 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeqTR: A Simple yet Universal Network for Visual Grounding
Mar 30, 2022
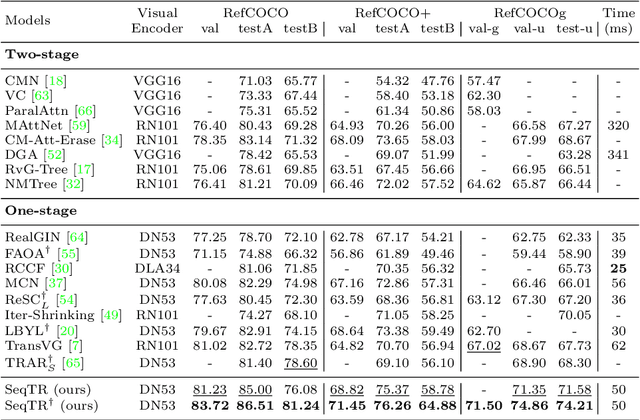
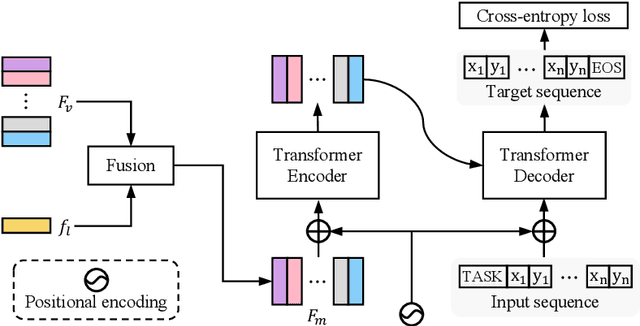
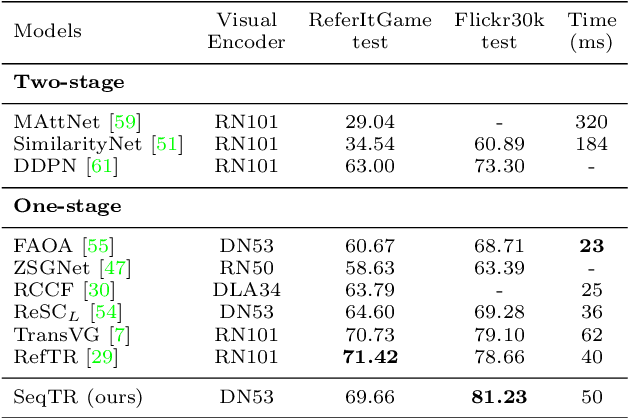
In this paper, we propose a simple yet universal network termed SeqTR for visual grounding tasks, e.g., phrase localization, referring expression comprehension (REC) and segmentation (RES). The canonical paradigms for visual grounding often require substantial expertise in designing network architectures and loss functions, making them hard to generalize across tasks. To simplify and unify the modeling, we cast visual grounding as a point prediction problem conditioned on image and text inputs, where either the bounding box or binary mask is represented as a sequence of discrete coordinate tokens. Under this paradigm, visual grounding tasks are unified in our SeqTR network without task-specific branches or heads, e.g., the convolutional mask decoder for RES, which greatly reduces the complexity of multi-task modeling. In addition, SeqTR also shares the same optimization objective for all tasks with a simple cross-entropy loss, further reducing the complexity of deploying hand-crafted loss functions. Experiments on five benchmark datasets demonstrate that the proposed SeqTR outperforms (or is on par with) the existing state-of-the-arts, proving that a simple yet universal approach for visual grounding is indeed feasible.
