 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShared Autonomy Assisted by Impedance-Driven Anisotropic Guidance Field
May 04, 2026Shared autonomy (SA) enables robots to infer human intent and assist in its achievement. While most research focuses on improving intent inference, it overlooks whether humans can understand the robot's intent in return. Without such mutual understanding, collaboration becomes less effective, degrading user experience and task performance. To address this gap, previous studies have explicitly conveyed the robot intent through additional interfaces, which remain unintuitive and limited in expressiveness. Inspired by impedance control, we propose Impedance-Driven Anisotropic Guidance Field Enhanced Shared Autonomy (IAGF-SA), a novel paradigm that extends SA with an embodied, physically-grounded communication channel. This channel adaptively modulates the robot's dynamic response to human input, enabling intuitive, continuous, physically-grounded robot intent communication while naturally guiding human actions. User studies across three scenarios and two teleoperation interfaces indicate that IAGF-SA improves task performance, human-robot agreement, and subjective experience, thus demonstrating its effectiveness in enhancing human-robot communication and collaboration.
Understanding Particles From Video: Property Estimation of Granular Materials via Visuo-Haptic Learning
Dec 03, 2024



Granular materials (GMs) are ubiquitous in daily life. Understanding their properties is also important, especially in agriculture and industry. However, existing works require dedicated measurement equipment and also need large human efforts to handle a large number of particles. In this paper, we introduce a method for estimating the relative values of particle size and density from the video of the interaction with GMs. It is trained on a visuo-haptic learning framework inspired by a contact model, which reveals the strong correlation between GM properties and the visual-haptic data during the probe-dragging in the GMs. After training, the network can map the visual modality well to the haptic signal and implicitly characterize the relative distribution of particle properties in its latent embeddings, as interpreted in that contact model. Therefore, we can analyze GM properties using the trained encoder, and only visual information is needed without extra sensory modalities and human efforts for labeling. The presented GM property estimator has been extensively validated via comparison and ablation experiments. The generalization capability has also been evaluated and a real-world application on the beach is also demonstrated. Experiment videos are available at \url{https://sites.google.com/view/gmwork/vhlearning} .
A Haptic-Based Proximity Sensing System for Buried Object in Granular Material
Nov 26, 2024



The proximity perception of objects in granular materials is significant, especially for applications like minesweeping. However, due to particles' opacity and complex properties, existing proximity sensors suffer from high costs from sophisticated hardware and high user-cost from unintuitive results. In this paper, we propose a simple yet effective proximity sensing system for underground stuff based on the haptic feedback of the sensor-granules interaction. We study and employ the unique characteristic of particles -- failure wedge zone, and combine the machine learning method -- Gaussian process regression, to identify the force signal changes induced by the proximity of objects, so as to achieve near-field perception. Furthermore, we design a novel trajectory to control the probe searching in granules for a wide range of perception. Also, our proximity sensing system can adaptively determine optimal parameters for robustness operation in different particles. Experiments demonstrate our system can perceive underground objects over 0.5 to 7 cm in advance among various materials.
