 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElucidating Representation Degradation Problem in Diffusion Model Training
May 11, 2026Diffusion models have achieved remarkable success, yet their training remains inefficient due to a severe optimization bottleneck, which we term Representation Degradation. As noise levels increase, the outputs of the trained model exhibit progressive structural distortion, which can destabilize training and impair generation quality. Our analysis suggests that this instability is driven by mismatched target recoverability, which is associated with Neural Tangent Kernel (NTK) spectral weakening and effective low-rank behavior. To address this, we propose Elucidated Representation Diffusion (ERD), a plug-and-play framework that dynamically reallocates optimization effort according to effective recoverability. By stabilizing representation learning without external supervision, ERD accelerates convergence and achieves strong empirical performance across diffusion backbones.
LR-SGS: Robust LiDAR-Reflectance-Guided Salient Gaussian Splatting for Self-Driving Scene Reconstruction
Mar 13, 2026Recent 3D Gaussian Splatting (3DGS) methods have demonstrated the feasibility of self-driving scene reconstruction and novel view synthesis. However, most existing methods either rely solely on cameras or use LiDAR only for Gaussian initialization or depth supervision, while the rich scene information contained in point clouds, such as reflectance, and the complementarity between LiDAR and RGB have not been fully exploited, leading to degradation in challenging self-driving scenes, such as those with high ego-motion and complex lighting. To address these issues, we propose a robust and efficient LiDAR-reflectance-guided Salient Gaussian Splatting method (LR-SGS) for self-driving scenes, which introduces a structure-aware Salient Gaussian representation, initialized from geometric and reflectance feature points extracted from LiDAR and refined through a salient transform and improved density control to capture edge and planar structures. Furthermore, we calibrate LiDAR intensity into reflectance and attach it to each Gaussian as a lighting-invariant material channel, jointly aligned with RGB to enforce boundary consistency. Extensive experiments on the Waymo Open Dataset demonstrate that LR-SGS achieves superior reconstruction performance with fewer Gaussians and shorter training time. In particular, on Complex Lighting scenes, our method surpasses OmniRe by 1.18 dB PSNR.
RGBSQGrasp: Inferring Local Superquadric Primitives from Single RGB Image for Graspability-Aware Bin Picking
Mar 04, 2025

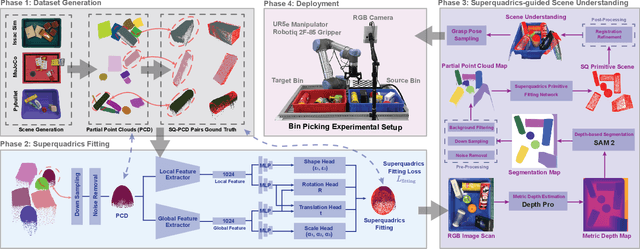

Bin picking is a challenging robotic task due to occlusions and physical constraints that limit visual information for object recognition and grasping. Existing approaches often rely on known CAD models or prior object geometries, restricting generalization to novel or unknown objects. Other methods directly regress grasp poses from RGB-D data without object priors, but the inherent noise in depth sensing and the lack of object understanding make grasp synthesis and evaluation more difficult. Superquadrics (SQ) offer a compact, interpretable shape representation that captures the physical and graspability understanding of objects. However, recovering them from limited viewpoints is challenging, as existing methods rely on multiple perspectives for near-complete point cloud reconstruction, limiting their effectiveness in bin-picking. To address these challenges, we propose \textbf{RGBSQGrasp}, a grasping framework that leverages superquadric shape primitives and foundation metric depth estimation models to infer grasp poses from a monocular RGB camera -- eliminating the need for depth sensors. Our framework integrates a universal, cross-platform dataset generation pipeline, a foundation model-based object point cloud estimation module, a global-local superquadric fitting network, and an SQ-guided grasp pose sampling module. By integrating these components, RGBSQGrasp reliably infers grasp poses through geometric reasoning, enhancing grasp stability and adaptability to unseen objects. Real-world robotic experiments demonstrate a 92\% grasp success rate, highlighting the effectiveness of RGBSQGrasp in packed bin-picking environments.