SIOD: Single Instance Annotated Per Category Per Image for Object Detection
Mar 30, 2022
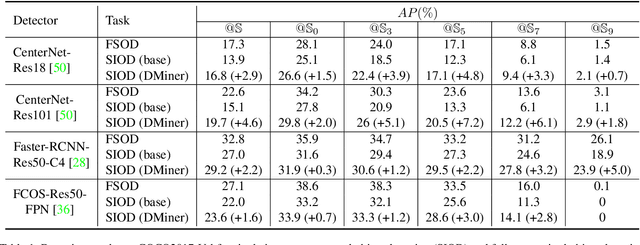
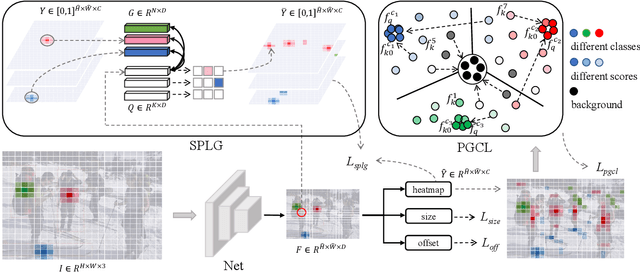

Object detection under imperfect data receives great attention recently. Weakly supervised object detection (WSOD) suffers from severe localization issues due to the lack of instance-level annotation, while semi-supervised object detection (SSOD) remains challenging led by the inter-image discrepancy between labeled and unlabeled data. In this study, we propose the Single Instance annotated Object Detection (SIOD), requiring only one instance annotation for each existing category in an image. Degraded from inter-task (WSOD) or inter-image (SSOD) discrepancies to the intra-image discrepancy, SIOD provides more reliable and rich prior knowledge for mining the rest of unlabeled instances and trades off the annotation cost and performance. Under the SIOD setting, we propose a simple yet effective framework, termed Dual-Mining (DMiner), which consists of a Similarity-based Pseudo Label Generating module (SPLG) and a Pixel-level Group Contrastive Learning module (PGCL). SPLG firstly mines latent instances from feature representation space to alleviate the annotation missing problem. To avoid being misled by inaccurate pseudo labels, we propose PGCL to boost the tolerance to false pseudo labels. Extensive experiments on MS COCO verify the feasibility of the SIOD setting and the superiority of the proposed method, which obtains consistent and significant improvements compared to baseline methods and achieves comparable results with fully supervised object detection (FSOD) methods with only 40% instances annotated.
Expanding Low-Density Latent Regions for Open-Set Object Detection
Mar 28, 2022



Modern object detectors have achieved impressive progress under the close-set setup. However, open-set object detection (OSOD) remains challenging since objects of unknown categories are often misclassified to existing known classes. In this work, we propose to identify unknown objects by separating high/low-density regions in the latent space, based on the consensus that unknown objects are usually distributed in low-density latent regions. As traditional threshold-based methods only maintain limited low-density regions, which cannot cover all unknown objects, we present a novel Open-set Detector (OpenDet) with expanded low-density regions. To this aim, we equip OpenDet with two learners, Contrastive Feature Learner (CFL) and Unknown Probability Learner (UPL). CFL performs instance-level contrastive learning to encourage compact features of known classes, leaving more low-density regions for unknown classes; UPL optimizes unknown probability based on the uncertainty of predictions, which further divides more low-density regions around the cluster of known classes. Thus, unknown objects in low-density regions can be easily identified with the learned unknown probability. Extensive experiments demonstrate that our method can significantly improve the OSOD performance, e.g., OpenDet reduces the Absolute Open-Set Errors by 25%-35% on six OSOD benchmarks. Code is available at: https://github.com/csuhan/opendet2.