Signage-Aware Exploration in Open World using Venue Maps
Oct 14, 2024
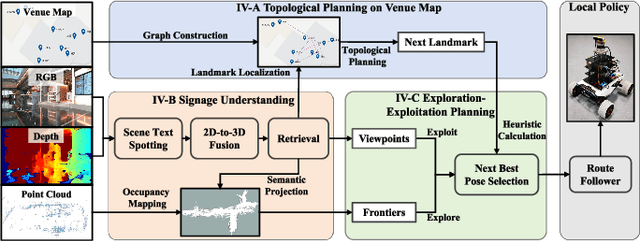
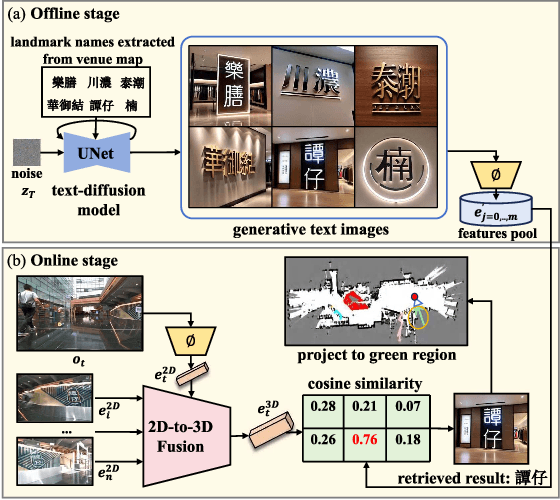
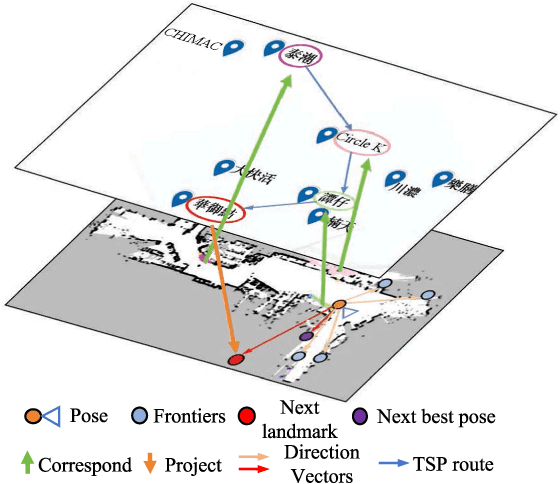
Current exploration methods struggle to search for shops in unknown open-world environments due to a lack of prior knowledge and text recognition capabilities. Venue maps offer valuable information that can aid exploration planning by correlating scene signage with map data. However, the arbitrary shapes and styles of the text on signage, along with multi-view inconsistencies, pose significant challenges for accurate recognition by robots. Additionally, the discrepancies between real-world environments and venue maps hinder the incorporation of text information into planners. This paper introduces a novel signage-aware exploration system to address these challenges, enabling the robot to utilize venue maps effectively. We propose a signage understanding method that accurately detects and recognizes the text on signage using a diffusion-based text instance retrieval method combined with a 2D-to-3D semantic fusion strategy. Furthermore, we design a venue map-guided exploration-exploitation planner that balances exploration in unknown regions using a directional heuristic derived from venue maps with exploitation to get close and adjust orientation for better recognition. Experiments in large-scale shopping malls demonstrate our method's superior signage recognition accuracy and coverage efficiency, outperforming state-of-the-art scene text spotting methods and traditional exploration methods.
Language-Augmented Symbolic Planner for Open-World Task Planning
Jul 13, 2024



Enabling robotic agents to perform complex long-horizon tasks has been a long-standing goal in robotics and artificial intelligence (AI). Despite the potential shown by large language models (LLMs), their planning capabilities remain limited to short-horizon tasks and they are unable to replace the symbolic planning approach. Symbolic planners, on the other hand, may encounter execution errors due to their common assumption of complete domain knowledge which is hard to manually prepare for an open-world setting. In this paper, we introduce a Language-Augmented Symbolic Planner (LASP) that integrates pre-trained LLMs to enable conventional symbolic planners to operate in an open-world environment where only incomplete knowledge of action preconditions, objects, and properties is initially available. In case of execution errors, LASP can utilize the LLM to diagnose the cause of the error based on the observation and interact with the environment to incrementally build up its knowledge base necessary for accomplishing the given tasks. Experiments demonstrate that LASP is proficient in solving planning problems in the open-world setting, performing well even in situations where there are multiple gaps in the knowledge.
