sensory processing capabilities. Recent works have proposed a microarchitecture design framework for implementing TNNs and demonstrated competitive performance on vision and time-series applications. Building on them, this work proposes TNN7, a suite of nine highly optimized custom macros developed using a predictive 7nm Process Design Kit (PDK), to enhance the efficiency, modularity and flexibility of the TNN design framework. TNN prototypes for two applications are used for evaluation of TNN7. An unsupervised time-series clustering TNN delivering competitive performance can be implemented within 40 uW power and 0.05 mm^2 area, while a 4-layer TNN that achieves an MNIST error rate of 1% consumes only 18 mW and 24.63 mm^2. On average, the proposed macros reduce power, delay, area, and energy-delay product by 14%, 16%, 28%, and 45%, respectively. Furthermore, employing TNN7 significantly reduces the synthesis runtime of TNN designs (by more than 3x), allowing for highly-scaled TNN implementations to be realized.
A Custom 7nm CMOS Standard Cell Library for Implementing TNN-based Neuromorphic Processors
Dec 10, 2020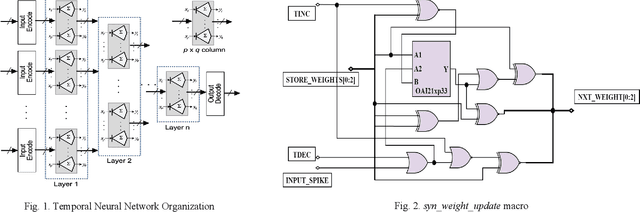
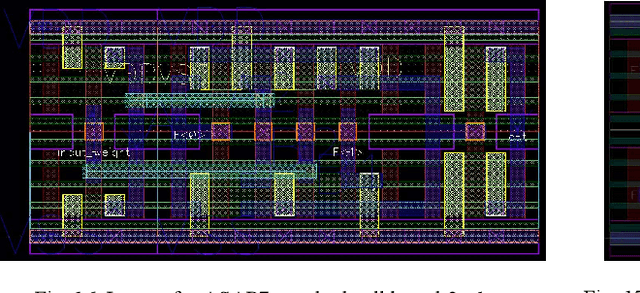
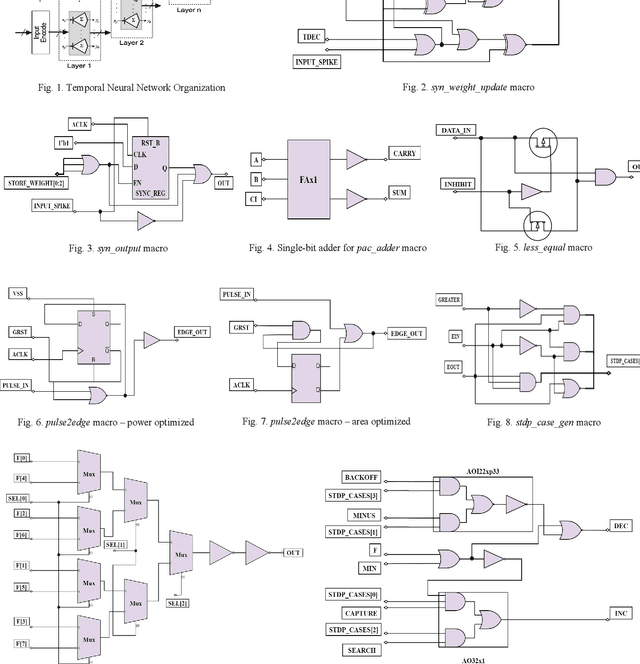
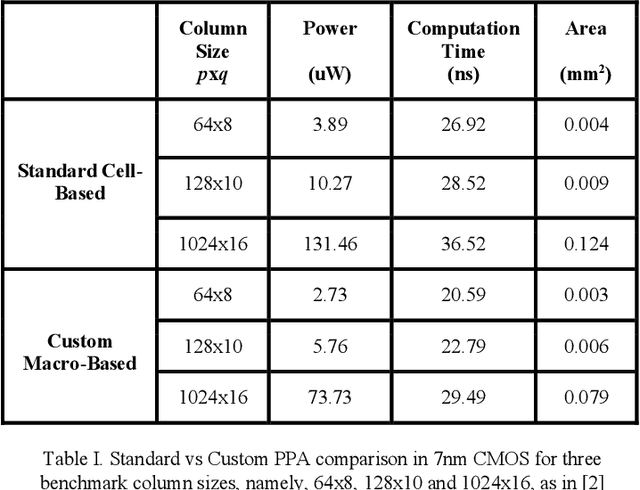
A set of highly-optimized custom macro extensions is developed for a 7nm CMOS cell library for implementing Temporal Neural Networks (TNNs) that can mimic brain-like sensory processing with extreme energy efficiency. A TNN prototype (13,750 neurons and 315,000 synapses) for MNIST requires only 1.56mm2 die area and consumes only 1.69mW.