Visual-tactile sensing for Real-time liquid Volume Estimation in Grasping
Feb 23, 2022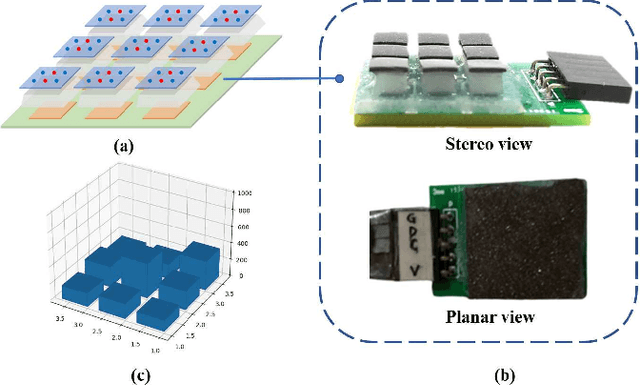
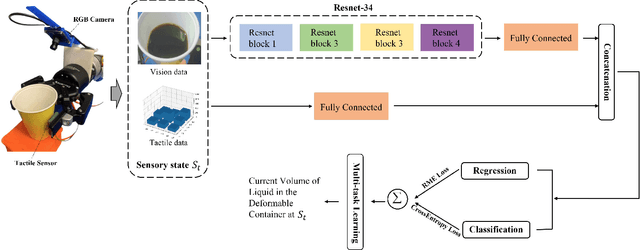

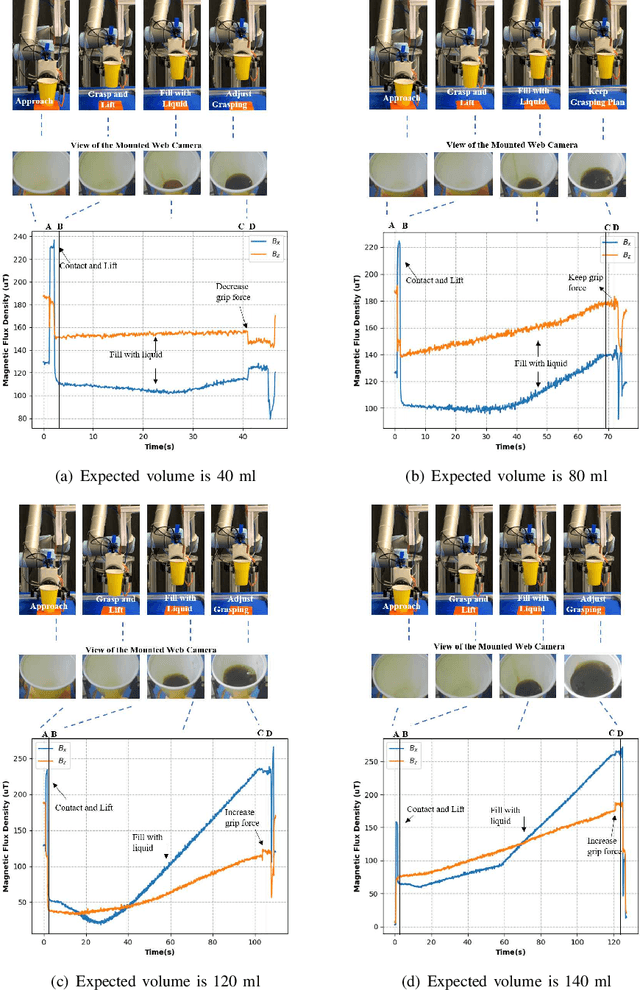
We propose a deep visuo-tactile model for realtime estimation of the liquid inside a deformable container in a proprioceptive way.We fuse two sensory modalities, i.e., the raw visual inputs from the RGB camera and the tactile cues from our specific tactile sensor without any extra sensor calibrations.The robotic system is well controlled and adjusted based on the estimation model in real time. The main contributions and novelties of our work are listed as follows: 1) Explore a proprioceptive way for liquid volume estimation by developing an end-to-end predictive model with multi-modal convolutional networks, which achieve a high precision with an error of around 2 ml in the experimental validation. 2) Propose a multi-task learning architecture which comprehensively considers the losses from both classification and regression tasks, and comparatively evaluate the performance of each variant on the collected data and actual robotic platform. 3) Utilize the proprioceptive robotic system to accurately serve and control the requested volume of liquid, which is continuously flowing into a deformable container in real time. 4) Adaptively adjust the grasping plan to achieve more stable grasping and manipulation according to the real-time liquid volume prediction.
