 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoClaw: Evaluating AI Agents on Continuous Software Evolution
Mar 13, 2026With AI agents increasingly deployed as long-running systems, it becomes essential to autonomously construct and continuously evolve customized software to enable interaction within dynamic environments. Yet, existing benchmarks evaluate agents on isolated, one-off coding tasks, neglecting the temporal dependencies and technical debt inherent in real-world software evolution. To bridge this gap, we introduce DeepCommit, an agentic pipeline that reconstructs verifiable Milestone DAGs from noisy commit logs, where milestones are defined as semantically cohesive development goals. These executable sequences enable EvoClaw, a novel benchmark that requires agents to sustain system integrity and limit error accumulation, dimensions of long-term software evolution largely missing from current benchmarks. Our evaluation of 12 frontier models across 4 agent frameworks reveals a critical vulnerability: overall performance scores drop significantly from $>$80% on isolated tasks to at most 38% in continuous settings, exposing agents' profound struggle with long-term maintenance and error propagation.
ConsensusDrop: Fusing Visual and Cross-Modal Saliency for Efficient Vision Language Models
Feb 01, 2026Vision-Language Models (VLMs) are expensive because the LLM processes hundreds of largely redundant visual tokens. Existing token reduction methods typically exploit \textit{either} vision-encoder saliency (broad but query-agnostic) \textit{or} LLM cross-attention (query-aware but sparse and costly). We show that neither signal alone is sufficient: fusing them consistently improves performance compared to unimodal visual token selection (ranking). However, making such fusion practical is non-trivial: cross-modal saliency is usually only available \emph{inside} the LLM (too late for efficient pre-LLM pruning), and the two signals are inherently asymmetric, so naive fusion underutilizes their complementary strengths. We propose \textbf{ConsensusDrop}, a training-free framework that derives a \emph{consensus} ranking by reconciling vision encoder saliency with query-aware cross-attention, retaining the most informative tokens while compressing the remainder via encoder-guided token merging. Across LLaVA-1.5/NeXT, Video-LLaVA, and other open-source VLMs, ConsensusDrop consistently outperforms prior pruning methods under identical token budgets and delivers a stronger accuracy-efficiency Pareto frontier -- preserving near-baseline accuracy even at aggressive token reductions while reducing TTFT and KV cache footprint. Our code will be open-sourced.
Tempus Core: Area-Power Efficient Temporal-Unary Convolution Core for Low-Precision Edge DLAs
Dec 25, 2024



The increasing complexity of deep neural networks (DNNs) poses significant challenges for edge inference deployment due to resource and power constraints of edge devices. Recent works on unary-based matrix multiplication hardware aim to leverage data sparsity and low-precision values to enhance hardware efficiency. However, the adoption and integration of such unary hardware into commercial deep learning accelerators (DLA) remain limited due to processing element (PE) array dataflow differences. This work presents Tempus Core, a convolution core with highly scalable unary-based PE array comprising of tub (temporal-unary-binary) multipliers that seamlessly integrates with the NVDLA (NVIDIA's open-source DLA for accelerating CNNs) while maintaining dataflow compliance and boosting hardware efficiency. Analysis across various datapath granularities shows that for INT8 precision in 45nm CMOS, Tempus Core's PE cell unit (PCU) yields 59.3% and 15.3% reductions in area and power consumption, respectively, over NVDLA's CMAC unit. Considering a 16x16 PE array in Tempus Core, area and power improves by 75% and 62%, respectively, while delivering 5x and 4x iso-area throughput improvements for INT8 and INT4 precisions. Post-place and route analysis of Tempus Core's PCU shows that the 16x4 PE array for INT4 precision in 45nm CMOS requires only 0.017 mm^2 die area and consumes only 6.2mW of total power. We demonstrate that area-power efficient unary-based hardware can be seamlessly integrated into conventional DLAs, paving the path for efficient unary hardware for edge AI inference.
An Auto-tuning Framework for Autonomous Vehicles
Aug 14, 2018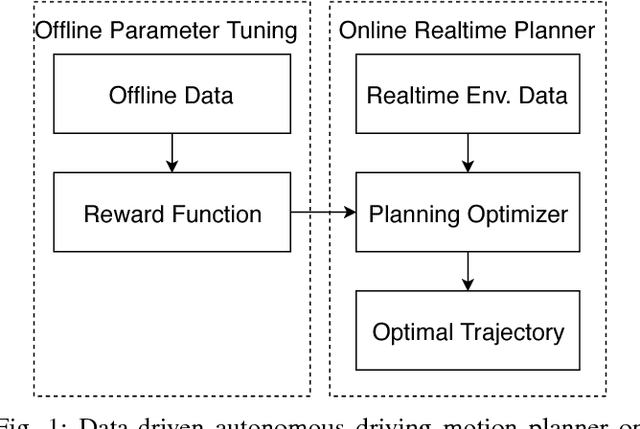
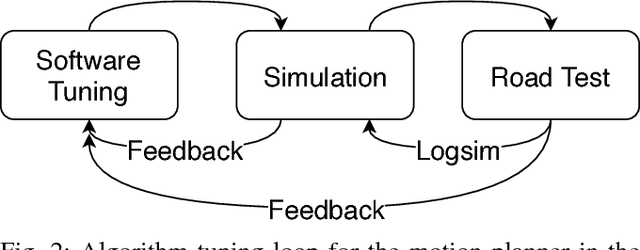
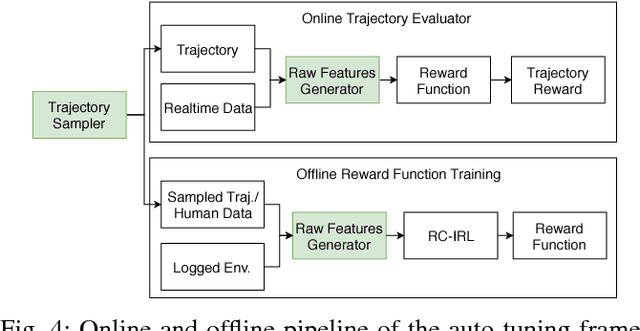
Many autonomous driving motion planners generate trajectories by optimizing a reward/cost functional. Designing and tuning a high-performance reward/cost functional for Level-4 autonomous driving vehicles with exposure to different driving conditions is challenging. Traditionally, reward/cost functional tuning involves substantial human effort and time spent on both simulations and road tests. As the scenario becomes more complicated, tuning to improve the motion planner performance becomes increasingly difficult. To systematically solve this issue, we develop a data-driven auto-tuning framework based on the Apollo autonomous driving framework. The framework includes a novel rank-based conditional inverse reinforcement learning algorithm, an offline training strategy and an automatic method of collecting and labeling data. Our auto-tuning framework has the following advantages that make it suitable for tuning an autonomous driving motion planner. First, compared to that of most inverse reinforcement learning algorithms, our algorithm training is efficient and capable of being applied to different scenarios. Second, the offline training strategy offers a safe way to adjust the parameters before public road testing. Third, the expert driving data and information about the surrounding environment are collected and automatically labeled, which considerably reduces the manual effort. Finally, the motion planner tuned by the framework is examined via both simulation and public road testing and is shown to achieve good performance.
