 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Diffusion-Based Quantitatively Controllable Image Generation via Matrix-Form EDM and Adaptive Vicinal Training
Feb 02, 2026Continuous Conditional Diffusion Model (CCDM) is a diffusion-based framework designed to generate high-quality images conditioned on continuous regression labels. Although CCDM has demonstrated clear advantages over prior approaches across a range of datasets, it still exhibits notable limitations and has recently been surpassed by a GAN-based method, namely CcGAN-AVAR. These limitations mainly arise from its reliance on an outdated diffusion framework and its low sampling efficiency due to long sampling trajectories. To address these issues, we propose an improved CCDM framework, termed iCCDM, which incorporates the more advanced \textit{Elucidated Diffusion Model} (EDM) framework with substantial modifications to improve both generation quality and sampling efficiency. Specifically, iCCDM introduces a novel matrix-form EDM formulation together with an adaptive vicinal training strategy. Extensive experiments on four benchmark datasets, spanning image resolutions from $64\times64$ to $256\times256$, demonstrate that iCCDM consistently outperforms existing methods, including state-of-the-art large-scale text-to-image diffusion models (e.g., Stable Diffusion 3, FLUX.1, and Qwen-Image), achieving higher generation quality while significantly reducing sampling cost.
ZeroPS: High-quality Cross-modal Knowledge Transfer for Zero-Shot 3D Part Segmentation
Nov 24, 2023



Recently, many 2D pretrained foundational models have demonstrated impressive zero-shot prediction capabilities. In this work, we design a novel pipeline for zero-shot 3D part segmentation, called ZeroPS. It high-quality transfers knowledge from 2D pretrained foundational models to 3D point clouds. The main idea of our approach is to explore the natural relationship between multi-view correspondences and the prompt mechanism of foundational models and build bridges on it. Our pipeline consists of two components: 1) a self-extension component that extends 2D groups from a single viewpoint to spatial global-level 3D groups; 2) a multi-modal labeling component that introduces a two-dimensional checking mechanism to vote each 2D predicted bounding box to the best matching 3D part, and a Class Non-highest Vote Penalty function to refine the Vote Matrix. Additionally, a merging algorithm is included to merge part-level 3D groups. Extensive evaluation of three zero-shot segmentation tasks on PartnetE datasets, achieving state-of-the-art results with significant improvements (+19.6%, +5.2% and +4.9%, respectively) over existing methods. Our proposed approach does not need any training, fine-tuning or learnable parameters. It is hardly affected by domain shift. The code will be released.
Model2Scene: Learning 3D Scene Representation via Contrastive Language-CAD Models Pre-training
Sep 29, 2023Current successful methods of 3D scene perception rely on the large-scale annotated point cloud, which is tedious and expensive to acquire. In this paper, we propose Model2Scene, a novel paradigm that learns free 3D scene representation from Computer-Aided Design (CAD) models and languages. The main challenges are the domain gaps between the CAD models and the real scene's objects, including model-to-scene (from a single model to the scene) and synthetic-to-real (from synthetic model to real scene's object). To handle the above challenges, Model2Scene first simulates a crowded scene by mixing data-augmented CAD models. Next, we propose a novel feature regularization operation, termed Deep Convex-hull Regularization (DCR), to project point features into a unified convex hull space, reducing the domain gap. Ultimately, we impose contrastive loss on language embedding and the point features of CAD models to pre-train the 3D network. Extensive experiments verify the learned 3D scene representation is beneficial for various downstream tasks, including label-free 3D object salient detection, label-efficient 3D scene perception and zero-shot 3D semantic segmentation. Notably, Model2Scene yields impressive label-free 3D object salient detection with an average mAP of 46.08\% and 55.49\% on the ScanNet and S3DIS datasets, respectively. The code will be publicly available.
