 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual-tactile sensing for Real-time liquid Volume Estimation in Grasping
Paper and Code
Feb 23, 2022
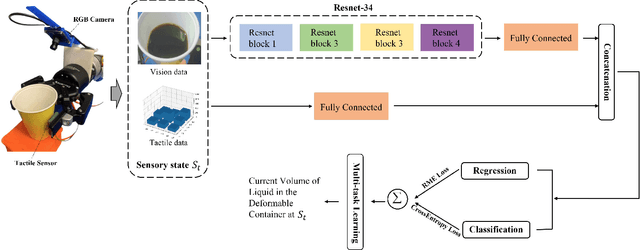

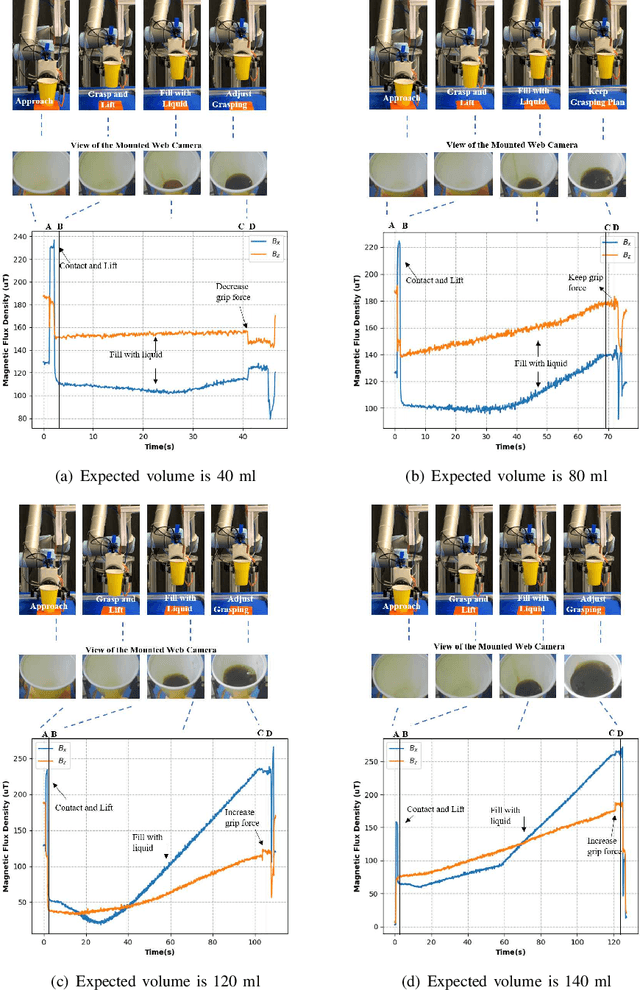
We propose a deep visuo-tactile model for realtime estimation of the liquid inside a deformable container in a proprioceptive way.We fuse two sensory modalities, i.e., the raw visual inputs from the RGB camera and the tactile cues from our specific tactile sensor without any extra sensor calibrations.The robotic system is well controlled and adjusted based on the estimation model in real time. The main contributions and novelties of our work are listed as follows: 1) Explore a proprioceptive way for liquid volume estimation by developing an end-to-end predictive model with multi-modal convolutional networks, which achieve a high precision with an error of around 2 ml in the experimental validation. 2) Propose a multi-task learning architecture which comprehensively considers the losses from both classification and regression tasks, and comparatively evaluate the performance of each variant on the collected data and actual robotic platform. 3) Utilize the proprioceptive robotic system to accurately serve and control the requested volume of liquid, which is continuously flowing into a deformable container in real time. 4) Adaptively adjust the grasping plan to achieve more stable grasping and manipulation according to the real-time liquid volume prediction.