G-VAE, a Geometric Convolutional VAE for ProteinStructure Generation
Jun 22, 2021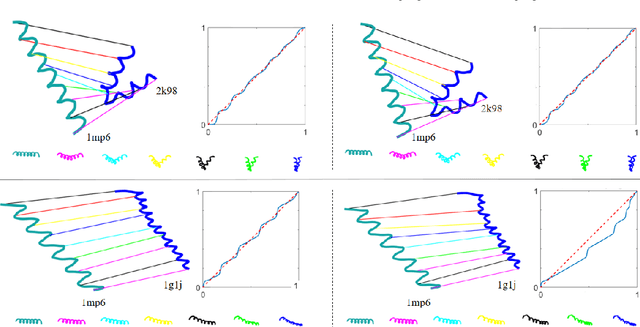
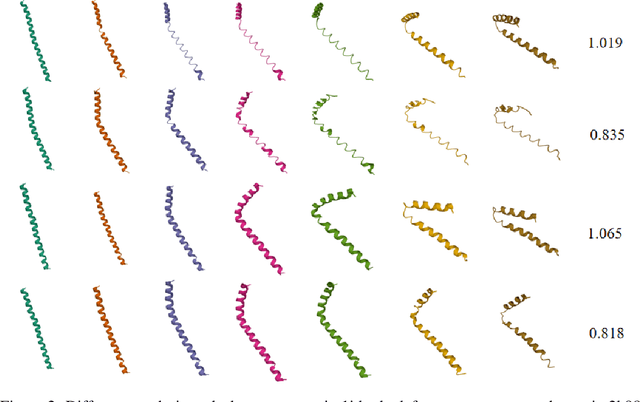
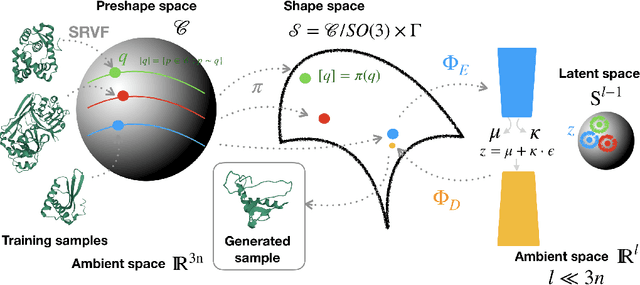
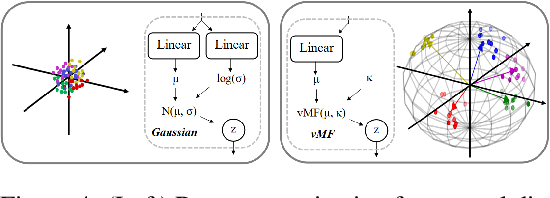
Analyzing the structure of proteins is a key part of understanding their functions and thus their role in biology at the molecular level. In addition, design new proteins in a methodical way is a major engineering challenge. In this work, we introduce a joint geometric-neural networks approach for comparing, deforming and generating 3D protein structures. Viewing protein structures as 3D open curves, we adopt the Square Root Velocity Function (SRVF) representation and leverage its suitable geometric properties along with Deep Residual Networks (ResNets) for a joint registration and comparison. Our ResNets handle better large protein deformations while being more computationally efficient. On top of the mathematical framework, we further design a Geometric Variational Auto-Encoder (G-VAE), that once trained, maps original, previously unseen structures, into a low-dimensional (latent) hyper-sphere. Motivated by the spherical structure of the pre-shape space, we naturally adopt the von Mises-Fisher (vMF) distribution to model our hidden variables. We test the effectiveness of our models by generating novel protein structures and predicting completions of corrupted protein structures. Experimental results show that our method is able to generate plausible structures, different from the structures in the training data.
