 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Point Cloud Segmentation by Transferring Geometric Primitives
Paper and Code
Oct 18, 2022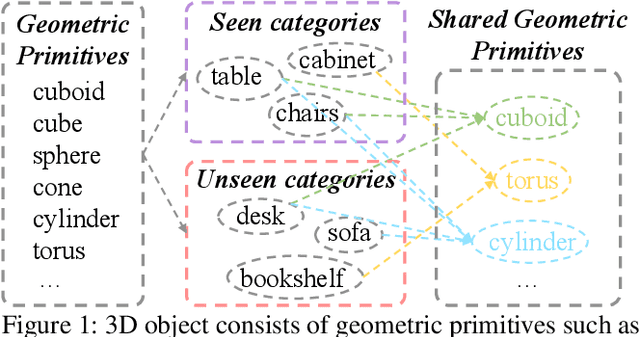
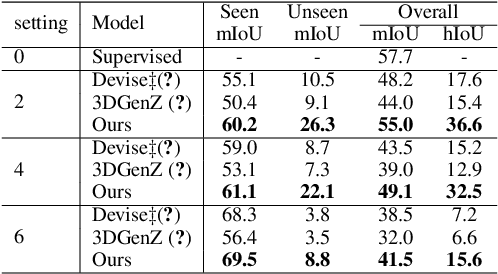

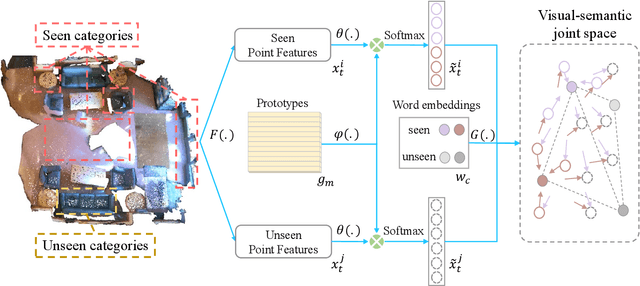
We investigate transductive zero-shot point cloud semantic segmentation in this paper, where unseen class labels are unavailable during training. Actually, the 3D geometric elements are essential cues to reason the 3D object type. If two categories share similar geometric primitives, they also have similar semantic representations. Based on this consideration, we propose a novel framework to learn the geometric primitives shared in seen and unseen categories' objects, where the learned geometric primitives are served for transferring knowledge from seen to unseen categories. Specifically, a group of learnable prototypes automatically encode geometric primitives via back-propagation. Then, the point visual representation is formulated as the similarity vector of its feature to the prototypes, which implies semantic cues for both seen and unseen categories. Besides, considering a 3D object composed of multiple geometric primitives, we formulate the semantic representation as a mixture-distributed embedding for the fine-grained match of visual representation. In the end, to effectively learn the geometric primitives and alleviate the misclassification issue, we propose a novel unknown-aware infoNCE loss to align the visual and semantic representation. As a result, guided by semantic representations, the network recognizes the novel object represented with geometric primitives. Extensive experiments show that our method significantly outperforms other state-of-the-art methods in the harmonic mean-intersection-over-union (hIoU), with the improvement of 17.8%, 30.4% and 9.2% on S3DIS, ScanNet and SemanticKITTI datasets, respectively. Codes will be released.