 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn to Predict How Humans Manipulate Large-sized Objects from Interactive Motions
Jun 25, 2022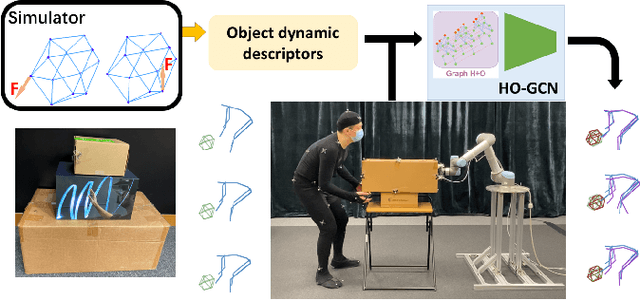

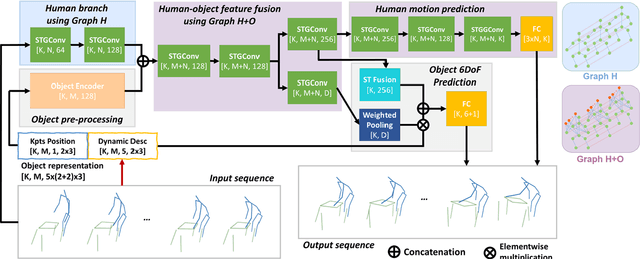
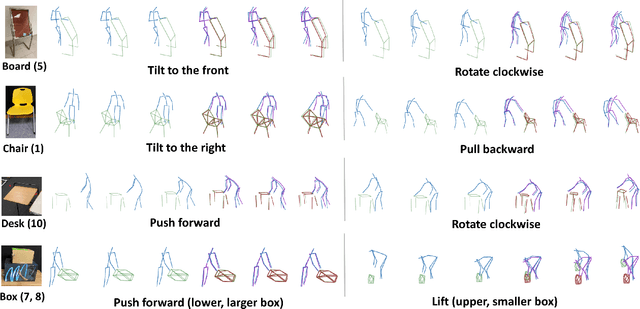
Understanding human intentions during interactions has been a long-lasting theme, that has applications in human-robot interaction, virtual reality and surveillance. In this study, we focus on full-body human interactions with large-sized daily objects and aim to predict the future states of objects and humans given a sequential observation of human-object interaction. As there is no such dataset dedicated to full-body human interactions with large-sized daily objects, we collected a large-scale dataset containing thousands of interactions for training and evaluation purposes. We also observe that an object's intrinsic physical properties are useful for the object motion prediction, and thus design a set of object dynamic descriptors to encode such intrinsic properties. We treat the object dynamic descriptors as a new modality and propose a graph neural network, HO-GCN, to fuse motion data and dynamic descriptors for the prediction task. We show the proposed network that consumes dynamic descriptors can achieve state-of-the-art prediction results and help the network better generalize to unseen objects. We also demonstrate the predicted results are useful for human-robot collaborations.