Residual Networks as Flows of Velocity Fields for Diffeomorphic Time Series Alignment
Jun 22, 2021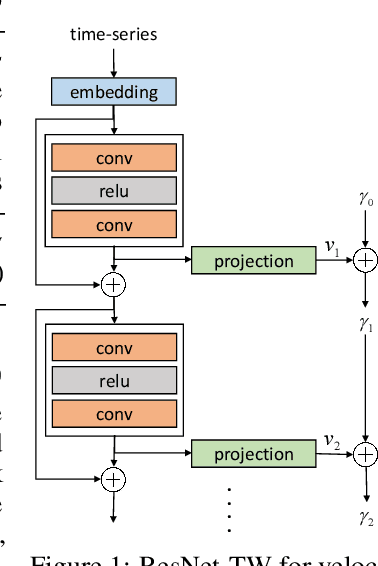

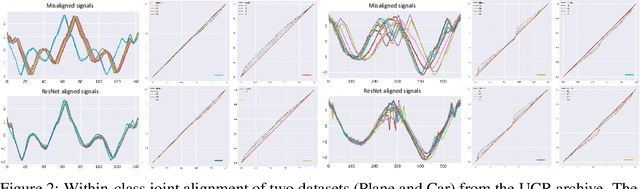
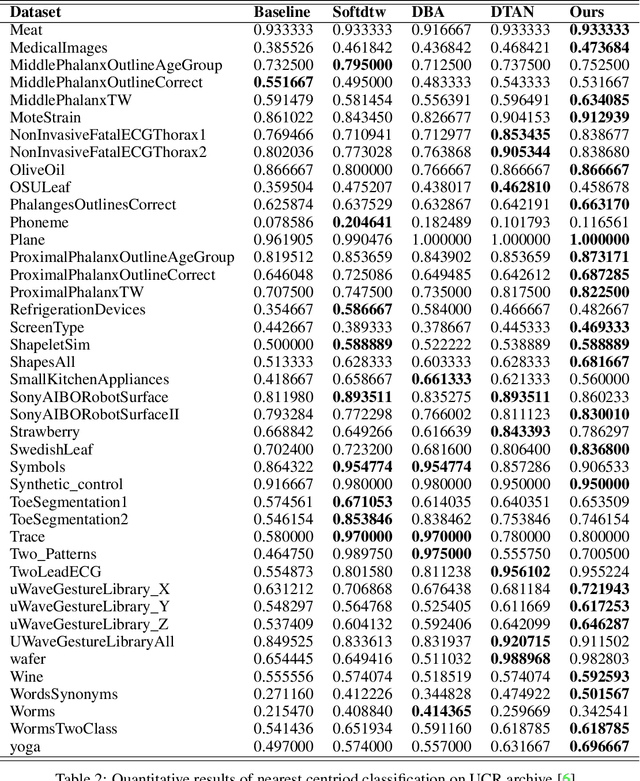
Non-linear (large) time warping is a challenging source of nuisance in time-series analysis. In this paper, we propose a novel diffeomorphic temporal transformer network for both pairwise and joint time-series alignment. Our ResNet-TW (Deep Residual Network for Time Warping) tackles the alignment problem by compositing a flow of incremental diffeomorphic mappings. Governed by the flow equation, our Residual Network (ResNet) builds smooth, fluid and regular flows of velocity fields and consequently generates smooth and invertible transformations (i.e. diffeomorphic warping functions). Inspired by the elegant Large Deformation Diffeomorphic Metric Mapping (LDDMM) framework, the final transformation is built by the flow of time-dependent vector fields which are none other than the building blocks of our Residual Network. The latter is naturally viewed as an Eulerian discretization schema of the flow equation (an ODE). Once trained, our ResNet-TW aligns unseen data by a single inexpensive forward pass. As we show in experiments on both univariate (84 datasets from UCR archive) and multivariate time-series (MSR Action-3D, Florence-3D and MSR Daily Activity), ResNet-TW achieves competitive performance in joint alignment and classification.