Mitigating the Mutual Error Amplification for Semi-Supervised Object Detection
Jan 26, 2022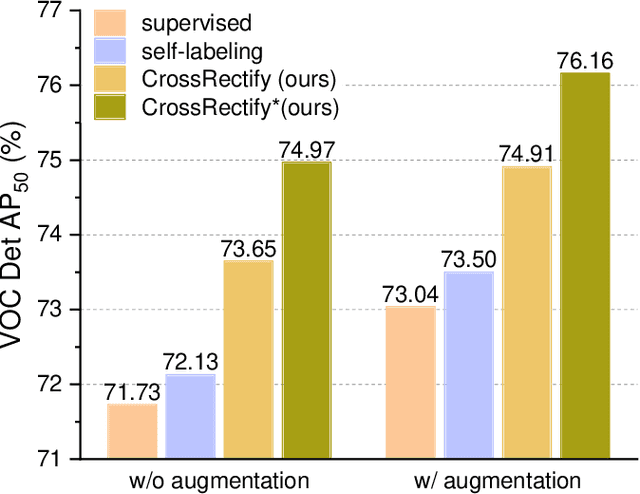
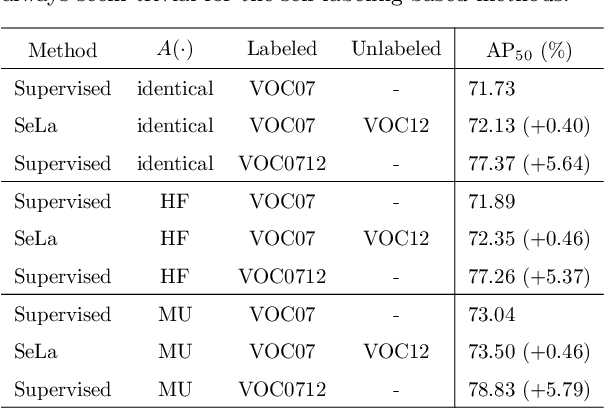
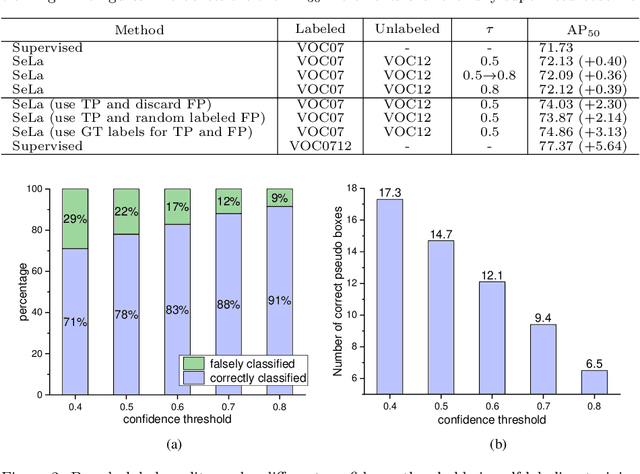
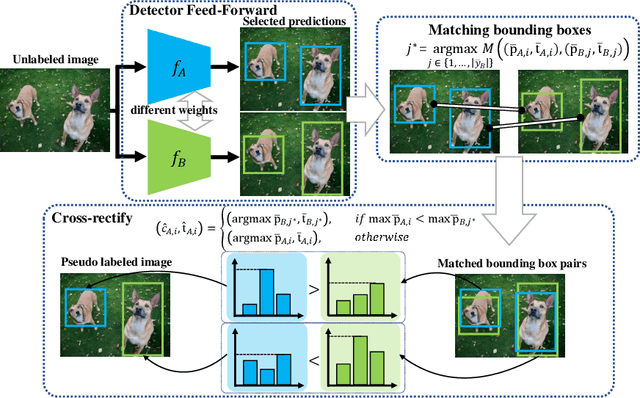
Semi-supervised object detection (SSOD) has achieved substantial progress in recent years. However, it is observed that the performances of self-labeling SSOD methods remain limited. Based on our experimental analysis, we reveal that the reason behind such phenomenon lies in the mutual error amplification between the pseudo labels and the trained detector. In this study, we propose a Cross Teaching (CT) method, aiming to mitigate the mutual error amplification by introducing a rectification mechanism of pseudo labels. CT simultaneously trains multiple detectors with an identical structure but different parameter initialization. In contrast to existing mutual teaching methods that directly treat predictions from other detectors as pseudo labels, we propose the Label Rectification Module (LRM), where the bounding boxes predicted by one detector are rectified by using the corresponding boxes predicted by all other detectors with higher confidence scores. In this way, CT can enhance the pseudo label quality compared with self-labeling and existing mutual teaching methods, and reasonably mitigate the mutual error amplification. Over two popular detector structures, i.e., SSD300 and Faster-RCNN-FPN, the proposed CT method obtains consistent improvements and outperforms the state-of-the-art SSOD methods by 2.2% absolute mAP improvements on the Pascal VOC and MS-COCO benchmarks. The code is available at github.com/machengcheng2016/CrossTeaching-SSOD.