Towards Label-free Scene Understanding by Vision Foundation Models
Jun 06, 2023



Vision foundation models such as Contrastive Vision-Language Pre-training (CLIP) and Segment Anything (SAM) have demonstrated impressive zero-shot performance on image classification and segmentation tasks. However, the incorporation of CLIP and SAM for label-free scene understanding has yet to be explored. In this paper, we investigate the potential of vision foundation models in enabling networks to comprehend 2D and 3D worlds without labelled data. The primary challenge lies in effectively supervising networks under extremely noisy pseudo labels, which are generated by CLIP and further exacerbated during the propagation from the 2D to the 3D domain. To tackle these challenges, we propose a novel Cross-modality Noisy Supervision (CNS) method that leverages the strengths of CLIP and SAM to supervise 2D and 3D networks simultaneously. In particular, we introduce a prediction consistency regularization to co-train 2D and 3D networks, then further impose the networks' latent space consistency using the SAM's robust feature representation. Experiments conducted on diverse indoor and outdoor datasets demonstrate the superior performance of our method in understanding 2D and 3D open environments. Our 2D and 3D network achieves label-free semantic segmentation with 28.4% and 33.5% mIoU on ScanNet, improving 4.7% and 7.9%, respectively. And for nuScenes dataset, our performance is 26.8% with an improvement of 6%. Code will be released (https://github.com/runnanchen/Label-Free-Scene-Understanding).
Zero-shot Point Cloud Segmentation by Transferring Geometric Primitives
Oct 18, 2022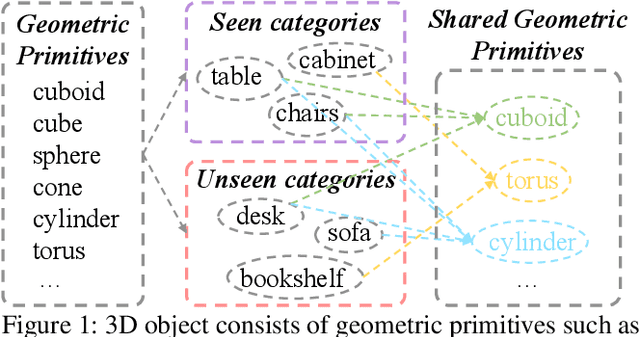
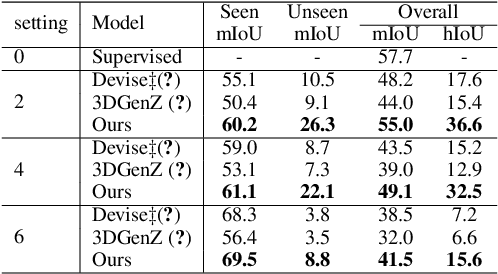

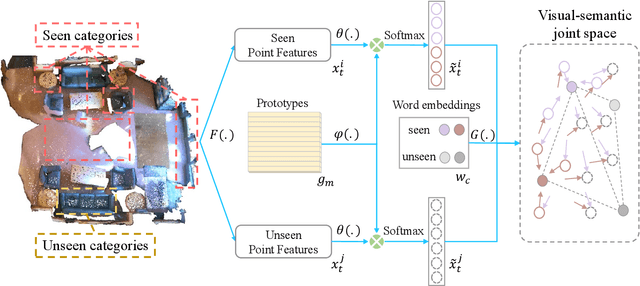
We investigate transductive zero-shot point cloud semantic segmentation in this paper, where unseen class labels are unavailable during training. Actually, the 3D geometric elements are essential cues to reason the 3D object type. If two categories share similar geometric primitives, they also have similar semantic representations. Based on this consideration, we propose a novel framework to learn the geometric primitives shared in seen and unseen categories' objects, where the learned geometric primitives are served for transferring knowledge from seen to unseen categories. Specifically, a group of learnable prototypes automatically encode geometric primitives via back-propagation. Then, the point visual representation is formulated as the similarity vector of its feature to the prototypes, which implies semantic cues for both seen and unseen categories. Besides, considering a 3D object composed of multiple geometric primitives, we formulate the semantic representation as a mixture-distributed embedding for the fine-grained match of visual representation. In the end, to effectively learn the geometric primitives and alleviate the misclassification issue, we propose a novel unknown-aware infoNCE loss to align the visual and semantic representation. As a result, guided by semantic representations, the network recognizes the novel object represented with geometric primitives. Extensive experiments show that our method significantly outperforms other state-of-the-art methods in the harmonic mean-intersection-over-union (hIoU), with the improvement of 17.8%, 30.4% and 9.2% on S3DIS, ScanNet and SemanticKITTI datasets, respectively. Codes will be released.