A LiDAR Assisted Control Module with High Precision in Parking Scenarios for Autonomous Driving Vehicle
May 02, 2021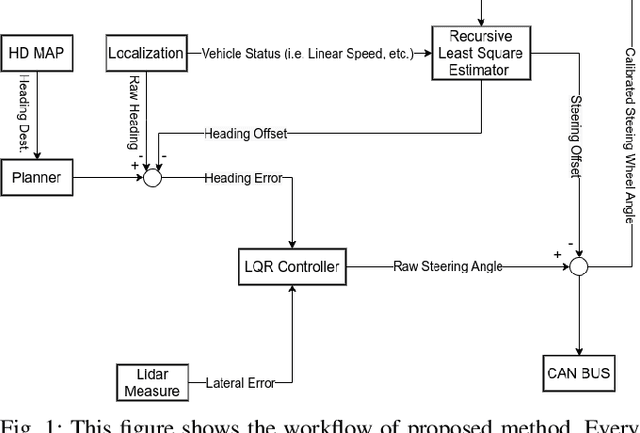
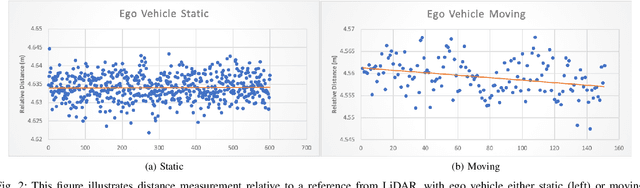
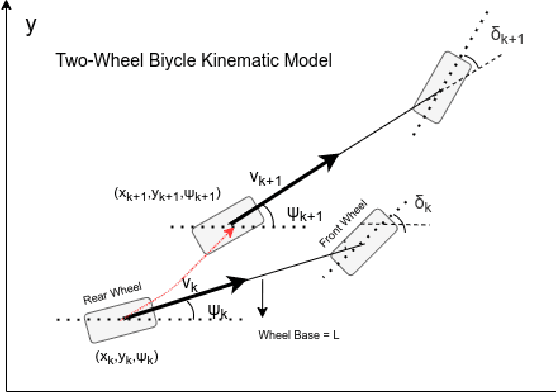
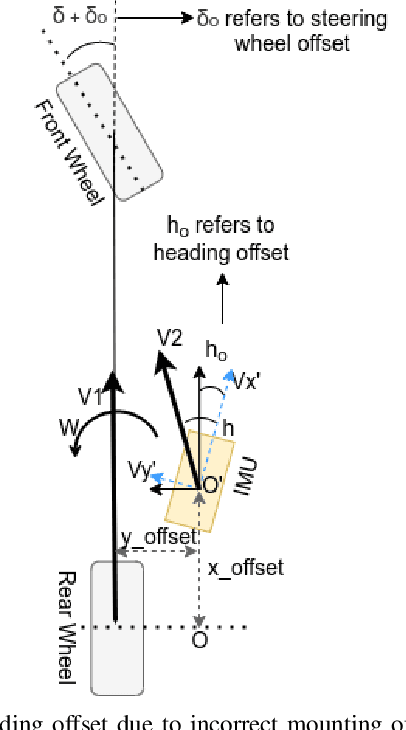
Autonomous driving has been quite promising in recent years. The public has seen Robotaxi delivered by Waymo, Baidu, Cruise, and so on. While autonomous driving vehicles certainly have a bright future, we have to admit that it is still a long way to go for products such as Robotaxi. On the other hand, in less complex scenarios autonomous driving may have the potentiality to reliably outperform humans. For example, humans are good at interactive tasks (while autonomous driving systems usually do not), but we are often incompetent for tasks with strict precision demands. In this paper, we introduce a real-world, industrial scenario of which human drivers are not capable. The task required the ego vehicle to keep a stationary lateral distance (i.e. 3? <= 5 centimeters) with respect to a reference. To address this challenge, we redesigned the control module from Baidu Apollo open-source autonomous driving system. A precise (3? <= 2 centimeters) Error Feedback System was first built to partly replace the localization module. Then we investigated the control module thoroughly and added a real-time calibration algorithm to gain extra precision. We also built a simulation to fine-tune the control parameters. After all those works, the results are encouraging, showing that an end-to-end lateral precision with 3? <= 5 centimeters has been achieved. Further, we show that the results not only outperformed original Apollo modules but also beat specially trained and highly experienced human test drivers.