Distributed Attention for Grounded Image Captioning
Aug 22, 2021
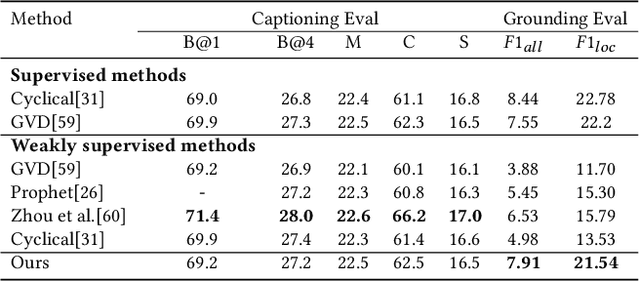

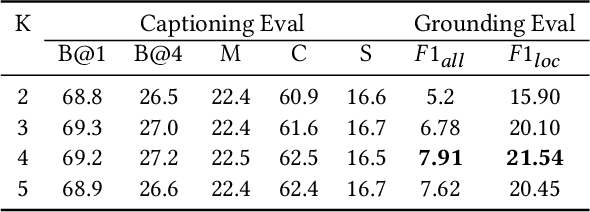
We study the problem of weakly supervised grounded image captioning. That is, given an image, the goal is to automatically generate a sentence describing the context of the image with each noun word grounded to the corresponding region in the image. This task is challenging due to the lack of explicit fine-grained region word alignments as supervision. Previous weakly supervised methods mainly explore various kinds of regularization schemes to improve attention accuracy. However, their performances are still far from the fully supervised ones. One main issue that has been ignored is that the attention for generating visually groundable words may only focus on the most discriminate parts and can not cover the whole object. To this end, we propose a simple yet effective method to alleviate the issue, termed as partial grounding problem in our paper. Specifically, we design a distributed attention mechanism to enforce the network to aggregate information from multiple spatially different regions with consistent semantics while generating the words. Therefore, the union of the focused region proposals should form a visual region that encloses the object of interest completely. Extensive experiments have demonstrated the superiority of our proposed method compared with the state-of-the-arts.
StyTr^2: Unbiased Image Style Transfer with Transformers
Jun 08, 2021
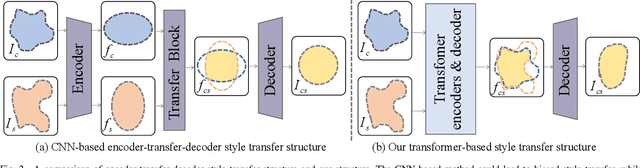


The goal of image style transfer is to render an image with artistic features guided by a style reference while maintaining the original content. Due to the locality and spatial invariance in CNNs, it is difficult to extract and maintain the global information of input images. Therefore, traditional neural style transfer methods are usually biased and content leak can be observed by running several times of the style transfer process with the same reference style image. To address this critical issue, we take long-range dependencies of input images into account for unbiased style transfer by proposing a transformer-based approach, namely StyTr^2. In contrast with visual transformers for other vision tasks, our StyTr^2 contains two different transformer encoders to generate domain-specific sequences for content and style, respectively. Following the encoders, a multi-layer transformer decoder is adopted to stylize the content sequence according to the style sequence. In addition, we analyze the deficiency of existing positional encoding methods and propose the content-aware positional encoding (CAPE) which is scale-invariant and more suitable for image style transfer task. Qualitative and quantitative experiments demonstrate the effectiveness of the proposed StyTr^2 compared to state-of-the-art CNN-based and flow-based approaches.