Self-Supervised Image Representation Learning with Geometric Set Consistency
Mar 29, 2022
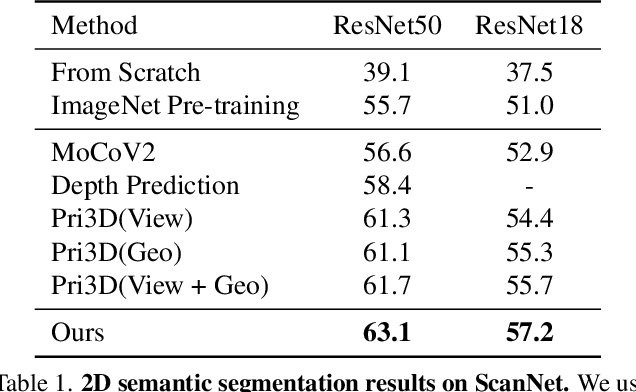
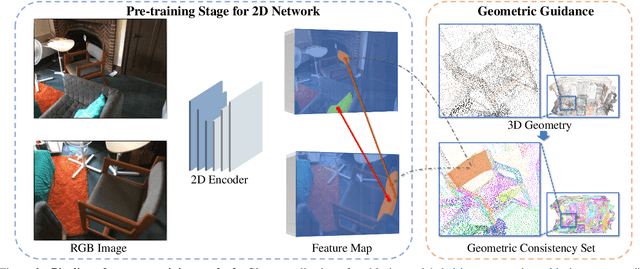
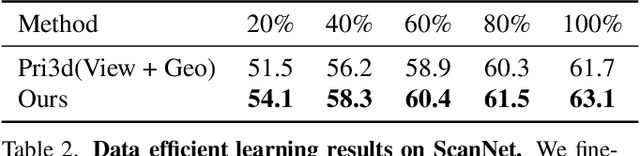
We propose a method for self-supervised image representation learning under the guidance of 3D geometric consistency. Our intuition is that 3D geometric consistency priors such as smooth regions and surface discontinuities may imply consistent semantics or object boundaries, and can act as strong cues to guide the learning of 2D image representations without semantic labels. Specifically, we introduce 3D geometric consistency into a contrastive learning framework to enforce the feature consistency within image views. We propose to use geometric consistency sets as constraints and adapt the InfoNCE loss accordingly. We show that our learned image representations are general. By fine-tuning our pre-trained representations for various 2D image-based downstream tasks, including semantic segmentation, object detection, and instance segmentation on real-world indoor scene datasets, we achieve superior performance compared with state-of-the-art methods.
Towards 3D Scene Understanding by Referring Synthetic Models
Mar 20, 2022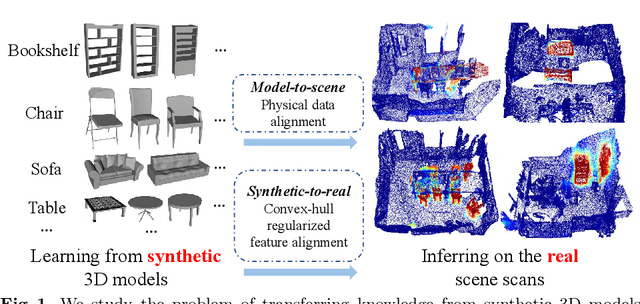
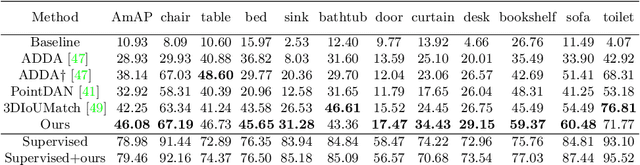

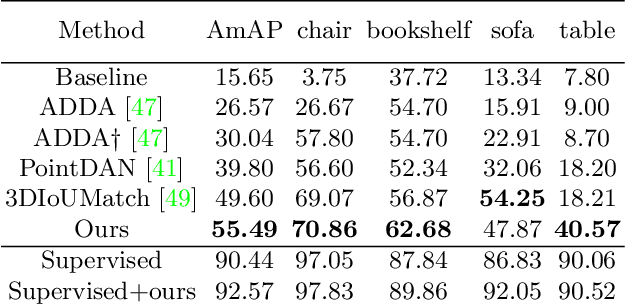
Promising performance has been achieved for visual perception on the point cloud. However, the current methods typically rely on labour-extensive annotations on the scene scans. In this paper, we explore how synthetic models alleviate the real scene annotation burden, i.e., taking the labelled 3D synthetic models as reference for supervision, the neural network aims to recognize specific categories of objects on a real scene scan (without scene annotation for supervision). The problem studies how to transfer knowledge from synthetic 3D models to real 3D scenes and is named Referring Transfer Learning (RTL). The main challenge is solving the model-to-scene (from a single model to the scene) and synthetic-to-real (from synthetic model to real scene's object) gap between the synthetic model and the real scene. To this end, we propose a simple yet effective framework to perform two alignment operations. First, physical data