Learning Multi-Granular Hypergraphs for Video-Based Person Re-Identification
Apr 30, 2021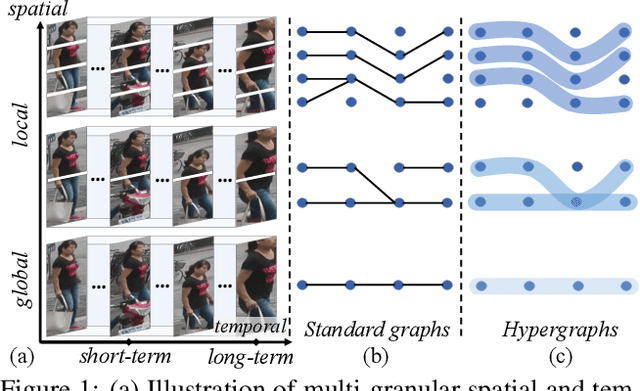
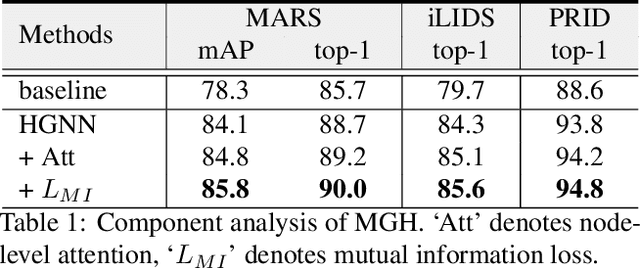
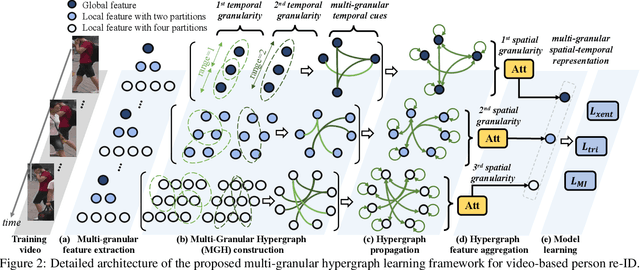
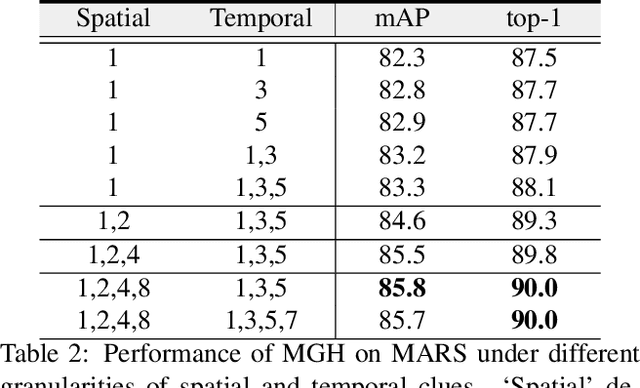
Video-based person re-identification (re-ID) is an important research topic in computer vision. The key to tackling the challenging task is to exploit both spatial and temporal clues in video sequences. In this work, we propose a novel graph-based framework, namely Multi-Granular Hypergraph (MGH), to pursue better representational capabilities by modeling spatiotemporal dependencies in terms of multiple granularities. Specifically, hypergraphs with different spatial granularities are constructed using various levels of part-based features across the video sequence. In each hypergraph, different temporal granularities are captured by hyperedges that connect a set of graph nodes (i.e., part-based features) across different temporal ranges. Two critical issues (misalignment and occlusion) are explicitly addressed by the proposed hypergraph propagation and feature aggregation schemes. Finally, we further enhance the overall video representation by learning more diversified graph-level representations of multiple granularities based on mutual information minimization. Extensive experiments on three widely adopted benchmarks clearly demonstrate the effectiveness of the proposed framework. Notably, 90.0% top-1 accuracy on MARS is achieved using MGH, outperforming the state-of-the-arts. Code is available at https://github.com/daodaofr/hypergraph_reid.