Unveiling the Potential of Structure Preserving for Weakly Supervised Object Localization
Mar 30, 2021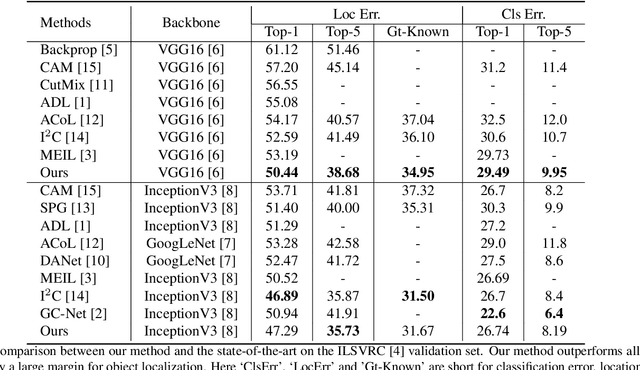

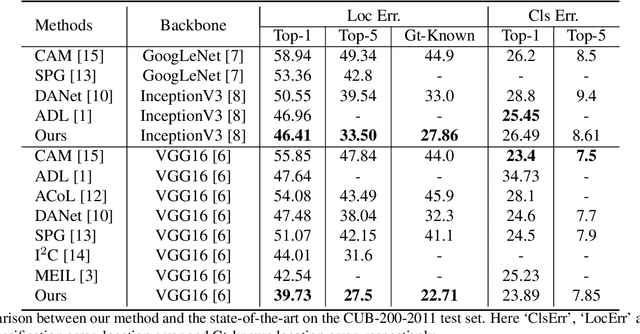
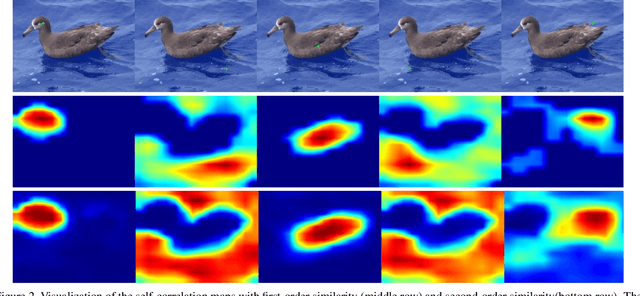
Weakly supervised object localization(WSOL) remains an open problem given the deficiency of finding object extent information using a classification network. Although prior works struggled to localize objects through various spatial regularization strategies, we argue that how to extract object structural information from the trained classification network is neglected. In this paper, we propose a two-stage approach, termed structure-preserving activation (SPA), toward fully leveraging the structure information incorporated in convolutional features for WSOL. First, a restricted activation module (RAM) is designed to alleviate the structure-missing issue caused by the classification network on the basis of the observation that the unbounded classification map and global average pooling layer drive the network to focus only on object parts. Second, we designed a post-process approach, termed self-correlation map generating (SCG) module to obtain structure-preserving localization maps on the basis of the activation maps acquired from the first stage. Specifically, we utilize the high-order self-correlation (HSC) to extract the inherent structural information retained in the learned model and then aggregate HSC of multiple points for precise object localization. Extensive experiments on two publicly available benchmarks including CUB-200-2011 and ILSVRC show that the proposed SPA achieves substantial and consistent performance gains compared with baseline approaches.Code and models are available at https://github.com/Panxjia/SPA_CVPR2021
TS-CAM: Token Semantic Coupled Attention Map for Weakly Supervised Object Localization
Mar 27, 2021


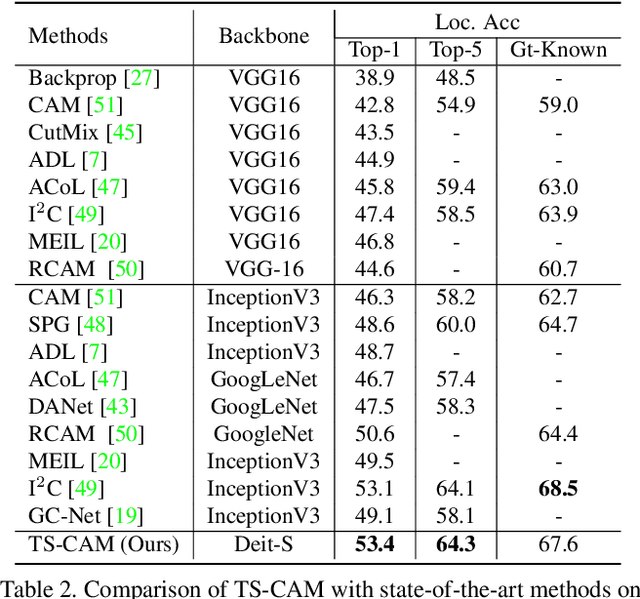
Weakly supervised object localization (WSOL) is a challenging problem when given image category labels but requires to learn object localization models. Optimizing a convolutional neural network (CNN) for classification tends to activate local discriminative regions while ignoring complete object extent, causing the partial activation issue. In this paper, we argue that partial activation is caused by the intrinsic characteristics of CNN, where the convolution operations produce local receptive fields and experience difficulty to capture