GRAINS: Proximity Sensing of Objects in Granular Materials
Jul 18, 2023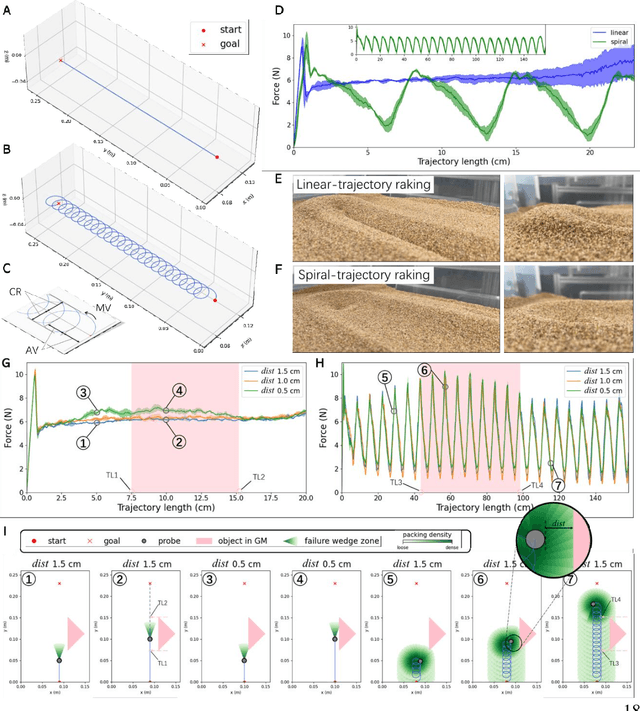
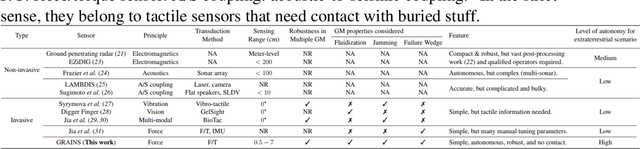
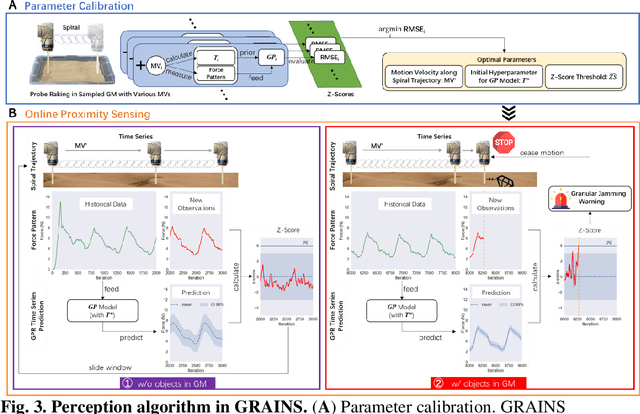
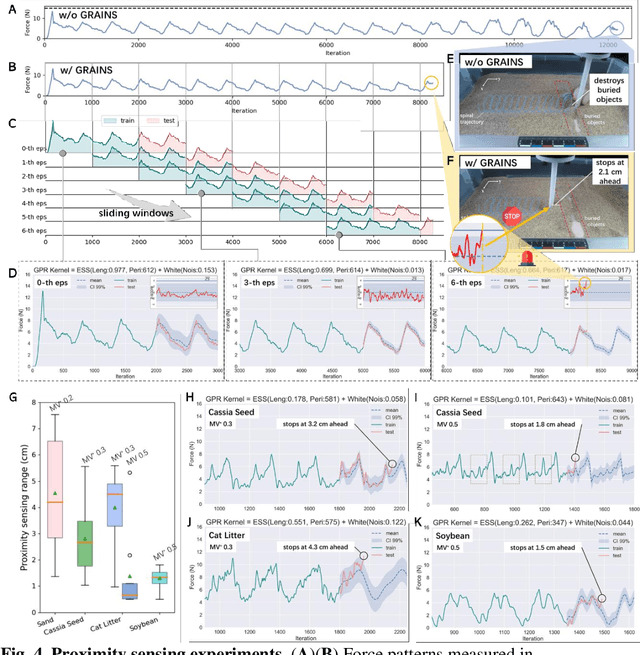
Proximity sensing detects an object's presence without contact. However, research has rarely explored proximity sensing in granular materials (GM) due to GM's lack of visual and complex properties. In this paper, we propose a granular-material-embedded autonomous proximity sensing system (GRAINS) based on three granular phenomena (fluidization, jamming, and failure wedge zone). GRAINS can automatically sense buried objects beneath GM in real-time manner (at least ~20 hertz) and perceive them 0.5 ~ 7 centimeters ahead in different granules without the use of vision or touch. We introduce a new spiral trajectory for the probe raking in GM, combining linear and circular motions, inspired by a common granular fluidization technique. Based on the observation of force-raising when granular jamming occurs in the failure wedge zone in front of the probe during its raking, we employ Gaussian process regression to constantly learn and predict the force patterns and detect the force anomaly resulting from granular jamming to identify the proximity sensing of buried objects. Finally, we apply GRAINS to a Bayesian-optimization-algorithm-guided exploration strategy to successfully localize underground objects and outline their distribution using proximity sensing without contact or digging. This work offers a simple yet reliable method with potential for safe operation in building habitation infrastructure on an alien planet without human intervention.