alignment aims to make the synthetic models cover the diversity of the scene's objects with data processing techniques. Then a novel \textbf{convex-hull regularized feature alignment} introduces learnable prototypes to project the point features of both synthetic models and real scenes to a unified feature space, which alleviates the domain gap. These operations ease the model-to-scene and synthetic-to-real difficulty for a network to recognize the target objects on a real unseen scene. Experiments show that our method achieves the average mAP of 46.08\% and 55.49\% on the ScanNet and S3DIS datasets by learning the synthetic models from the ModelNet dataset. Code will be publicly available.
PR-Net: Preference Reasoning for Personalized Video Highlight Detection
Sep 04, 2021
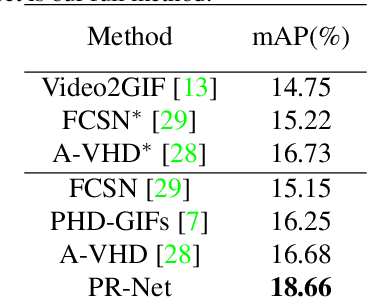
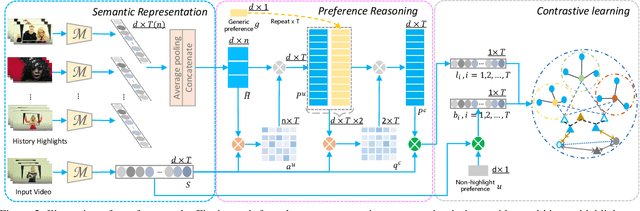
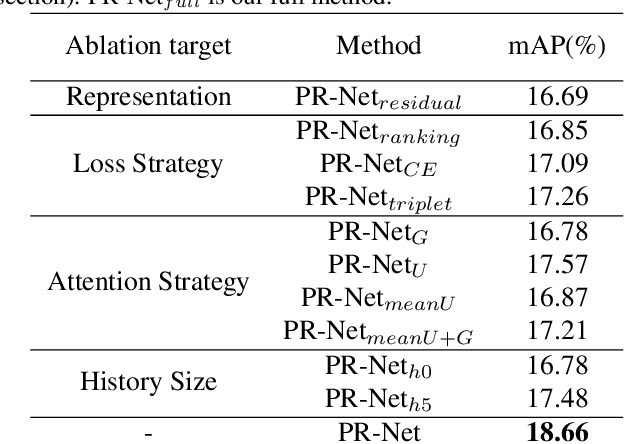
Personalized video highlight detection aims to shorten a long video to interesting moments according to a user's preference, which has recently raised the community's attention. Current methods regard the user's history as holistic information to predict the user's preference but negating the inherent diversity of the user's interests, resulting in vague preference representation. In this paper, we propose a simple yet efficient preference reasoning framework (PR-Net) to explicitly take the diverse interests into account for frame-level highlight prediction. Specifically, distinct user-specific preferences for each input query frame are produced, presented as the similarity weighted sum of history highlights to the corresponding query frame. Next, distinct comprehensive preferences are formed by the user-specific preferences and a learnable generic preference for more overall highlight measurement. Lastly, the degree of highlight and non-highlight for each query frame is calculated as semantic similarity to its comprehensive and non-highlight preferences, respectively. Besides, to alleviate the ambiguity due to the incomplete annotation, a new bi-directional contrastive loss is proposed to ensure a compact and differentiable metric space. In this way, our method significantly outperforms state-of-the-art methods with a relative improvement of 12% in mean accuracy precision.