Learning Multi-Attention Context Graph for Group-Based Re-Identification
Apr 29, 2021

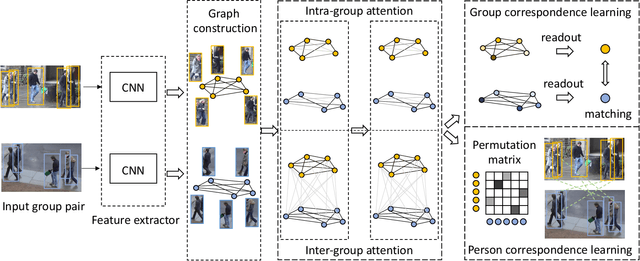

Learning to re-identify or retrieve a group of people across non-overlapped camera systems has important applications in video surveillance. However, most existing methods focus on (single) person re-identification (re-id), ignoring the fact that people often walk in groups in real scenarios. In this work, we take a step further and consider employing context information for identifying groups of people, i.e., group re-id. We propose a novel unified framework based on graph neural networks to simultaneously address the group-based re-id tasks, i.e., group re-id and group-aware person re-id. Specifically, we construct a context graph with group members as its nodes to exploit dependencies among different people. A multi-level attention mechanism is developed to formulate both intra-group and inter-group context, with an additional self-attention module for robust graph-level representations by attentively aggregating node-level features. The proposed model can be directly generalized to tackle group-aware person re-id using node-level representations. Meanwhile, to facilitate the deployment of deep learning models on these tasks, we build a new group re-id dataset that contains more than 3.8K images with 1.5K annotated groups, an order of magnitude larger than existing group re-id datasets. Extensive experiments on the novel dataset as well as three existing datasets clearly demonstrate the effectiveness of the proposed framework for both group-based re-id tasks. The code is available at https://github.com/daodaofr/group_reid.