Learn to Predict How Humans Manipulate Large-sized Objects from Interactive Motions
Jun 25, 2022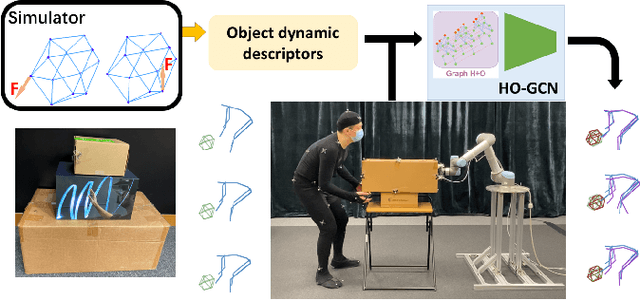

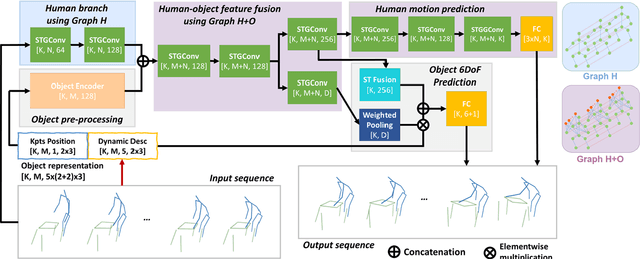
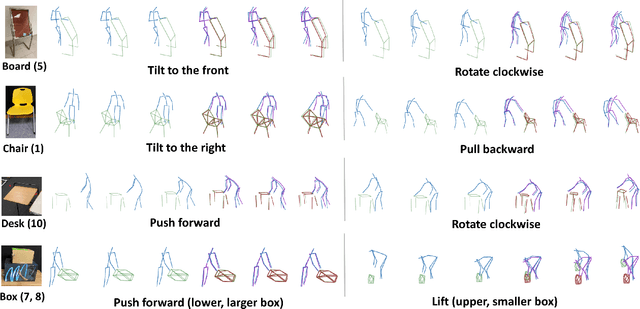
Understanding human intentions during interactions has been a long-lasting theme, that has applications in human-robot interaction, virtual reality and surveillance. In this study, we focus on full-body human interactions with large-sized daily objects and aim to predict the future states of objects and humans given a sequential observation of human-object interaction. As there is no such dataset dedicated to full-body human interactions with large-sized daily objects, we collected a large-scale dataset containing thousands of interactions for training and evaluation purposes. We also observe that an object's intrinsic physical properties are useful for the object motion prediction, and thus design a set of object dynamic descriptors to encode such intrinsic properties. We treat the object dynamic descriptors as a new modality and propose a graph neural network, HO-GCN, to fuse motion data and dynamic descriptors for the prediction task. We show the proposed network that consumes dynamic descriptors can achieve state-of-the-art prediction results and help the network better generalize to unseen objects. We also demonstrate the predicted results are useful for human-robot collaborations.