Baidu Apollo EM Motion Planner
Jul 20, 2018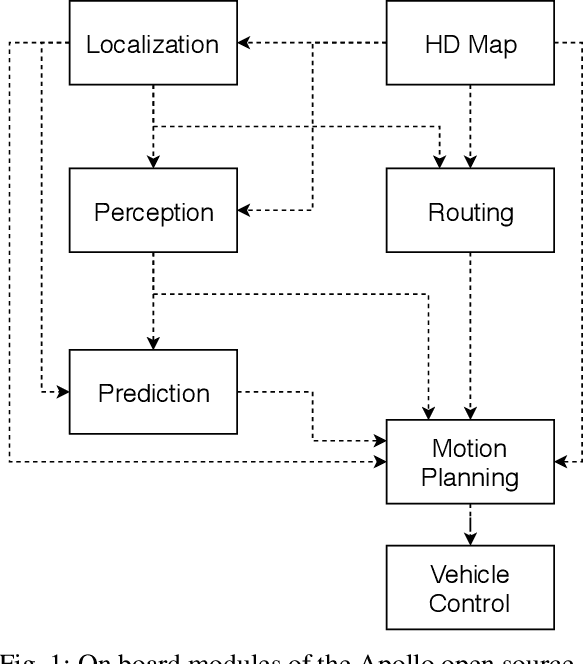
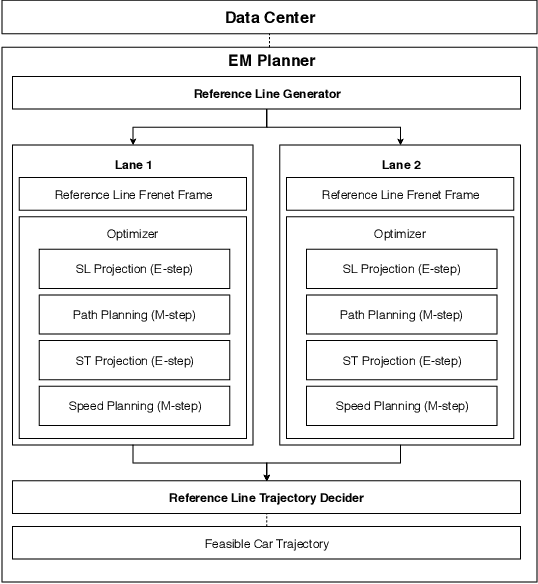
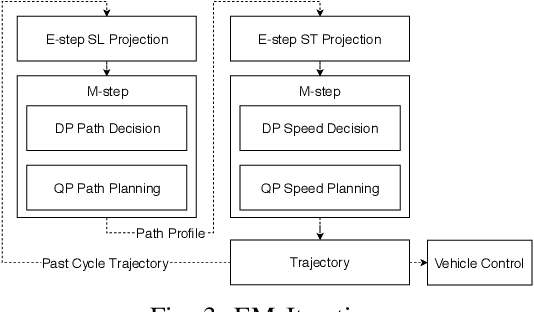

In this manuscript, we introduce a real-time motion planning system based on the Baidu Apollo (open source) autonomous driving platform. The developed system aims to address the industrial level-4 motion planning problem while considering safety, comfort and scalability. The system covers multilane and single-lane autonomous driving in a hierarchical manner: (1) The top layer of the system is a multilane strategy that handles lane-change scenarios by comparing lane-level trajectories computed in parallel. (2) Inside the lane-level trajectory generator, it iteratively solves path and speed optimization based on a Frenet frame. (3) For path and speed optimization, a combination of dynamic programming and spline-based quadratic programming is proposed to construct a scalable and easy-to-tune framework to handle traffic rules, obstacle decisions and smoothness simultaneously. The planner is scalable to both highway and lower-speed city driving scenarios. We also demonstrate the algorithm through scenario illustrations and on-road test results. The system described in this manuscript has been deployed to dozens of Baidu Apollo autonomous driving vehicles since Apollo v1.5 was announced in September 2017. As of May 16th, 2018, the system has been tested under 3,380 hours and approximately 68,000 kilometers (42,253 miles) of closed-loop autonomous driving under various urban scenarios. The algorithm described in this manuscript is available at https://github.com/ApolloAuto/apollo/tree/master/modules/planning.