Anchor-Free Person Search
Mar 22, 2021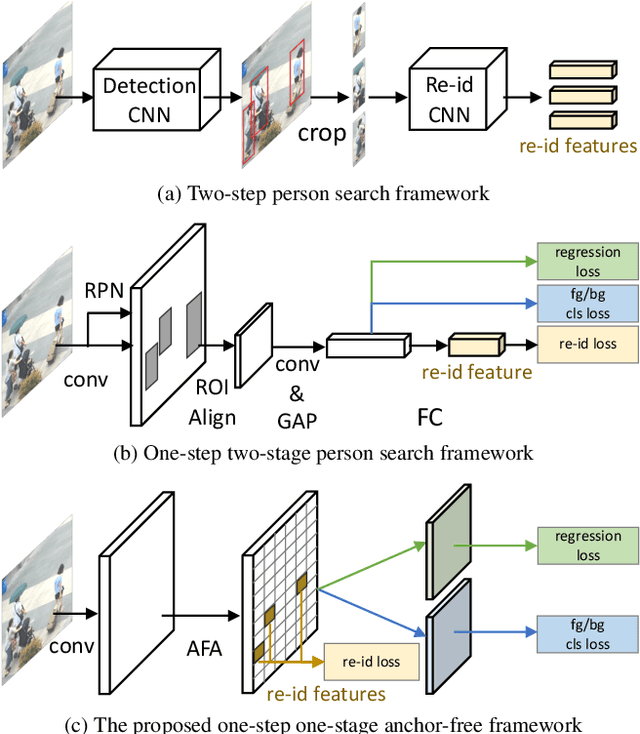
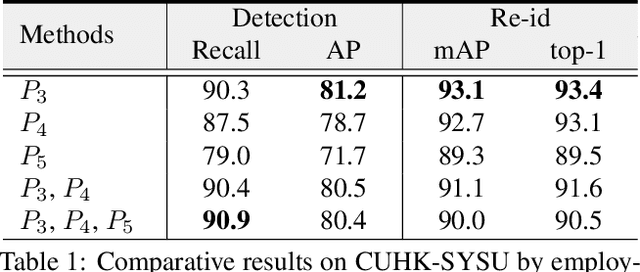
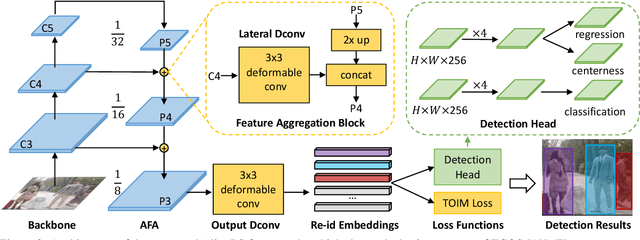
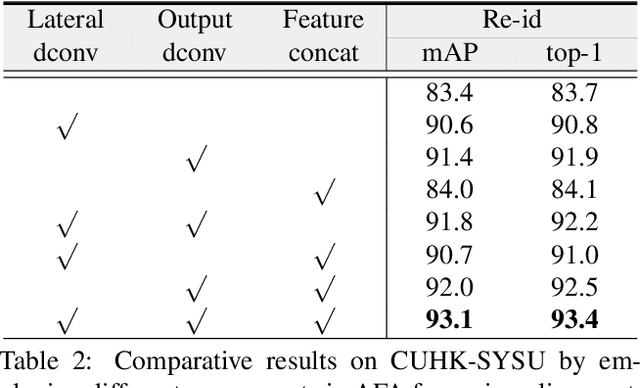
Person search aims to simultaneously localize and identify a query person from realistic, uncropped images, which can be regarded as the unified task of pedestrian detection and person re-identification (re-id). Most existing works employ two-stage detectors like Faster-RCNN, yielding encouraging accuracy but with high computational overhead. In this work, we present the Feature-Aligned Person Search Network (AlignPS), the first anchor-free framework to efficiently tackle this challenging task. AlignPS explicitly addresses the major challenges, which we summarize as the misalignment issues in different levels (i.e., scale, region, and task), when accommodating an anchor-free detector for this task. More specifically, we propose an aligned feature aggregation module to generate more discriminative and robust feature embeddings by following a "re-id first" principle. Such a simple design directly improves the baseline anchor-free model on CUHK-SYSU by more than 20% in mAP. Moreover, AlignPS outperforms state-of-the-art two-stage methods, with a higher speed. Code is available at https://github.com/daodaofr/AlignPS