long-range feature dependency among pixels. We introduce the token semantic coupled attention map (TS-CAM) to take full advantage of the self-attention mechanism in visual transformer for long-range dependency extraction. TS-CAM first splits an image into a sequence of patch tokens for spatial embedding, which produce attention maps of long-range visual dependency to avoid partial activation. TS-CAM then re-allocates category-related semantics for patch tokens, enabling each of them to be aware of object categories. TS-CAM finally couples the patch tokens with the semantic-agnostic attention map to achieve semantic-aware localization. Experiments on the ILSVRC/CUB-200-2011 datasets show that TS-CAM outperforms its CNN-CAM counterparts by 7.1%/27.1% for WSOL, achieving state-of-the-art performance.
Dynamic Refinement Network for Oriented and Densely Packed Object Detection
Jun 10, 2020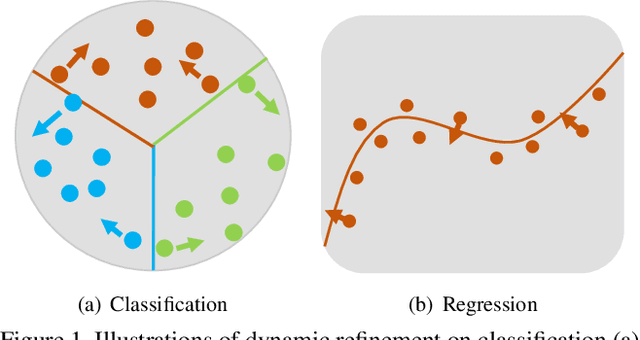

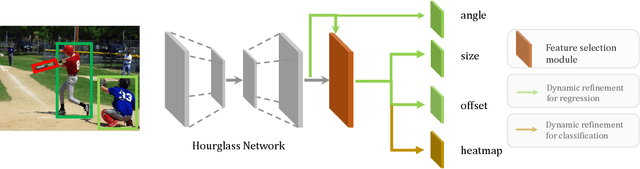

Object detection has achieved remarkable progress in the past decade. However, the detection of oriented and densely packed objects remains challenging because of following inherent reasons: (1) receptive fields of neurons are all axis-aligned and of the same shape, whereas objects are usually of diverse shapes and align along various directions; (2) detection models are typically trained with generic knowledge and may not generalize well to handle specific objects at test time; (3) the limited dataset hinders the development on this task. To resolve the first two issues, we present a dynamic refinement network that consists of two novel components, i.e., a feature selection module (FSM) and a dynamic refinement head (DRH). Our FSM enables neurons to adjust receptive fields in accordance with the shapes and orientations of target objects, whereas the DRH empowers our model to refine the prediction dynamically in an object-aware manner. To address the limited availability of related benchmarks, we collect an extensive and fully annotated dataset, namely, SKU110K-R, which is relabeled with oriented bounding boxes based on SKU110K. We perform quantitative evaluations on several publicly available benchmarks including DOTA, HRSC2016, SKU110K, and our own SKU110K-R dataset. Experimental results show that our method achieves consistent and substantial gains compared with baseline approaches. The code and dataset are available at https://github.com/Anymake/DRN_CVPR2020.