Distributed Attention for Grounded Image Captioning
Aug 22, 2021
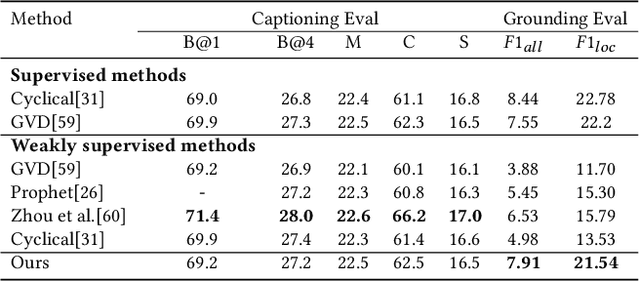

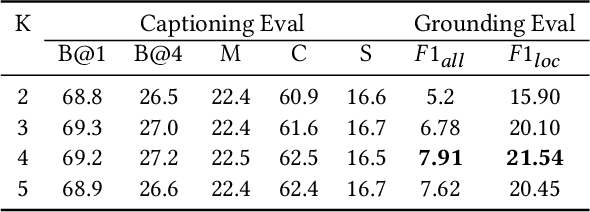
We study the problem of weakly supervised grounded image captioning. That is, given an image, the goal is to automatically generate a sentence describing the context of the image with each noun word grounded to the corresponding region in the image. This task is challenging due to the lack of explicit fine-grained region word alignments as supervision. Previous weakly supervised methods mainly explore various kinds of regularization schemes to improve attention accuracy. However, their performances are still far from the fully supervised ones. One main issue that has been ignored is that the attention for generating visually groundable words may only focus on the most discriminate parts and can not cover the whole object. To this end, we propose a simple yet effective method to alleviate the issue, termed as partial grounding problem in our paper. Specifically, we design a distributed attention mechanism to enforce the network to aggregate information from multiple spatially different regions with consistent semantics while generating the words. Therefore, the union of the focused region proposals should form a visual region that encloses the object of interest completely. Extensive experiments have demonstrated the superiority of our proposed method compared with the state-of-the-arts.
Structure-Aware Long Short-Term Memory Network for 3D Cephalometric Landmark Detection
Jul 21, 2021



Detecting 3D landmarks on cone-beam computed tomography (CBCT) is crucial to assessing and quantifying the anatomical abnormalities in 3D cephalometric analysis. However, the current methods are time-consuming and suffer from large biases in landmark localization, leading to unreliable diagnosis results. In this work, we propose a novel Structure-Aware Long Short-Term Memory framework (SA-LSTM) for efficient and accurate 3D landmark detection. To reduce the computational burden, SA-LSTM is designed in two stages. It first locates the coarse landmarks via heatmap regression on a down-sampled CBCT volume and then progressively refines landmarks by attentive offset regression using high-resolution cropped patches. To boost accuracy, SA-LSTM captures global-local dependence among the cropping patches via self-attention. Specifically, a graph attention module implicitly encodes the landmark's global structure to rationalize the predicted position. Furthermore, a novel attention-gated module recursively filters irrelevant local features and maintains high-confident local predictions for aggregating the final result. Experiments show that our method significantly outperforms state-of-the-art methods in terms of efficiency and accuracy on an in-house dataset and a public dataset, achieving 1.64 mm and 2.37 mm average errors, respectively, and using only 0.5 seconds for inferring the whole CBCT volume of resolution 768*768*576. Moreover, all predicted landmarks are within 8 mm error, which is vital for acceptable cephalometric analysis.