Visual-tactile sensing for Real-time liquid Volume Estimation in Grasping
Feb 23, 2022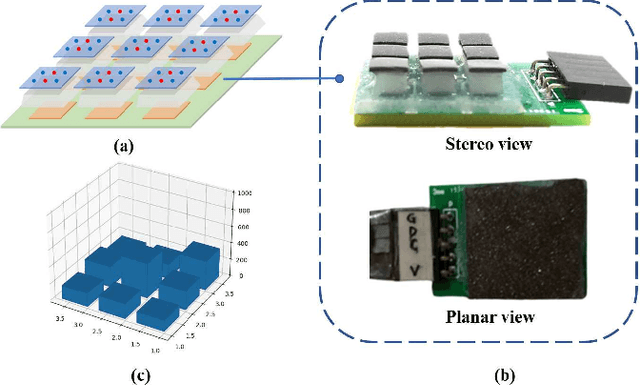
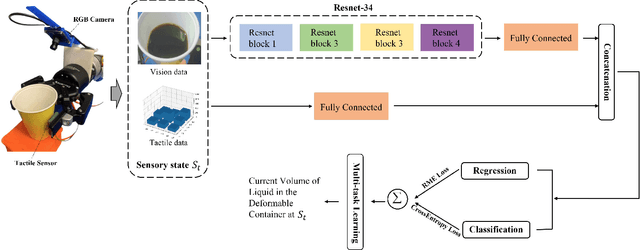

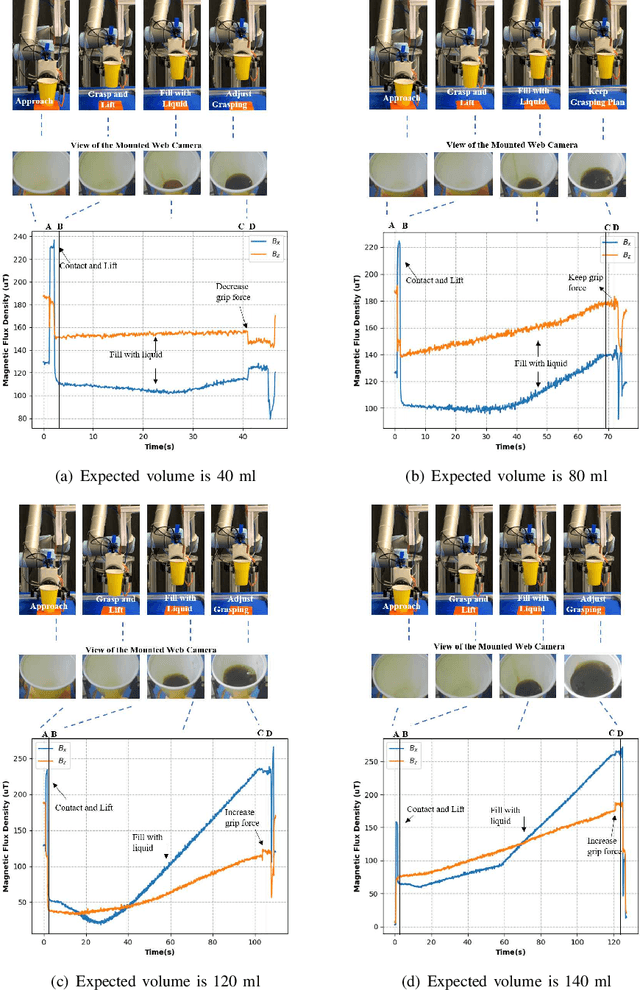
We propose a deep visuo-tactile model for realtime estimation of the liquid inside a deformable container in a proprioceptive way.We fuse two sensory modalities, i.e., the raw visual inputs from the RGB camera and the tactile cues from our specific tactile sensor without any extra sensor calibrations.The robotic system is well controlled and adjusted based on the estimation model in real time. The main contributions and novelties of our work are listed as follows: 1) Explore a proprioceptive way for liquid volume estimation by developing an end-to-end predictive model with multi-modal convolutional networks, which achieve a high precision with an error of around 2 ml in the experimental validation. 2) Propose a multi-task learning architecture which comprehensively considers the losses from both classification and regression tasks, and comparatively evaluate the performance of each variant on the collected data and actual robotic platform. 3) Utilize the proprioceptive robotic system to accurately serve and control the requested volume of liquid, which is continuously flowing into a deformable container in real time. 4) Adaptively adjust the grasping plan to achieve more stable grasping and manipulation according to the real-time liquid volume prediction.