 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn to Predict How Humans Manipulate Large-sized Objects from Interactive Motions
Jun 25, 2022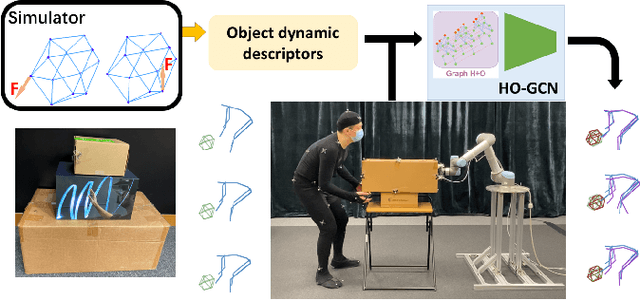

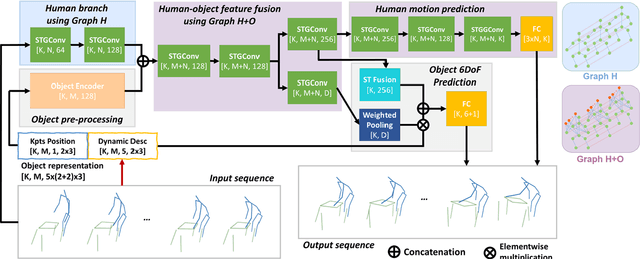
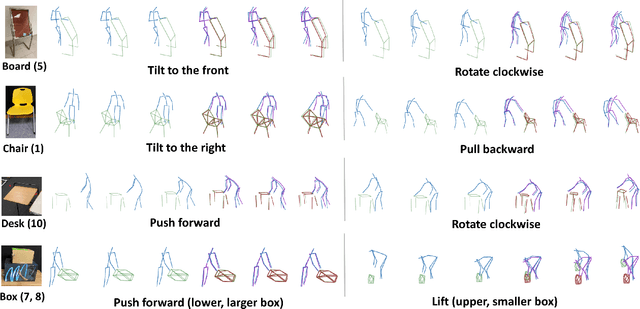
Understanding human intentions during interactions has been a long-lasting theme, that has applications in human-robot interaction, virtual reality and surveillance. In this study, we focus on full-body human interactions with large-sized daily objects and aim to predict the future states of objects and humans given a sequential observation of human-object interaction. As there is no such dataset dedicated to full-body human interactions with large-sized daily objects, we collected a large-scale dataset containing thousands of interactions for training and evaluation purposes. We also observe that an object's intrinsic physical properties are useful for the object motion prediction, and thus design a set of object dynamic descriptors to encode such intrinsic properties. We treat the object dynamic descriptors as a new modality and propose a graph neural network, HO-GCN, to fuse motion data and dynamic descriptors for the prediction task. We show the proposed network that consumes dynamic descriptors can achieve state-of-the-art prediction results and help the network better generalize to unseen objects. We also demonstrate the predicted results are useful for human-robot collaborations.
Point2Skeleton: Learning Skeletal Representations from Point Clouds
Dec 01, 2020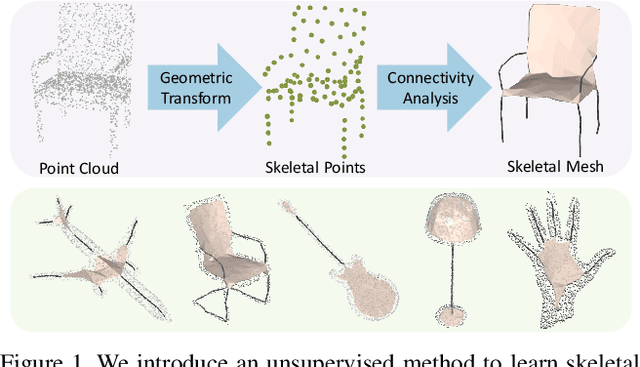
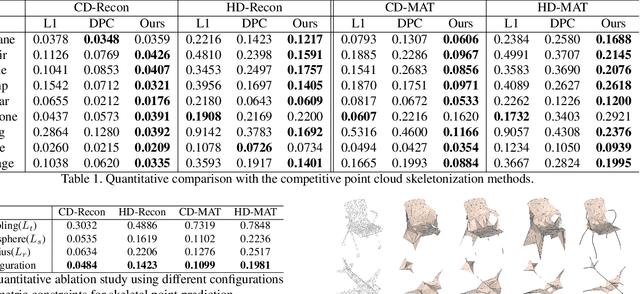

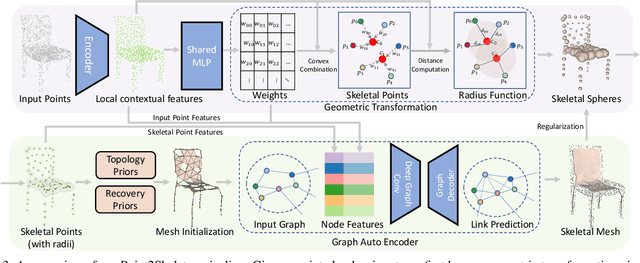
We introduce Point2Skeleton, an unsupervised method to learn skeletal representations from point clouds. Existing skeletonization methods are limited to tubular shapes and the stringent requirement of watertight input, while our method aims to produce more generalized skeletal representations for complex structures and handle point clouds. Our key idea is to use the insights of the medial axis transform (MAT) to capture the intrinsic geometric and topological natures of the original input points. We first predict a set of skeletal points by learning a geometric transformation, and then analyze the connectivity of the skeletal points to form skeletal mesh structures. Extensive evaluations and comparisons show our method has superior performance and robustness. The learned skeletal representation will benefit several unsupervised tasks for point clouds, such as surface reconstruction and segmentation.